Why Windows Server 2012 R2: Reducing the Storage Cost for your VDI Deployments with VHD De-duplication for VDI
With storage needs in your organizations growing exponentially over the last few years and into the future there are plenty of things you may done in the past to help keep the cost down. Chances are you bought some kind of fancy SAN, that had all the bells and whistles to help storage work efficiently. I am willing to bet one of the features your SAN has is data de-duplication.
Windows Server 2012
With Windows Server 2012 we introduced built-in data de-duplication on a per-volume basis. You can save a tremendous amount in storage costs with this powerful addition. Thisde-duplication feature uses data broken into chunks and eliminates duplicates while adding pointers and using advanced mechanisms to provide for and prevent potential data loss. The de-duplication feature also uses a data aging system to ensure that only data that is resident on the volume for greater than 4 days (4 is the default and is adjustable based on your own situation) is de-duplicated to prevent the de-duplication of data that is constantly changing. If you want to take a look at a fantastic example take a look at post from a previous series which shows a de-deplicaiton from 240GB to 7GB:
31 Days of Our Favorite Things- From 240GB to 7 GB De-duplication with Veeam and Windows Server 2012
Windows Server 2012 R2
In Windows Server 2012 R2 we improved this feature even more. In Windows Server 2012 R2, we now support live data de-duplication on VHD’s for VDI. This means that data de-duplication can now be performed on open VHD/VHDX files on remote VDI storage with CSV volume support. Remote VHD/VHDX storage de-duplication allows for increased VDI storage density significantly reducing VDI storage costs, and enabling faster read/write of optimized files and advanced caching of duplicated data.
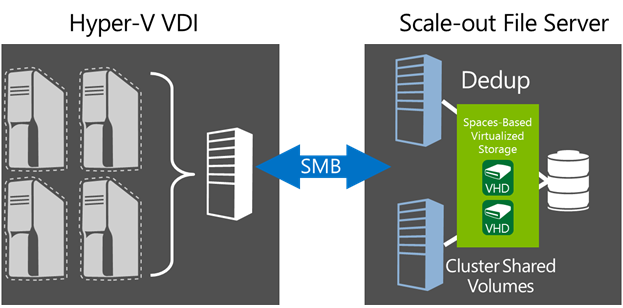
What’s the big deal?
We will start with the easy one, you will now save space and the rates for VDI deployments can range as high as 95% savings. This allows for deployments of SSD based volumes for VDI, leveraging all the improved IO characteristics while mitigating their low capacity. Additionally, due to the fact that Data De-duplication consolidates files, more efficient caching mechanisms are possible. This results in improving the IO characteristics of the storage subsystem for some types of operations. So not only does de-duplication save money, it can make things go faster.
Configuring De-Duplication for VHD’s in VDI
Of course the biggest part of this configuration is going to be getting VDI up to speed in your datacenter. Then after that it is just a matter of configuring data on the volume that houses your VDI solution. You can find the full details here: Deploying Data De-duplication for VDI storage in Windows Server 2012 R2
It involves the same de-duplication cmdlets that were used in Windows Server 2012, with one small change as illustrated in the following example:
Enable-DedupVolume C:\ClusterStorage\Volume1 –UsageType HyperV
Then it is the same cmdlets you may have used in the past; Start-DedupJob, Get-DedupVolume, Get-DedupStatus, Get-DedupJob….etc
If you want to give Windows Server 2012 a try take a look here: https://aka.ms/getwindowsserver2012R2
If you want to learn more about the background of the data de-duplication functionality take a look here: Introduction to Data Deduplication in Windows Server 2012.
For the full list in the series: Windows Server 2012 R2 Launch Blog Series Index #WhyWin2012R2