Microsoft Azure 托管服务可靠性设计
服务的可靠性至关重要,而影响可靠性的因素多种多样,例如程序错误、硬件故障或依赖服务故障,以及人为失误。工程师们要对每个方面做出合理的设计来避免或容错各种故障,才能使服务达到高的可靠性。除此之外,当服务已经中断,如何快速定位问题并解决也是产品设计时就需要考虑的。这篇文章只以“CalculateCloud”为例,讨论一下托管服务的高可靠性设计。
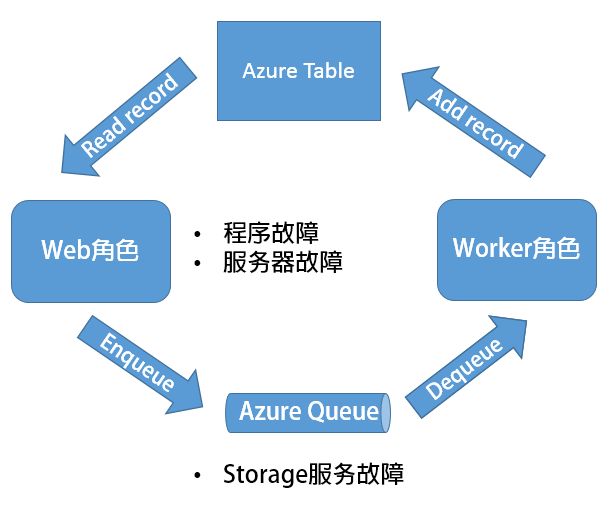
拿出CalculateCloud的架构图看看,影响服务可靠性的有如下几方面:
- 程序故障:这里只WebRole/WorkerRole代码出错。
- 服务器故障:这里只运行角色代码的虚拟机发生故障。
- 依赖外部服务的故障/维护:这里指托管服务所使用的Table或Queue发生故障。
接下来针对每种故障,我们逐个寻找对策:
程序故障
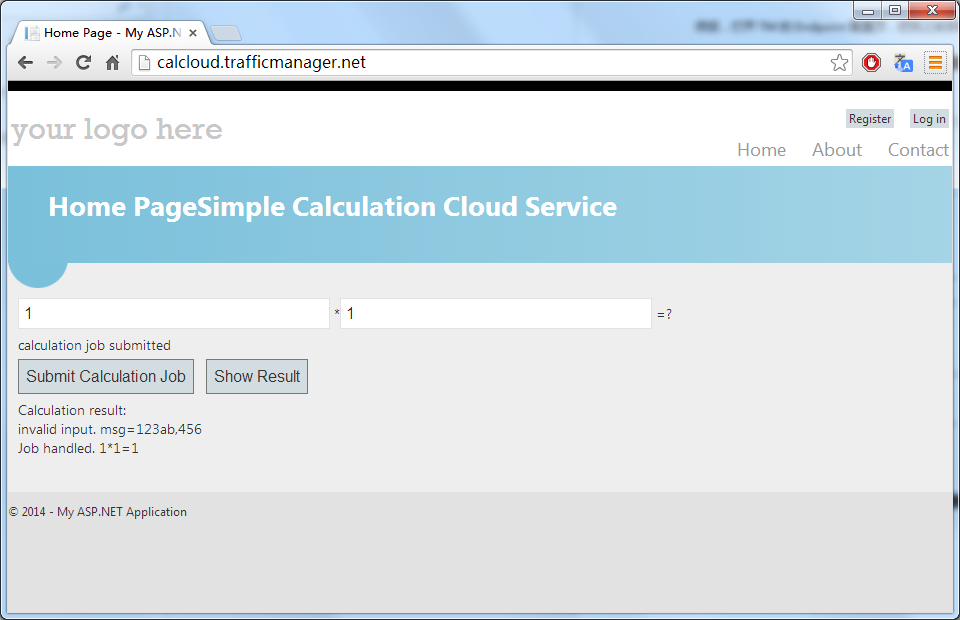
托管服务程序的调试和其他代码一样,在开发和测试阶段,可以使用模拟器在本地环境运行和调试代码。比如CalculateCloud非法字符输入的问题,在本地调试时,Visual Studio能够提示WorkerRole代码抛出异常。
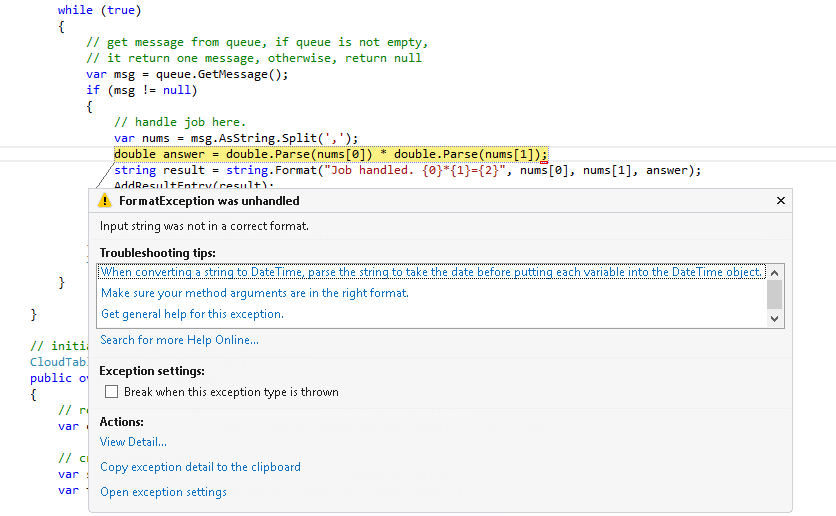
对于此问题,使用try/catch来受理异常,问题就搞定了。需要留意的是,一旦部署到生产环境下,debug会比较困难。相比之下,丰富的程序日志能帮助用户监测服务状态和快速定位问题。下面的代码使用默认的 System.Diagnostics.Trace类来输出日志。
if (msg != null )
{
string result = null ;
try
{
// handle job here.
var nums = msg.AsString.Split( ',' );
double answer = double .Parse (nums[0]) * double .Parse (nums[1]);
Thread .Sleep ( 10000);
result = string .Format ( "Job handled. {0}*{1}={2}" , nums[0], nums[1], answer);
}
catch ( FormatException )
{
result = "invalid input. msg=" + msg.AsString;
Trace .TraceError ( result);
}
catch ( Exception ex)
{
result = string .Format ( "failed to handle job. msg={0}" ,
msg.AsString);
Trace .TraceError ( result + ", error=" + ex);
}
finally
{
AddResultEntry(result);
queue.DeleteMessage(msg);
Trace .TraceInformation ( result);
}
}
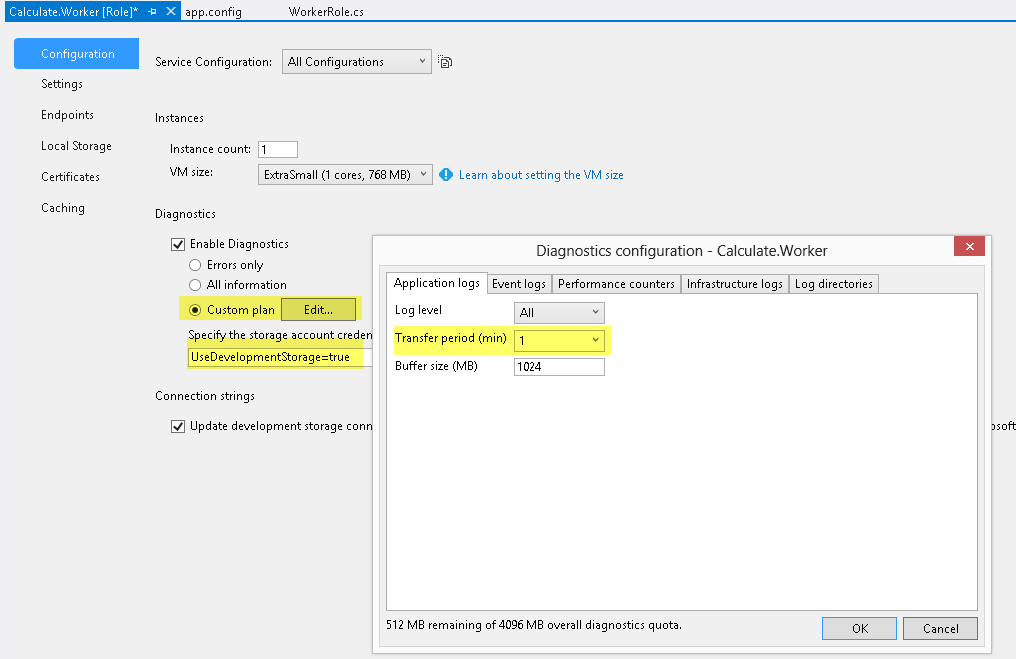
角色项目默认使用Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener来写日志。程序日志会以二进制形式写到虚拟机的本地磁盘C:下。由于角色可以运行在多台虚拟机上,那么日志也会分散在多台服务器上,登录每台虚拟机来查看日志会很麻烦,这里可以使用托管服务的一个组件“Windows Azure Diagnostics(WAD)”来解决问题。WAD会在每台虚拟机上启动两个额外进程,它们定期将虚拟机上的日志上传到Azure Storage上,用户可以从一个集中的地方访问所有日志。WAD的配置如下:
打开的Calculate.Worker的角色属性面板,在Diagnostics节中选择“Custom Plan”,然后设置存储日志信息的Azure Storage 连接字符串,再点击“Edit…”按钮,修改Application Logs的上传频率为1分钟。
WebRole同样需要添加Trace代码并配置WAD,这里不再重复。
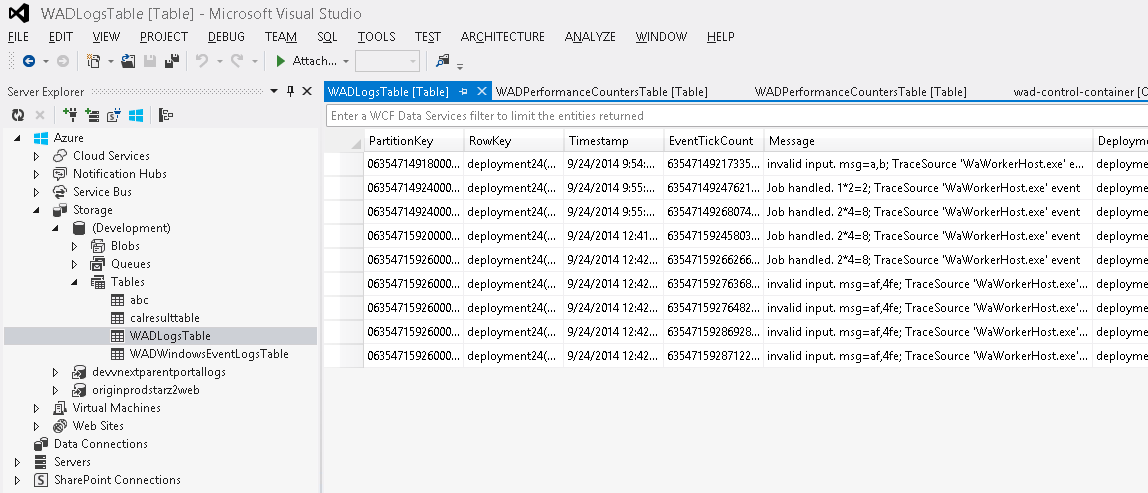
WAD开启后,应用程序日志会被定期上传到Table Storage “WADLogsTable”表,大家可以用各种工具来查看日志,比如集成在VisualStudio “Server Explorer”中的Azure资源查看器。
WADLogsTable的索引键为”PartitionKey+RowKey”,其中PartitionKey格式为字符串 ” 0”+datetime.Tick。一个常用的查询语句如下,其含义为:查询部署ID为 08cd08dce90d4516b21be7bfe6936c75,在9/24/2014 1:00:00 AM UTC后,级别至少为“警告”的所有日志。
PartitionKey gt '0635471172000000000' and DeploymentId eq '08cd08dce90d4516b21be7bfe6936c75' and Level lt '4'
WAD提供了很多的功能,感兴趣的读者可以查看MSDN官方文档
https://azure.microsoft.com/en-us/documentation/articles/cloud-services-dotnet-diagnostics/
https://msdn.microsoft.com/library/azure/gg433048.aspx
Storage服务故障
一个复杂系统必定会存在外部资源引用。当被依赖的资源发生故障时,往往会影响到系统的可靠性。在设计时,需要考虑到如何容错外部资源的故障,尽量降低对系统的影响,或者至少能快速定位出问题的资源,以便采取准确的恢复措施。
微软保证Azure Storage 在99.9%的时间内能正常运转,也就是说每个月最多可能offline 44分钟。因此,准备应对Storage故障是很有必要的。
Azure Storage运行在普通的硬件上,硬件故障不可避免,另外由与系统维护,版本更新或者负载均衡等原因,都会造成某些Storage服务器短暂下线,而其正在执行的用户请求就会失败。对于此类型的访问失败,用户只需重试一次,请求就会被移交给健康的服务器节点进行受理。因此,微软强烈建议客户端收到错误(超时或HTTP500)时重试几下。实际上,Azure Storage .net library默认已经实现了重试机制,并默认开启。对于直接使用REST API来访问Storage的代码,务必捕获异常状态并重试。
虽然较少发生,不过有时候重试也会失败,开发者需要自己捕获失败并受理。检查CalculateCloud的WorkerRole.cs文件,你会发现一旦访问storage的重试机制失败,WorkerRole程序就会因为未受理的异常而crash,从而导致更严重的系统服务中断。解决办法就是try/catch storage异常。这里我把错误记录下来,查询日志时若发现大量Storage错误信息,则说明Storage存在问题,需要采取措施。
while ( true )
{
try
{
var msg = queue.GetMessage();
……
}
catch ( Exception ex)
{
// write trace.
Trace .TraceError ( "error occured when access storage. " + ex);
}
}
另外,为了进一步提高Storage的可靠性,可以使用Storage的异地备份-只读(RA-GRS)的功能,此功能将用户的数据存放在相邻的两个数据中心上,当其中一个数据中心故障,用户可以读取另一个数据中心备份。此功能可以保证数据读取99.99% 的可靠性,而数据写入可靠性仍为99.9% 。需要注意的是:数据在两个数据中心间同步,会有几分钟的延迟。使用RA-GRS的方法如下。
在Azure管理网站上导航到Storage配置页,更改Replication模式到“READ-ACCESS GEO REDUNDANT”
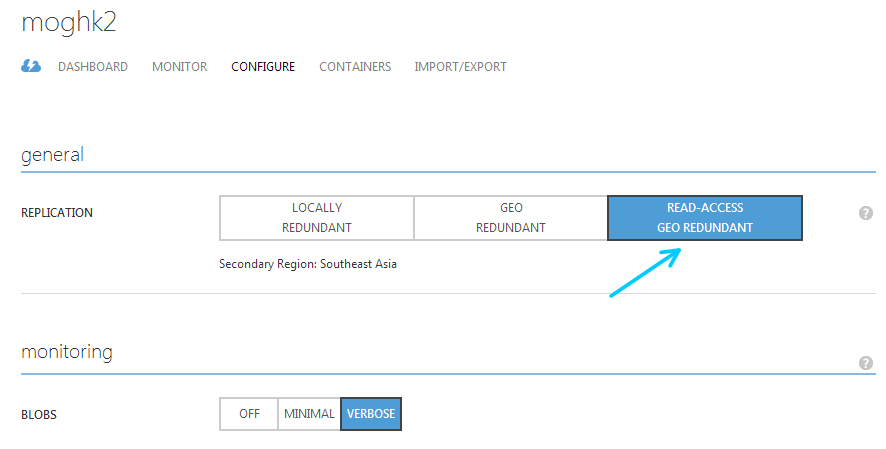
除此之外,还要修改代码,让Storage客户端能够自动failover到异地备份上。以CalculateCloud显示运算结果为例,需要更改WebRole的Default.aspx.cs文件。
protectedvoid Button2_Click( object sender, EventArgs e)
{
try
{
var connstr = RoleEnvironment
.GetConfigurationSettingValue( "DataConnection" );
var storageAccount = CloudStorageAccount .Parse (connstr);
var tableClient = storageAccount.CreateCloudTableClient();
tableClient.DefaultRequestOptions.LocationMode =
LocationMode .PrimaryThenSecondary ;
……
服务器故障/维护
托管服务是PAAS层面的服务,服务器的可靠性由平台来负责。微软对托管服务可靠性保证(SLA)的定义为:当每个角色运行在至少两个实例(即虚拟机)时,保证托管服务99.95%的在线时间。这个SLA如何理解呢?我先解释一下Azure平台的可靠性设计。
托管服务下的每台虚拟机被同时分配到两种域:故障域和更新域。故障域是物理上的概念,数据中心上每组机柜既是一个物理域,它有独立的电源管理和网络组件,一般认为,多个故障域不会同时发生故障。更新域是逻辑上的概念,管理器(FC)按照规则,同一时间只会维护一个更新域中的虚拟机。在Azure平台上,运行同样角色的三台实例(即虚拟机)是这样分配的:
|
故障域1 |
故障域2 |
故障域3 |
更新域1 |
WebRole_IN_0 |
|
|
更新域2 |
|
WebRole_IN_1 |
|
更新域3 |
|
|
WebRole_IN_2 |
如此一来,无论是硬件故障还是系统维护,同一角色的虚拟机不会同时下线 。这样解释大家就明白了吧,托管服务SLA保证了角色实例不会同时下线,而开发者需要在这种机制上建立可靠的程序。
那么用户如何充分利用平台特性来实现服务的高可靠呢,David Chappell总结了Azure编程三原则:
- 每个托管服务拥有至少一个角色
- 每个角色需要运行至少两个实例
- 即使部分实例故障,整个Azure托管服务仍可正常运行
大家若想了解更多信息,可以下载David所写的托管服务编程模型白皮书,或者翻看一下《Microsoft Azure开发与应用》。我这里用三原则来检查一下CalculateCloud项目。
第一原则是强制原则,显然满足。对于第二原则,目前每个角色只运行在一台虚拟机上。这个修改很方便,打开每个角色的属性面板,修改 Instance Count为 2。
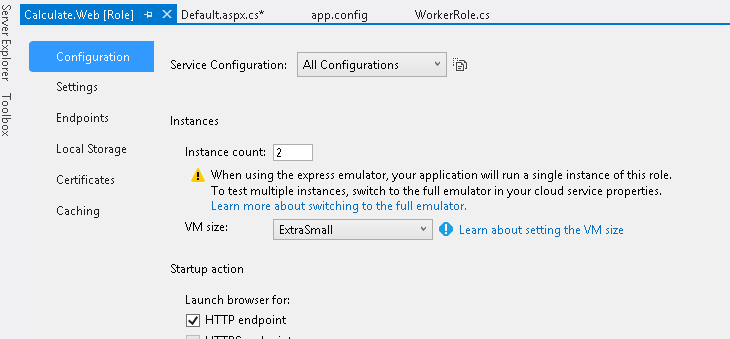
第三原则比较复杂,具体讲就是要求同一角色的实例拥有同样的功能,并且保持无状态,其中一个实例下线后,另一个可以替代它执行任务。
对于WebRole,实例运行在负载均衡器(SLB)后,负载均衡会探测实例的状态,并将Request分配给健康的实例上。为保证第三原则,每个WebRole实例不应该将客户的状态(如Session)保存在本地(进程或磁盘),否则一旦虚拟机下线,运行在它上面的客户将遭遇信息丢失的问题。Calculate.Web角色访问的所有数据都保存在外部Azure Storage上,因此满足第三原则。
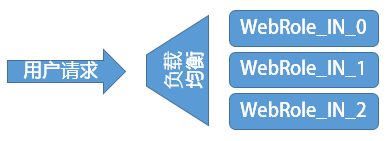
Calculate.Worker不在本地保存中间结果,运算结果也直接写到Azure Storage了,所以也满足地三原则。
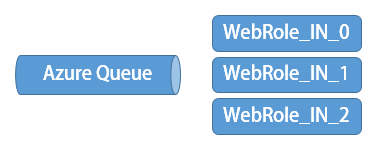
大家可以把CalculateCloud部署到云端测试一下,当重启一个Calculate.Web实例和一个Calculate.Worker实例时,整个服务仍然正常运行。即使Calculate.Worker所有的实例都重启,得益于Azure Queue持久化消息通信,服务仍然可用,只是计算工作会有所延迟。
追求更高的可靠性
有些客户对服务可靠等级有更高的要求。比如发生数据中心级别的故障时,服务仍然可用。Azure平台能做到吗?当然能啊,只要愿意花更多的钱。
微软提供的另一个服务叫做Traffic Manager(简称TM),它工作在一组托管服务前,将客户的服务请求按照规则重定向到背后的某个托管服务上。以下图为例,解释一下流程。
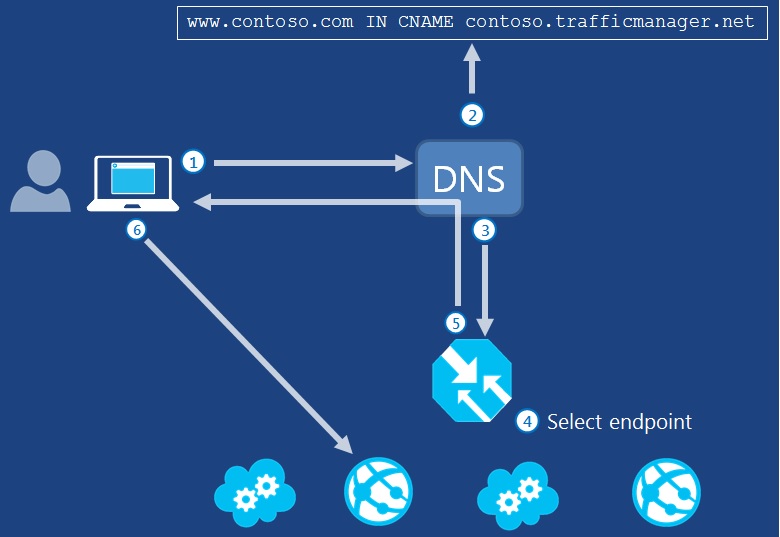
- 客户要访问服务(www.contoso.com),首先发DNS解析请求到公网的DNS服务器。对于服务提供商,他需要事先从域名提供商那里购买一个公网域名consoto.com。
- DNS服务器将服务的域名(www.contoso.com)重定向到TM的域名(*.trafficmanager.net)。对于服务提供商,他需要事先配置子域名www.contoso.com的解析规则,将其CNAME到TM。
- DNS服务器访问TM的域名服务器来索要解析的IP地址。
- TM根据规则选择一个托管服务(现在TM支持所有公网服务)。TM会检测托管服务的状态,确保选择健康的服务。另外,用户可定义选择方式:根据性能,平均分配,或者故障迁移。
- TM域名服务器把选择的服务IP地址返回给公网DNS服务器,最后返回给客户。
- 客户得到服务IP后,直接访问服务地址,不再经过TM。
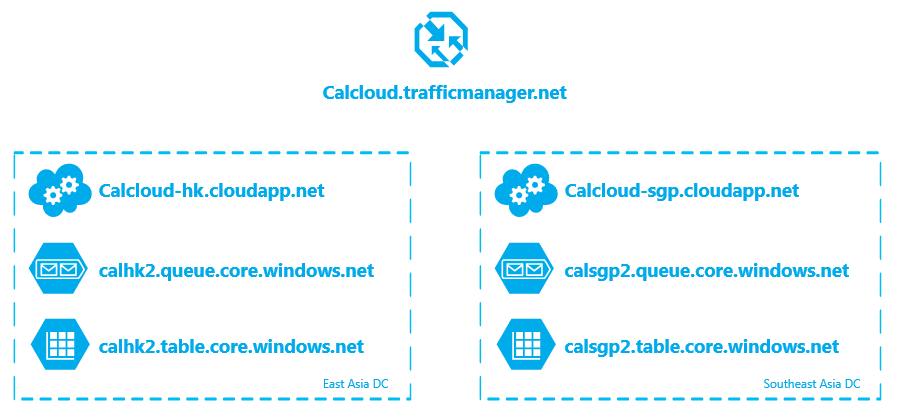
有了Traffic Manager,就可以做跨数据中心的服务备份了。以CalculateCloud为例,可以这样设计:在香港和新加坡各部署一个托管服务,然后在香港创建一个Azure Storage账号,并开启RA-GRS。香港的托管服务直接访问Azure Storage主地址,新加坡的托管服务访问Azure Storage主地址来写数据,而读取操作直接访问Azure Storage备份的地址(<accountname>-secondary.table.core.windows.net)。最后,创建一个Traffic Manger,将两个托管服务的地址添加到Endpoint Set中。
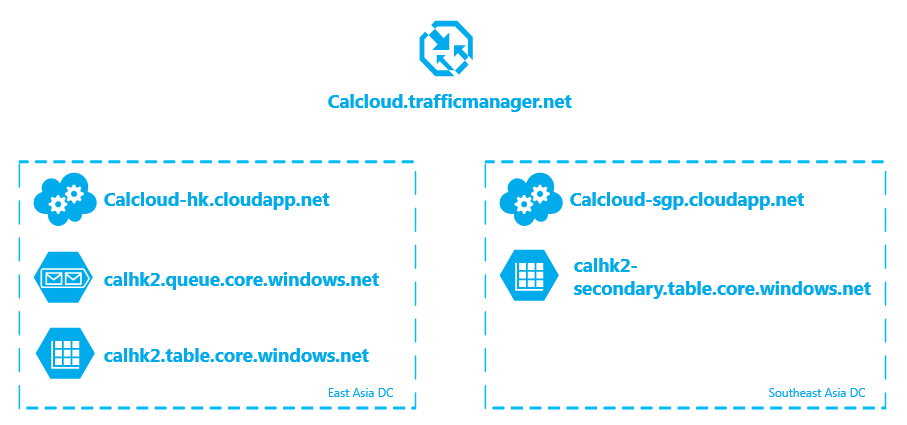
这种设计可以在单个托管服务下线时,保持整个系统的可用性。而当整个香港数据中心下线时,系统进入只读运行模式。具体实施步骤如下:
首先把托管服务部署到香港数据中心和新加坡数据中心。为了让新加坡的服务访问Storage备份,还需要更新Default.aspx.cs代码。
protectedvoid Button2_Click( object sender, EventArgs e)
{
try
{
var connstr = RoleEnvironment
.GetConfigurationSettingValue( "DataConnection" );
var storageAccount = CloudStorageAccount .Parse (connstr);
var tableClient = storageAccount.CreateCloudTableClient();
tableClient.DefaultRequestOptions.LocationMode =
LocationMode .SecondaryThenPrimary ;
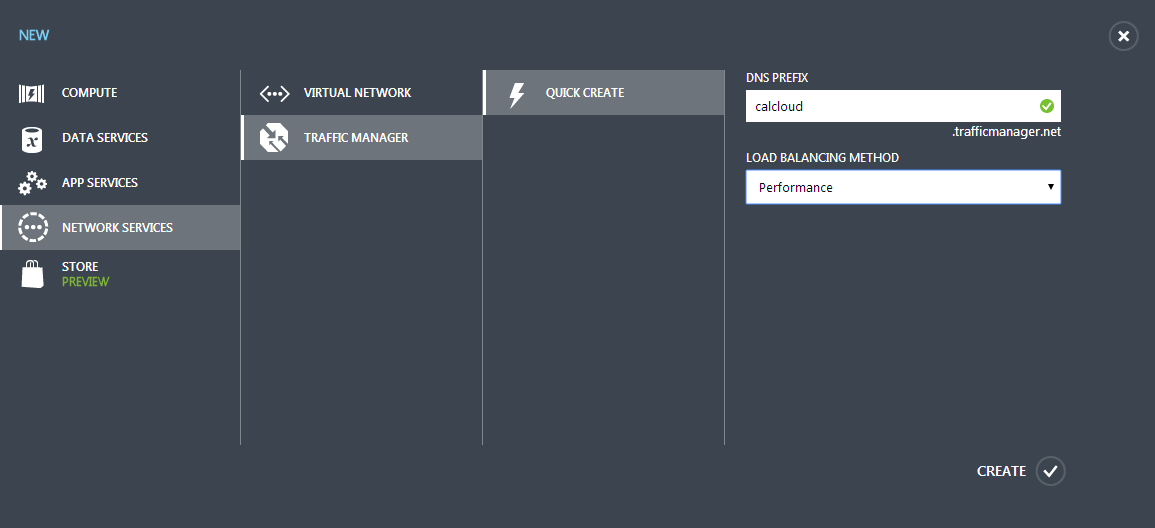
接下来,登录Azure管理网站,创建一个Traffic Manager。
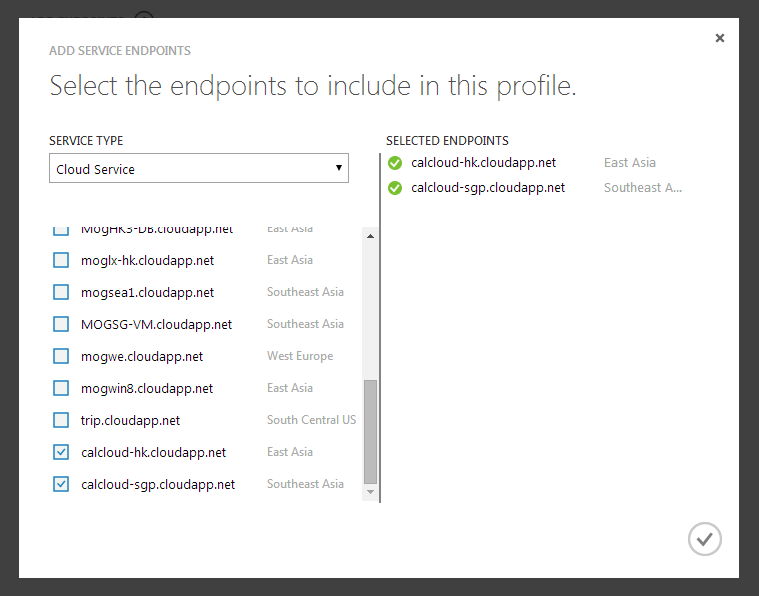
然后,打开TM的Endpoint配置页,把我之前部署的两个托管服务添加进来。
搞定。Traffic Manager还有很多配置选项,感兴趣的朋友看看MSDN文档吧。
https://msdn.microsoft.com/en-us/library/azure/hh744833.aspx
当然,除了上面的设计方案外,咱还可以在每个数据中心创建单独的Azure Storage,这样即使数据中心故障,服务也完全可用。不过这需要对代码做更多的调整,确保客户访问每个托管服务都能得到一致的结果。
Traffic Manager是个结构简单的服务,它的可靠性保证(SLA)为99.99%。不过根据我的经验,从服务GA到目前为止,零故障。索契冬奥会官方网站的方案就用了TM,当时他们在四个数据中心部署了八个托管服务,用TM做负载平衡。
总结
文章并没有涵盖所有Azure服务,而提到的方案也并非可以套用到所有场景下,这里只当作为抛砖引玉,供大家参考。这里总结一下提到的方法。
故障类型 |
应对方法 |
代码故障 |
|
Azure Storage故障 |
|
服务器故障 |
|
数据中心大灾难 |
|
另外,高可靠性意味着系统冗余,增加运营的成本和系统复杂度。用户需要在可靠性和各种指标之间找到合适的平衡点。