Designing and Managing Servers for Cloud-Scale Datacenters: Part 2
 Kushagra Vaid, General Manager
Kushagra Vaid, General Manager
Server Engineering
As I discussed in a recent blog post, designing infrastructure for cloud services like Office 365, Windows Azure, and Bing requires an understanding of the nexus of interactions between workloads, the Cloud OS, and server/datacenter architecture. It is critical to take a holistic view across these key areas in order to understand and achieve total cost of ownership (TCO) benefits, as the combination presents efficiencies that are greater than the sum of their parts. Today, I'll take a deeper look into the technologies that Microsoft uses to manage its cloud-scale, software-defined datacenters, how these impact server designs, (including server capacity provisioning allocation), and how we balance workloads.
Server capacity allocation at cloud-scale
The massive scale of our operations often presents interesting challenges that we address by looking across the systems stack. Solving these scale problems requires us to weave principles across various architecture and operational disciplines with the intent of providing the most optimal operational infrastructure. Software plays a key role in this integration and is coupled with hardware to provide vertical integration benefits.
In Microsoft datacenters, we deploy commodity server clusters. Because our server clusters run multiple workloads over their lifetime, with differing performance and power characteristics, power capacity allocation decisions are made in advance to accommodate the diversity and ensure maximum performance of the workload. One key challenge is how to plan power capacity for deploying clusters to account for the worst case workload, but still drive maximum possible performance across all other workloads that are hosted on the same infrastructure. This is a common challenge faced by datacenter operators and the solution requires a well-coordinated approach to find the right balance between power and performance tradeoffs at the datacenter level over the lifetime of the deployed server cluster.
Balancing workloads
Consider two common workloads that are deployed in Microsoft datacenters: web search query serving and batch processing using MapReduce. These workloads share a common commodity server SKU, however, the workload utilization levels and power profiles for each are very different. Query serving is driven by Internet users, and is subject to varied query traffic patterns depending on the time of day. MapReduce, on the other hand, is batch-oriented and tends to run at a maximum utilization rate. Assuming these are the only two workloads in the datacenter, let's look at some examples to understand how the power provisioning challenge plays out.
Let's assume that the typical server power draw when running intense MapReduce jobs is 250 watts, and query serving is 200 watts, and that we need to allocate server capacity in a 10 megawatts colocation. Let's analyze two provisioning power scenarios. In the first scenario, by provisioning capacity based on a high-power workload (MapReduce), we can fit roughly 50,000 servers into a colocation. In the second scenario, where we provision capacity based solely on the lower power workload (query serving), we can fit 40,000 servers.
Since it's unlikely that only one workload will be running at a time, we need to find the appropriate capacity allocation (somewhere between 40,000 and 50,000 servers in our example) so that we strike a balance between under-provisioning (in case there are more instances of the query serving workload) and over-provisioning (in case there are more instances of the MapReduce workload). Determining this sweet spot is important for TCO optimization. If we assume $10 million per megawatt for the cost of power provisioning, then inefficient allocation can cost up to $20 million worth of stranded power. There is also an opportunity cost of under-provisioning since this could lead to building new datacenter capacity when there is already existing capacity that could be utilized. At cloud-scale where we deploy hundreds of megawatts of datacenter capacity, these cost economics deserve close attention to ensure optimal use of resources.
With these scenarios in mind, we are faced with two key questions: How can we optimize the server provisioning for such a variety of workloads? Also, what server technologies are needed for enabling these high-value business scenarios?
To address these questions, we need to find mechanisms to:
- Reduce the power budget for the MapReduce workload without impacting performance
- Utilize any available power budget for the query serving workload to drive higher performance
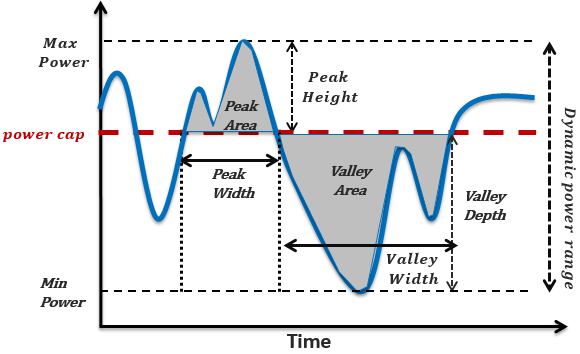 |
To address #1, it is important to understand the operating profile of the workload. As shown in graphic #1, there are peaks and valleys for any workload during its runtime. How do we choose a power level as the maximum budget so that the peaks can be 'shaved' or 'absorbed'? First we have to perform workload analysis on production servers to understand how often peaks occur and the amplitude and duration of those peaks. In our testing, we found that large peaks are rare, and if we reclaim nine percent of the power budget, it impacts only one percent of the peaks. These peaks can be handled by mechanisms such as in-server batteries that absorb the peaks without relaying them into the datacenter circuits. We can also manage them by throttling the workload when these peaks occur, although with a slight performance loss, or by workload migration to another cluster with available power capacity. The appropriate reaction depends on the length of the peak. For short peaks less than 30s, the battery solution is preferred. Such server technologies allow for power capacity budget reduction, allowing for worst-case workloads to be scheduled in the datacenter but without the risk of under-provisioning for other workload instances.
For addressing #2, we need to use available power budget to increase workload performance. A simple and effective technique is to drive higher CPU core frequency. Turbo Boost mode is a feature available in x86 CPUs which allows the CPU to run faster than the base operating frequency - sometimes up to 30 to 40 percent faster - as long as the CPU thermal specification limits are not exceeded. Higher frequency for workloads such as query serving is helpful, since it enables higher levels of performance. As shown in Graphic #2, we found query latency improvement possibilities with Turbo Boost mode enabled.
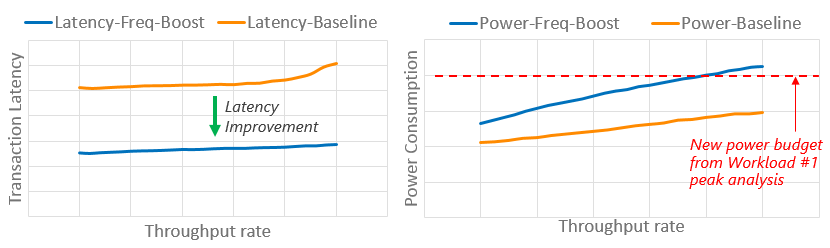
While this is acceptable for low- to mid-utilization levels where power budget is available and Turbo Boost mode enables higher performance for the application while staying within the power budget, the same procedure presents risk for higher utilization levels. The increased power consumption would exceed power budgets leading to potential outages. To gain performance benefits from Turbo Boost mode across all load levels while limiting risk on the power overdraw at high loads, we implement power capping.
In previous examples, we addressed #1 by implementing a power cap that had minimal impact on the Map-Reduce workload. We can use that same power cap to limit the consumption budget for the query serving workload as shown below.
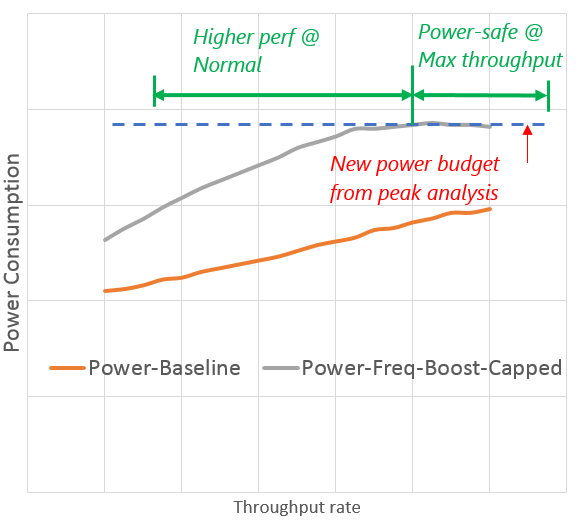
This power cap assures us we will not exceed the system power, and we can reliably turn on Turbo Boost mode to gain performance for other workloads such as query serving. This example shows how static power capping can be used for optimizing workload performance in a fixed power envelope. While this has clear benefits, the same mechanism can be extended to a whole different level by implementing dynamic power capping at the datacenter level.
To weave the power capping feature into cloud-scale deployments, we integrate the Cloud OS and the datacenter design. The Cloud OS then has visibility into dynamic power consumption for all server clusters. , For those workloads impacted by power capping, a policy framework details the levels at which potential Service Level Agreements (SLA) violations could occur. Additionally, the Cloud OS also has visibility into datacenter events such as equipment failures, load imbalances, and power utility outages. With access to this real-time monitoring information from both the server clusters and the datacenter, the Cloud OS can take reactive actions when dealing with potential SLA-impacting events.
These type of policy frameworks in the cloud-scale, software-defined datacenter are only possible through tight orchestration between the Cloud OS, the server management framework, and datacenter control systems. The resulting server design needs to incorporate these policy mechanisms and provide system management support for implementing these policies. Microsoft is driving these types of efficiencies for datacenter operations to generate the greatest TCO benefit from deployed resource pools.