Using Math Alphanumerics in Code and Web Pages
The post UTF-8 RTF shows how much easier it is to read the rich text format (RTF) with Unicode characters instead of the RTF \uN notation. You see the real characters instead of signed 16-bit decimal numbers and two such numbers for characters above the BMP. In fact, UTF-8 RTF is remarkably readable. The same readability improvement occurs in computer programs and web source. This post illustrates how much easier it is to read C++ programs and MathML using UTF-8.
Contemporary compilers, editors and browsers support UTF-8 and there’s no need to use ASCII numeric character codes like \x222B. The use of such ASCII is so last century. If you want ∫, use ∫ instead of \x222B. UTF-8 is the default encoding for HTML and XML and is the most widely used encoding on the web. This includes excellent plane-1 support thanks in part because most emoji are there. Hence the support for plane-1 math alphanumerics is excellent everywhere as illustrated by the math alphanumerics in this post.
C++
Microsoft Office apps run on the Windows, Mac, iOS, and Android platforms. The compilers and editing environments for these platforms all support UTF-8 source files. For example, my math unit tests include string literals like L"𝑥=(−𝑏±√(𝑏^2−4𝑎𝑐))/2𝑎", which is the UnicodeMath for the solution to the quadratic equation. Using last-century notation (ASCII with hexadecimal literals), that string can be written as
L"\xD835\xDC65=(\x2212\xD835\xDC4F\x00B1\x221A(\xD835\xDC4F^2\x2212"
L"4\xD835\xDC4E\xD835\xDC50))/2\xD835\xDC4E"
That’s hard to read, while L"𝑥=(−𝑏±√(𝑏^2−4𝑎𝑐))/2𝑎" is easy to read and comprehend.
Another example is an entry in the RichEdit Nemeth braille conversion tables
{L"⠀⠈⠱⠨⠅⠀", 0x2245 }, // ≅ Approximately equal to
Here the braille string in L"⠀⠈⠱⠨⠅⠀" is encoded in the Unicode braille block U+2800..U+28FF and represents the Unicode character ≅, which has the code U+2245. You can use the character literal L’≅’ instead of the 0x2245, but it’s handy to know what the Unicode value is. Typically, with character literals, I include both the hexadecimal character code and the Unicode character itself.
For years I’ve wanted to use legitimate Unicode operators like ≤ and ≠ in C++ programs (see Section 6 of UnicodeMath). While the C++ compilers still don’t recognize Unicode operators other than those in the ASCII subset, you can fake them using fonts like Fira Code that have ligatures for common ASCII operator pairs and sequences. For example, with Fira Code, <= and != display as ≤ and ≠, respectively. The widths of the ligatures are the same as the underlying operator pairs, so that the column alignment is unchanged. Try it, you might like it! One operator Fira Code doesn’t have a ligature for is ->. It should display →. Maybe someday.
You can also use the Unicode math alphanumerics in program variable names. For example, the Visual Studio C++ and Clang compilers (used for Apple and Android programs) accept code like
for (int 𝑛 = 0; 𝑛 <= 𝑁; 𝑛++)
sum += 𝑎[𝑛];
Of course, it’d be even nicer to write this as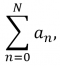 Back in the 1980’s, I coded C++ using mathematical notation as described in Section 6.2 of the UnicodeMath paper. That approach used my PS technical word processor for editing. Maybe we can add an option to Visual Studio C++ to do something similar!
Back in the 1980’s, I coded C++ using mathematical notation as described in Section 6.2 of the UnicodeMath paper. That approach used my PS technical word processor for editing. Maybe we can add an option to Visual Studio C++ to do something similar!
MathML
In MathML the need for math-italic letters is reduced substantially due to the convention that a single ASCII letter inside <mi>…</mi> is automatically converted to math italic for display. So, <mi>x</mi> represents 𝑥 (U+1D465). Would be nice if the reverse were true! But other math alphanumerics (script, Fraktur, bold, bold-italic, etc.) don’t have such a convention. They can be specified via the mathvariant attribute as in <mi mathvariant='script'> L </mi> for the character ℒ. But for this it’s easier to read <mi> ℒ </mi>, which is also valid MathML. The mathvariant attribute was added to MathML before the Unicode math alphanumerics were encoded in Unicode 3.1.0 (March, 2001). But now it’s only needed for reading existing documents that contain it.
In implementing MathML math variants, the Unicode math alphanumerics should be used. The character-level machinery of editors and browsers handle the math alphanumerics. There’s no need to use a higher-level protocol such as CSS to handle them. The reason the math alphanumerics were encoded in Unicode is to support math characters in plain text since different math styles have different semantics. ℋ is a different variable from 𝐻. If you ignore the difference, you convert the Hamiltonian formula
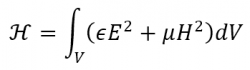
into an integral equation! Something with an entirely different meaning.
Using CSS in MathML may also limit the resulting content to environments that support CSS. That excludes many math programs and CSS isn’t supported in the Office MathML readers and writers. So, while CSS can be used “under the sheets” to implement MathML display, it shouldn’t be part of MathML content or, at least, ignoring it shouldn’t change the meaning of the content.
Entering UTF-8 characters in programs
In contemporary document editors such as Word, you can enter Unicode characters in a variety of ways, ranging from an Insert Symbol dialog and math-ribbon galleries to the hex hot key Alt+x (type 222B Alt+x and you get ∫). At present, the Visual Studio IDE editor doesn’t offer such input methods, although it should. To make up for this, you can enter them in Word or RichEdit and copy them into your C++ programs and web pages.