Understanding Service Fabric Partitions
Editor’s note: The following post was written by Microsoft Azure MVP Damir Dobric as part of our Technical Tuesday series.
Service Fabric offers several types (concepts) of scalability and reliability. For example you can setup multiple instances of a service or you can setup multiple partitions of a service. You can even combine both types. This is definitely a powerful concept, but in some cases it might be overused. In this article I will describe some partitioning concepts and provide a few examples for those. All parameters used for configuring the deployment in this example can be found in ApplicationManifest.xml file of your Service Fabric solution as shown in the picture below.

Partitioning of Stateless Services
One of the service types used in Service Fabric is a so called stateless service. Such services do not persist any state locally by default. For example this might be a service which is returning the current time. If you want to run multiple instances of this type of service, you have a few choices.
When the new service is added to the project, it will be configured to use a so called SingletonPartition. That basically means a single partition is used, which translates to “partitioning is not used”. This is commonly used by most services, which do not relay on the Service Fabric partitioning concept. This is the case when you want to run your web server in Service Fabric Cluster for example. This is a valid scenario for Web Servers or Web Services, which need to access low level machine features. In contrast to Azure Web Sites, PaaS vNext services (Services hosted in Service Fabric) can run On-Premise and in the Cloud, without of the need to change any code. With the current version of Worker-Roles and Web-Roles, we are not able to fully reuse code between the cloud and On-Premise environment.
The following code snippet shows the configuration from the ApplicationManifest.xml file, which is automatically created, when one service is added to the solution.
<Service Name="Stateless1">
<StatelessService ServiceTypeName="Stateless1Type"
InstanceCount="2">
<SingletonPartition />
</StatelessService>
</Service>
As already mentioned, SingletonPartition defines that no partitioning should be used.
Additionally, it is important to set a number of nodes to which the partition will be deployed. Commonly this is exactly the place where things get complicated. As an example, let us look at a SingletonPartition (number of partitions 1) with InstanceCount = 2. After the deployment of the service you can start Service Fabric Explorer and navigate to the deployment. You will likely get following result.

A Partition is a logical artefact, which gets its physical representation by associating the deployment with the node. In this context you should understand the deployment as a unit of code and state. In a case of a stateless services, state does not exist, which means that the deployment contains the code only. Deployment is defined as the physically running instance of the service. If the service has state (stateful), the instance will have an associated instance of state.
When the service from the example above is started, the entry point RunAsync() will be invoked twice. Once on the Node.3 and once on the node.5 For this scenario Service Fabric will start two processes “stateless1.exe” (one on each node). When you work with common services, which do not Service Fabric features avoid using partitions and use SingletonPartition approach. In this case, InstanceCount helps you to define the number of physical nodes, where your application (i.e. your Web Service) should be deployed.
If you really want to see how partitioning works under the hub, you can play with the next example. This is an example which shows the deployment of the same stateless service with 4 partitions on 2 nodes each (instanceCount=2). This means that every partition will be span across two nodes. For stateless services this seems to be weird. And it is weird. The partitioning concept has a goal to partition data sharing across nodes. In the case of a stateless services there is no data. This is why partitioning makes more sense when working with stateful services. But for now, we still stay in the context of stateless services to get a better understanding of the platform.
When one partition is spanned across two nodes it does not mean that every partition will be spanned across the exact same two nodes. This can be illustrated with following example. For this example, I used the NamedPartition scheme.
<Service Name="Stateless1">
<StatelessService ServiceTypeName="Stateless1Type"
InstanceCount="[Stateless1_InstanceCount]">
<NamedPartition>
<Partition Name="one" />
<Partition Name="two" />
<Partition Name="three" />
<Partition Name="four" />
</NamedPartition>
</StatelessService>
</Service>
After deployment in two partitions on two instances, you might see this result in Service Fabric Explorer:
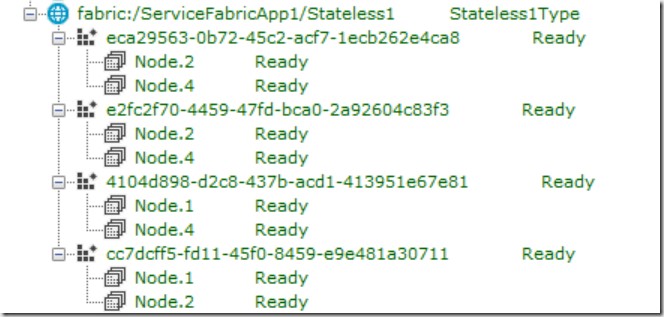
Because my cluster consists of 5 machines (discussing this is out of scope of this article), the Service Fabric framework has decided to share my 4 partitions across 3 nodes: 1, 2 and 4. You could open Task Manager now and would notice 3 processes. I also tried different deployments with the same configuration. Sometimes I got a deployment of 4 partitions across 4 nodes (not just 3 as shown in task manager below). The algorithm which performs partitioning is currently undocumented and it is being improved over time.

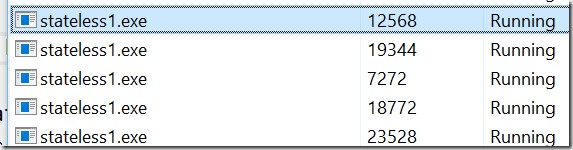
When you start your service, the entry point RunAsync() would now be invoked 8 times. Once for every partition at every single node. Because 4 partitions are deployed on two instances (nodes) each, we will have 8 instances of the service.
But, do not be surprised if you in the future might get slightly different results regarding sharing of the service between the nodes. Remember that a few facts will not be changed. This is the number of instances of the service. If you have 8 instances, your service will be entered 8 times independent on the number of processes running.
Now, let’s change the configuration slightyly to use the uniform partitioning scheme instead of named partitioning from the previous example. All other parameters remain unchanged, which means 4 partitions across two instances each.
<Service Name="Stateless1">
<StatelessService ServiceTypeName="Stateless1Type"
InstanceCount=”2">
<UniformInt64Partition PartitionCount="4" LowKey="1" HighKey="10" />
</StatelessService>
</Service>
As result 4 partitions will be span across all 5 nodes in cluster:
In Service Explorer, is reflected in the next picture:
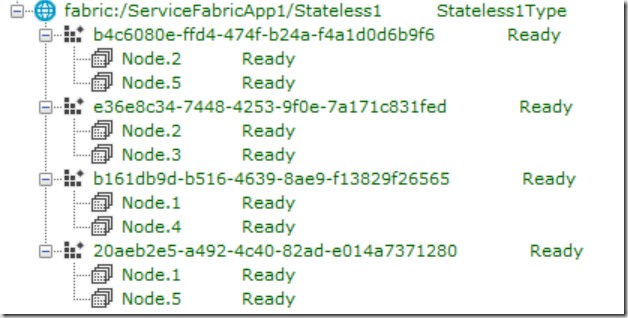
Now we have 8 partitions, but this time shared across all 5 nodes in the cluster. As you can see partitioning is a very weird, but powerful concept. But be careful, when using it if you don’t need it. If you host commonly used types of services like Web Servers or similar, most likely you will not require partitioning. In such cases you can achieve an easier deployment by using SingletonPartition in combination with the instance count property, enabling you to exactly define, how many physical nodes your service are running.
Partitioning of Stateful Services
The true focus of Service Fabric is dealing with stateful services. Service Fabric helps by solving many complex problems. One of the major approaches of Service Fabric is a conceptual move of data from the database to the code. By implementing stateful services instead of stateless-services the code keeps its data in the cache without of a need to talk to the database. Moving of data from a database to code and vice versa takes some time, which depends on the amount of data which is moved. The relation of time and the amount of data in cloud computing is sometimes called “data gravity”. The concept of stateful services in combination with replicas helps reducing data gravity to almost zero.
In this context we have to define the term ‘Replica’. A replica is by definition a copy of code and data (state) of a service.
In contrast to stateless services, when working with stateful services we rather deal with replicas than with instance counts. In the following example, we will us a single partition (PartitionCount = 1) and 3 replicas. That means our code will be deployed on 3 instances (nodes) and all data will be copied between these 3 instances, every instance has the full amount of data.
<Service Name="Stateful1">
<StatefulService ServiceTypeName="Stateful1Type"
TargetReplicaSetSize="3"
MinReplicaSetSize="2">
<UniformInt64Partition PartitionCount="1"
LowKey="-9223372036854775808" HighKey="9223372036854775807" />
</StatefulService>
</Service>
Here is the result of deployment in Service Fabric Explorer.

As you see, the service was deployed 3 times, which correspond to number of the target replicas. This means, we have one instance of the service running and two copies of it, which are not active. They are installed and will be activated in a case of a failure. This is why such services are also called “Reliable Services”. However, in “real life” we should start partitioning of the data. To demonstrate this, let’s use the same configuration but increase the PartitionCount to 4.
Service Name="Stateful1">
<StatefulService ServiceTypeName="Stateful1Type"
TargetReplicaSetSize="3"
MinReplicaSetSize="2">
<UniformInt64Partition PartitionCount="4"
LowKey="-9223372036854775808" HighKey="9223372036854775807" />
</StatefulService>
</Service>
This configuration instructs Service Fabric to deploy and start 12 instances of the service. Remember, we deploy 4 partitions with 3 replicas. However only 4 instances called primary replica (corresponding to the number of partitions) will be visible to you in the running system. All other deployed instances (passive instances) will not be accessible. If you set a breakpoint in the RunAsync() method of the service and press ‘F5’ your service will stop 4 times.
On the beginning of my RunAync() method I implemented the following code:
protected override async Task RunAsync(CancellationToken cancellationToken)
{
Debug.WriteLine(">>> P:{0}, R:{1}",
this.ServicePartition.PartitionInfo.Id,
this.ServiceInitializationParameters.ReplicaId);
// TODO: Replace the following with your own logic.
var myDictionary = await
this.StateManager.GetOrAddAsync<IReliableDictionary<string, long>>
("myDictionary");
. . .
}
As a result of the execution of this code you will get following:

This result means that our service has been started (visibly to the system) 4 times. Every started instance is running in the same primary replica with id 130884527004591572. This is illustrated in the following picture.
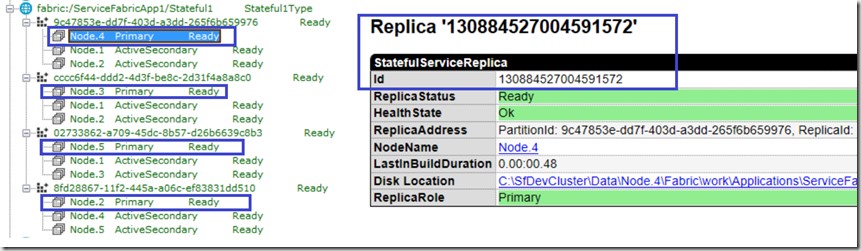
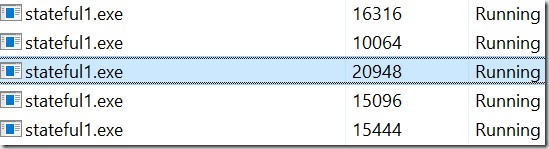
If you compare the picture above with the output result, you will notice that the code is running in the primary replica only. Last but not least, don’t wonder if you see 5 instances of the service in task manager.
Recap
To recap this weird story, we have to distinguish between stateless and stateful services. The partitioning concept is designed with the focus on partitioning the service state across physical nodes. If your service does not have a state (stateless) you should probably use SingletonPartition, which basically means “Don’t use partitioning”. In the first part of this article I have shown, what happens if you use partitions in conjunction with a stateless service.
When working with stateless services we have to deal with partitions and replicas. Every partition defines a replica, which is deployed to some physical node. The replica in the context of a partition is a physical deployment of code and part of the data of the service state. Every replica has a number of copies (target replica set size) of code and the same part of data. One of the replicas is the primary replica and others are secondary replicas. Only the primary replica hosts code which is actually active. Code deployed on the secondary replicas is in a waiting state for a failover scenario. Every partition has the same code, but a different subset of data (state). If we have 4 partitions, there are 4 instances of the service with the same code running on the primary replica and every partition holds a different portion of the data (state). Instances on the secondary replicas are not active. They are just deployed for the failover case.
About the author

Damir is co-founder, managing director and lead architect of DAENET Corporation, which is a long term Microsoft Gold Certified Partner and leading technology integrator specialized in Microsoft technologies with strong focus on Windows, .NET and Web. He was the DAENET winner of worldwide Technology Innovation Award for 2005, German innovation award for SOA in 2008 and Microsoft Partner of the year 2010.