Markdown Part 2 - Writing a Classifier
Note: I started writing this about two months ago, and a lot has changed since then. Jeff Atwood released a C# port of the Markdown script (well, a cleaned up version of another C# port of a PHP port, to be exact) called MarkdownSharp (it's on google code here). This saved me the trouble of porting all or parts of Markdown.pl or one of the other ports to C#, though it didn't get me quite all the way there. Still, my thanks to the various other peoples in the world who care enough about Markdown to port it into their language of choice, and more thanks to those whose language of choice happens to be C#. Also, another thanks to John Gruber for permission to use "Markdown" when referencing this extension.
Another note! The interwebs move at the speed of, well, something fast, so it isn't surprising that people are already doing interesting things with MarkdownSharp and sharing them with the rest of the world. One such article I read was about implementing Markdown in a "real" parser (meaning not regular expressions). Such a parser would have saved me a good day or so had it been around in the beginning, as my own "parser" isn't all that respectable (as you'll see later on). Still, there isn't anything available yet, so I'm still including the custom parser I wrote and information about it in this post.
You can always find the updated code for this blog series at markdown mode on github. If you have VS 2010 Beta 2 and the SDK installed, you can grab the source from there and build the extension to try out yourself.
First things first: a screenshot of the classifier in action, editing this very article:
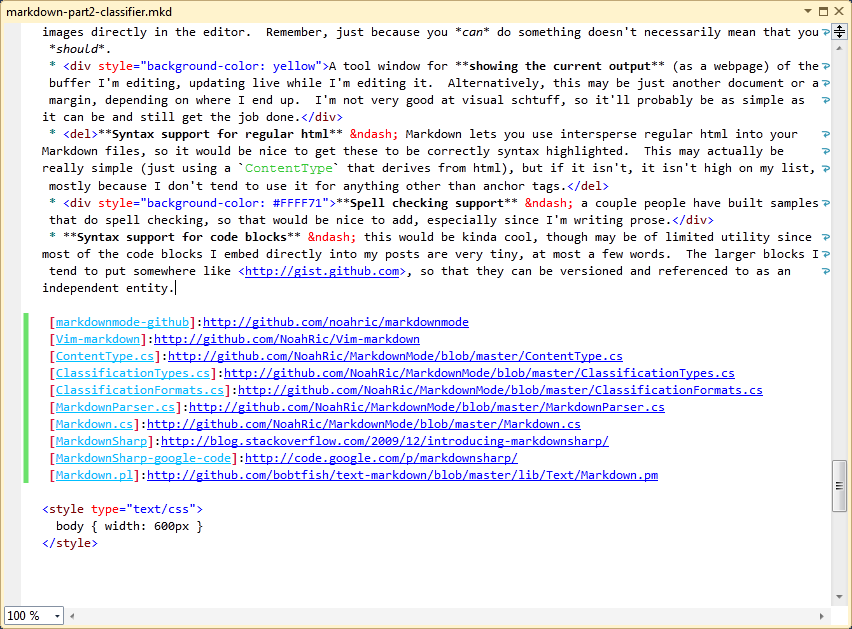
Writing a classifier
The first thing I generally look at when writing support for a new language is a classifier; you get the satisfaction of immediately visible results that you can build up fairly iteratively.
There are three basic steps to starting off your language mode: content type definition and file extension mappings, classification type and format definitions, and the classifier itself.
Content Type and File Extension mapping
This is probably the simplest portion; all we're doing here is declaring two pieces of information:
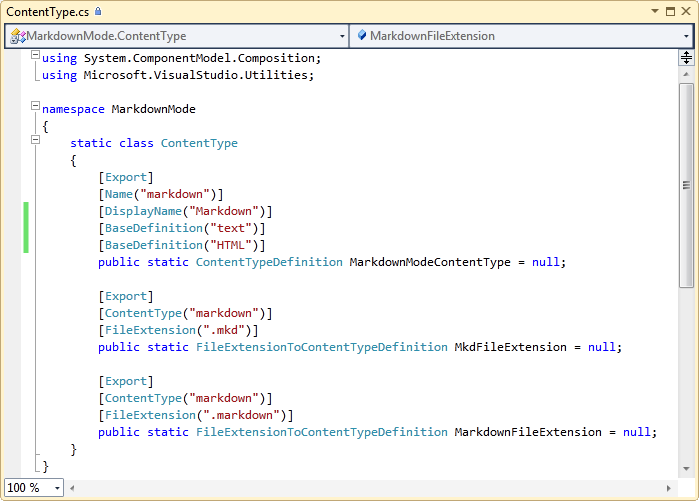
First, we are creating a content type called Markdown, that all the other pieces of our extension will use to be loaded. The majority of components you can provide as extensions to the editor allow a [ContentType] attribute for limiting the scope of when your extension will be loaded and activated.
Second, we are noting a few file extensions that we want to map to Markdown – .mkd and .markdown (there may be more, but those are the two that I use).
Here's what ContentType.cs looks like:
Classification Type and Format definitions
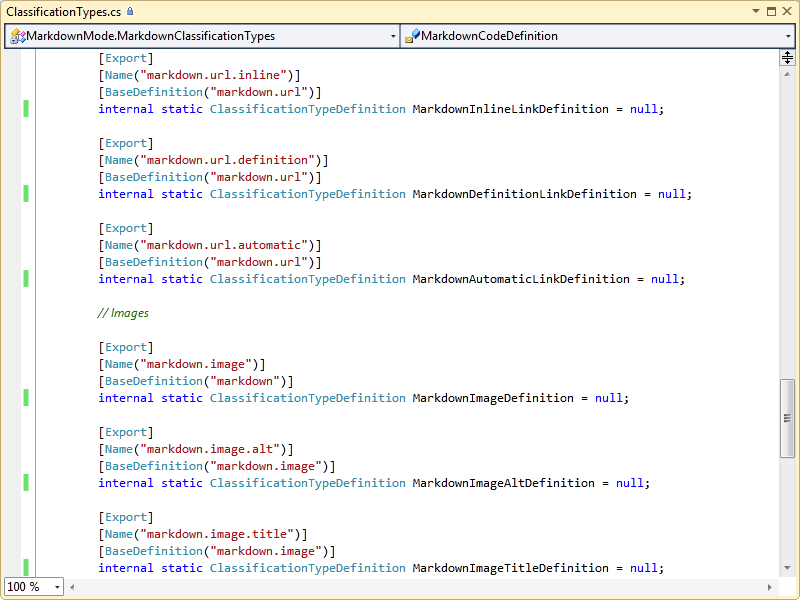
Here is where you list out the types of classifications you need. For Markdown, these will be things like links, headers, emphasis, and a few others.
Classification type definitions are the declarations for the names of these, along with the relationships to other classification type definitions. For example, the Markdown headers I've defined (markdown.header.h1 through markdown.header.h5) all have the same base type (markdown.header). This allows us, among other things, to apply formatting attributes to all markdown.headers and have those apply to the specific header types. It also allows anyone who wants to consume classified spans in a buffer to be either general (looking for all headers in the document) or specific (looking for just h2).
The file is kinda long, so here's a piece of it (whole file: ClassificationTypes.cs):
Classification format definitions contain the default information for how the text view should draw text that has been classified. You have control over quite a bit of how the text view (and, by extension, WPF) will render text; everything from the simple stuff, like foreground/background color (or brush), font, and font size, to TextDecorations and TextEffects. We're not going to be doing anything too fancy for Markdown; mostly just changing foreground colors, font size, bold/italic, and some underlines here and there.
This file is also pretty large. Here's a link to ClassificationFormats.cs, and here's just a small chunk:
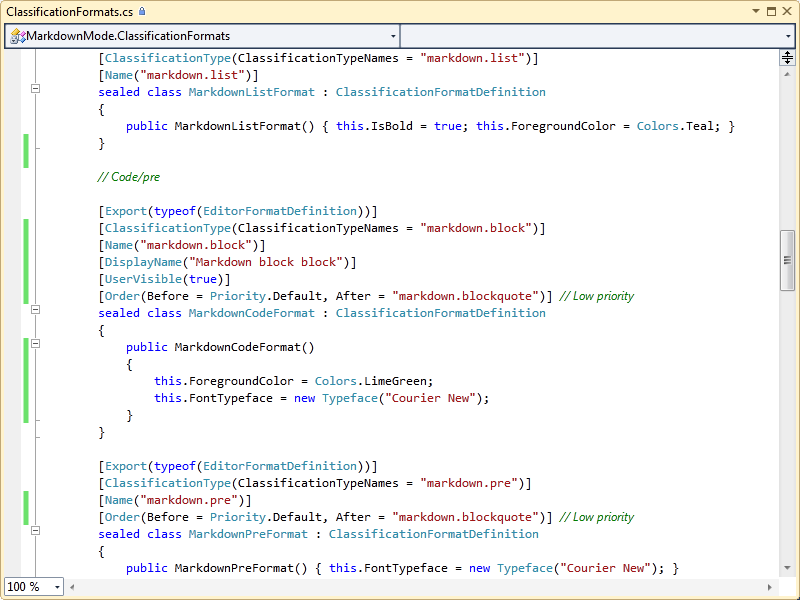
I specifically chose format definitions that have some optional attributes defined:
DisplayNameandUserVisible(true)– so the format definition shows up in fonts and colors. You won't be able to configure the typeface, but you should be able to change the foreground color. In general, it is a good idea to add these attributes to any format definitions that haveForegroundColor,BackgroundColor, orIsBolddefined (or any that you want users to be able to modify in this way). Oh, and there's a typo in the display name in the screenshot, so don't actually do that in your extension.Order– I made all the "blocks" lower priority than everything else, so other formats would override them.
The classifier
This actually ends up being the shortest and simplest, if you have a parser to do all the heavy lifting for you.
In our case, I wrote one (MarkdownParser.cs), though it is a bit of a beast (it doesn't even include the 200 lines of regular expressions it depends on, which are found in Markdown.cs). In any event, the classifier ends up basically calling out to the parser and turning whatever tokens it gets back into classifications.
The only small catch is what text is sent to the parser. While the view formats text one line at a time (and thus the classifier tends to see, at most, one line or substring of a line), a single line isn't enough context for the parser to get everything it needs to. Think of line continuations in VB, Linq expressions, or Markdown's title syntax that allows you to follow a line you want to be a title with ----- or =====.
So, to make this work, we send in paragraphs at a time. We search lines before and after the lines we've been asked about until we find blank lines (or the end of the file), and include all text in between. This is still better than reparsing the entire file on each press, and the total time to classify the average paragraph (like a list of 5 elements) is generally no more than 100 microseconds (which is one tenth of a millisecond), so not performance that we have to be too worried about.
This also means that when the user is typing, we may need to invalidate more than just the line being edited. By default, the classifier doesn't invalidate anything on text change (relying on the normal behavior where lines immediately around the text change are invalidated by consumers like the text view), but it does invalidate paragraphs if they contain tokens that span multiple lines. A good rule of thumb is that we don't want to dirty the view more than we need to; while invalidating entire paragraphs (or even the entire buffer) on each buffer change would certainly work, it would be expensive and cause the editor to slow down greatly over remote desktop.
The markdown parser (skip)
This isn't strictly related to editor extensibility, so I include this section only if anyone is curious. If you aren't, click here to skip past it.
The MarkdownParser.cs is basically just copies of the Do*Foo* and Run*Foo*Gamut methods in Markdown.cs, with the exception that they are all returning enumerations of Tokens and they never destroy the text in such a way as to invalidate Span coordinates from any of the generated Tokens.
The primary entry point is just ParseMarkdownParagraph, with another one named ParagraphContainsMultilineTokens that really only has use to the classifier (for determining how much text to invalidate when the user is typing).
Note that the parser is designed to parse a paragraph at a time and not necessarily the entire document, so that the classifier doesn't need to reparse the world on every text change. Also, the parser has left out certain pieces of the transform logic that it just doesn't care about, such as the more complicated handling of HTML tags/tokens and the dictionary of URLs for images/anchors to their definitions.
To give you an idea of what the parser methods look like, here's the code for ParseAnchors, which parses the various types of link entries (though not images):
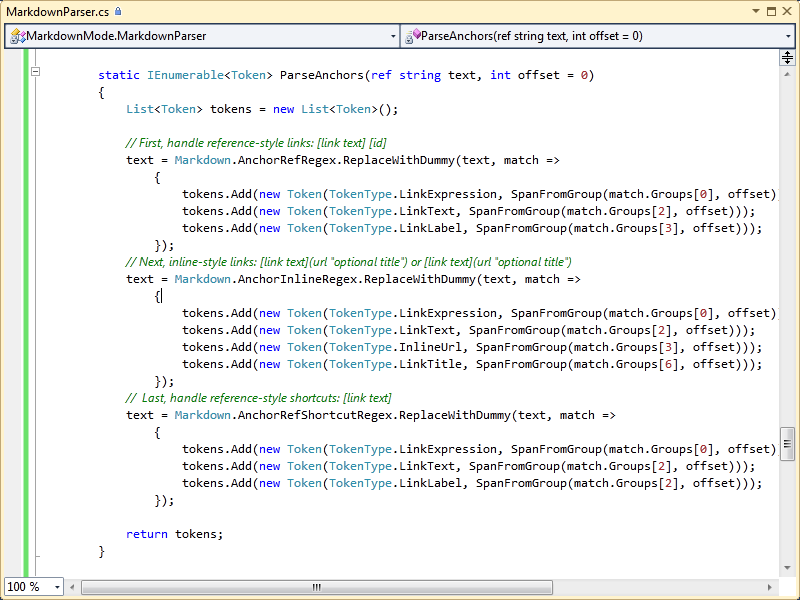
Although some of the methods get more complicated (like parsing lists and list elements) and some require recursive calls, it doesn't get too much more complicated than that.
Some thoughts about the Markdown implementation
For Markdown (and from the vim markdown-mode syntax highlighting I've used in the past), you can write a pretty quick, dirty, and simple classifier/parser by using just regular expressions. This is what John's original Markdown.pl script did, and the subsequent ports basically copied those regexes and the surrounding algorithms verbatim. However, the Markdown scripts were designed specifically to transform text from markdown-formatted text into HTML, not to glean information from the text itself. Because of this, they could take a very handy shortcut in dealing with ambiguous syntax in Markdown.
For example, if you put asterisks around part of a sentence, *like this*, it comes out italicized, like this. However, the asterisk can also be used for creating unordered lists (like a bullet point), so you have to be slightly careful when you have a sentence like:
* Is this italicized*, or is it just the start of a bullet and I left off the closing *?
(This is actually not an issue with the regexes Markdown.pl/Markdown.cs use, since the starting asterisk for italics has to be touching a non-whitespace character to the right and the asterisk for an unordered list element has to be followed by a space. Still, the point is that many "special" characters in Markdown are special in more than one context).
For the sake of the parser (and classifier), we don't want to destroy the text as we go along. Well, technically, we don't want to destroy the text in such a way as to invalidate the coordinates of the tokens we've parsed in the text, so that the information the parser has gleaned can be used by the classifier against the original text. So we can destroy the text, as long as all we're doing is replacing each character we want to skip over in later steps with another character that has no meaning to the rest of the Markdown parser. For the logic I wrote, I basically replace pieces of the text with a dummy character (I chose ~ for no real reason) after it has been parsed to completion. You can see that in the ParseAnchors method above in the ReplaceWithDummy extension method I added to Regex, and you end up translating things like:
This is `some code`
into:
This is ~~~~~~~~~~~
Final thoughts and next steps
The whole thing probably took about two Saturdays worth of time. At least ¼ of that was the false start in trying to write a Markdown classifier with just a list of regexes and some simple logic about which to skip if earlier ones were found (creating regexes for this stuff from scratch isn't that easy for me). After that, my overall time probably broke down to 50% each in the parser and classification format/type definitions, which the format definitions taking slightly longer than the type definitions. Those were actually the most annoying, because it is a lot of copy/paste/tweak (maybe a designer or other tool could be helpful there). That doesn't seem that bad for a feature like this, though I imagine that someone with actual experience writing parsers could knock out something for Markdown in half the time.
Despite the fact that I only have syntax coloring and none of the other features I'm thinking about, it already feels complete enough for normal usage. The screenshot at the top shows me editing this article (the list and the link definitions at the end of the article), and it wasn't that I opened up VS specifically for the screenshot. I really am typing this in VS right now!
So, here's my progress list (not very exciting so far, I know, but it feels nice to cross things out). I've also clarified the clickable hyperlinks step, since I want to make the URL labels into hyperlinks (the URLs themselves are already automatically detected as hyperlinks). Also, the syntax support for regular html was as easy as I had hoped; adding [BaseDefinition("HTML")] to the ContentTypeDefinition was all that was required, as you can see in the screenshot.
My next step will probably be showing the current output. At this point, it's the only real feature that I need to escape from VS to do; I have the file open in vim on the other side of the VM boundary (running in OS X), and I run the little vim script I wrote from there to generate the output and open it in a browser.
After that, I'm going to look into the spell checking support, since that's the other vim feature I'm missing most. Hopefully that one is a matter of me just finding an extension, since it really doesn't make sense as a part of Markdown mode (besides being a nice feature to have here).
So, here's the list:
Syntax coloring (the obvious one); things like bold, italics, links, pre blocks and code blocks, etc.- Turn URL labels into clickable hyperlinks – this is pretty easy to do with the new URL tagging support in the editor.
- Some parts of Intellisense – I'm thinking of doing smart tags for links (like turning what looks like a url into a correct markup link), completion for things like link definitions, and quick info for image references (if I don't do anything cooler for images).
- Inline images of some sort – this somewhat violates the principle of adding/removing things other than markup, so I'm not sure if I'll do this or not. It's certainly possible to do and not that difficult, but using quick info for this may be a sufficiently useful feature without getting into the business of putting images directly in the editor. Remember, just because you can do something doesn't necessarily mean that you should.
- A tool window for showing the current output (as a webpage) of the buffer I'm editing, updating live while I'm editing it. Alternatively, this may be just another document or a margin, depending on where I end up. I'm not very good at visual schtuff, so it'll probably be as simple as it can be and still get the job done.
Syntax support for regular html – Markdown lets you use intersperse regular html into your Markdown files, so it would be nice to get these to be correctly syntax highlighted. This may actually be really simple (just using aContentTypethat derives from html), but if it isn't, it isn't high on my list, mostly because I don't tend to use it for anything other than anchor tags.- Spell checking support – a couple people have built samples that do spell checking, so that would be nice to add, especially since I'm writing prose.
- Syntax support for code blocks – this would be kinda cool, though may be of limited utility since most of the code blocks I embed directly into my posts are very tiny, at most a few words. The larger blocks I tend to put somewhere like https://gist.github.com, so that they can be versioned and referenced to as an independent entity.