Choosing between Azure Event Hub and Kafka: What you need to know
Any organization/ architect/ technology decision maker that wants to set up a massively scalable distributed event driven messaging platform with multiple producers and consumers - needs to know about the relative pros and cons of Azure Event Hub and Kafka. This article will focus on comparing them - both qualitatively and quantitatively. If you already know a lot of Kafka or Event Hub, it will help you choose one for your need. If you have not yet played around with them, it will clear up a thing or two.
The slightly bigger question: PaaS versus IaaS
Before we jump into the relative merits and demerits of these two solutions, it is important to note that Azure Event Hub is a managed service, i.e., PaaS, whereas when you run Kafka on Azure, you will need to manage your own Linux VM-s, making it an IaaS solution. IaaS is more work, more control and more integration. It may, however, be worth it for your specific situation - but it is important to know when it is not.
Kafka scales very well - Linked-In handles half a trillion events per day spread across multiple datacenters. Kafka, however, is not a managed service. You can install Kafka and create a cluster of Linux VM-s on Azure, essentially choosing IaaS, i.e., you have to manage your own servers, upgrades, packages and versions. Though it is more convenient than having your own datacenters - because Azure offers you low click solutions for High Availability, Disaster Recovery, Load Balancing, Routing and Scaling Out, you still have to build your own systems to pipe real-time streaming data to offline consumers like Stream Analytics or Hadoop. You still have to manage storage (see how to handle storage when you run Kafka on Azure later in this article) and spend cycles maintaining a system instead of building functionality with them.
On the other hand, PaaS frees you from all such constraints. As a general rule, if a PaaS solution meets your functional needs and if its throughput, scalability and performance meet your current and future SLA-s, it is, in my opinion, a more convenient choice. In case of Azure Event Hub, there are several other factors like integration with legacy systems, choice of language/ technology to develop producers/ consumers, size of messages, security, protocol support, availability in your region, etc. which can come into play and we will look at these later in this article. PaaS versus IaaS debate is bigger and older than Kafka versus Even Hub - hence let us not spend much time there as it can distract us from the comparison at hand.
The Similarities
Kafka and Azure Event Hub are very similar to each other in terms of what they do. Both are designed to handle very large quantities of small messages driven by events. In fact, almost every common IT use case around us is driven by streams of events each producing some data, which, in turn, are consumed by downstream systems. Event streams in a retail system contain orders, shipments, returns etc. A bank account processes debits and credits. Financial systems process stock ticks, orders, etc. Web sites have streams of page views, clicks, and so on. Every HTTP request a web server receives is an event. Even an RDBMS database is the result of a series of transactions which are events. Any business can be thought of as a collection of producer systems generating events (hence data), and a collection of consumer systems which use that data by either transforming it (hence creating derived streams of data), or changing their state, or storing the data for offline/ batch processing (e.g., reporting or mining). Also, there are use-cases where the data being transmitted must be consumed in real time: Error Monitoring Systems, Security and Fraud Analysis Systems etc. need to consume event data in near real time.
Both Kafka and Azure Event Hub provide a highway for that real time data. Both provide mechanisms to ingest that data from producers (systems generating data aka publishers) and forwarding it to consumers (systems interested in that data aka subscribers). Both have solved the inherent complexities of acting as a messaging broker in elegant ways
Both have solved the reliability and messaging semantics problem (what to do with undelivered message, node failure, network failure, missed acknowledgments, etc.) robustly by introducing non-optional persistence (storage). Consumers read from an offset into a persisted stream of data which can be thought of as a log file with lines being appended to it. Gone are the complexities of the COMET generation - now a consumer can actually rewind or playback/ replay messages easily
In fact, persistent replicated messaging is such a giant leap in messaging architecture that it may be worthwhile to point out a few side effects:
-
Per-message acknowledgments have disappeared, and along with it the hoard of complexity that accompanies them (consumer can still acknowledge a particular offset stating that "I have read all messages up to this offset")
Both have benefited from arguably the most important by-product of this design: ordered delivery (used to be notoriously difficult in COMET days)
The problem of mismatched consumer speed has disappeared. A slow consumer can peacefully co-exist with a fast consumer now
Need for difficult messaging semantics like delayed delivery, re-delivery etc. has disappeared. Now it is all up to the consumer to read whatever message whenever - onus has shifted from broker to consumer
The holy grail of message delivery guarantee: at-least-once is the new reality - both Kafka and Azure Event Hub provides this guarantee. You still have to make your consumers and downstream systems idempotent so that recovering from a failure and processing the same message twice does not upset it too much, but hey - that has always been the case
Both had to deal with the potential problem of disk storage slowing performance down, but both came up with the simple but elegant solution of using only sequential File I/O, linear scans and big arrays instead of small bursts - tricks that make disk I/O, in some case, faster than even random access memory writes!
Both have solved the scalability problem by using partitions which are dedicated for consumers. By using more partitions, both the number of consumers as well as the throughput can be scaled and concurrency increased. Messages with the same key are sent to the same partition in both Kafka and Event Hub
Both have solved the problem of extensibility on the consumer side by using consumer groups
Both have solved DR by using Replication, but with varying degrees of robustness. Azure Event Hub applies Replication on the Azure Storage Unit (where the messages are stored) - hence we can apply features like Geo-Redundant Storage and make replication across regions a single click solution. Kafka, however, applies Replication only between its cluster nodes and has no easy in-built way to replicate across regions
Both offer easy configuration to adjust retention policy: how long messages will be retained in storage. With Azure Event Hub, multi-tenancy dictates enforcement of limits - with the Standard Tier service, Azure Event Hub allows message retention for up to 30 days (default is 24 hours). With Kafka, you specify these limits in configuration files, and you can specify different retention policies for different topics, with no set maximum
The Differences
The biggest difference is, of course, that Azure Event Hub is a multi-tenant managed service while Kafka is not. That changes the playing field so much that some that I know do argue - we should not be comparing them at all! It does not make them apples and oranges - but may be Hilton and Toll Brothers. Both Hilton (the reputed hotel chain) and Toll Brothers (the well known home builders) can provide you a place to stay with all utilities and appliances - but one of them builds their stuff keeping multi tenancy in mind, the other one does not. That makes a huge difference in optimization focus areas.
As a customer, what would you love about living in a Toll Brothers home? The degree of control you can exercise, of course! You could paint it pink if you wanted (if you can win the battle with the HOA that is). You could get the most advanced refrigerator that money can buy. You could hire as many chefs as you wanted to make you as much food as you want - without fear of being throttled by room service because you are stepping on the resources kept aside for other tenants. You could design your kitchen and its appliances the way you want - like have a water line run to the refrigerator nook so that ice makers and filtered drinking water faucets could work in it.
As a customer, what would you love about Hilton (the multi tenant solution)? The service of course! Fresh towels delivered at your doorstep. Rooms cleaned. Dishes washed. Then there are the subtle ones: if for some reason your particular suite is unusable, they can immediately put you up in another - and a visiting friend will have no trouble finding you in either suite because they will ask the front desk first (High Availability built into it). If the refrigerator in the suite decides to quit with perishable food items in it, they can bring another refrigerator before the food is unusable (Disaster Recovery built in - okay, that example was not right for DR - it is hard to come up with a DR analogy in real life. Only if you could make backup copies of your passports and jewelry in separate bank vaults, you could use that analogy - but you can't). If you invite 20 guests over, you could pick up the phone and rent 5 more equally or more comfortable suites. Stop paying for them when the weekend is over - scalability built right into it (both scale out and scale up).
At the end of the day, you need to ask yourself: what degree of control do I need? The analogy between Hilton and Azure Event Hub is not perfect because Hilton is always more costly than living at your own home. However, Azure Event Hub costs you less than $100 for 2.5 billion 1 KB events per month. Kafka, on the other hand, is open source and free - but the machines it runs on are not. The people you hire to maintain those machines are not. It almost always costs you more than Azure Event Hub.
Enough of that - we got dragged back into the PaaS and IaaS debate. Let us focus on some more technical differences.
On-premises support: Azure Event Hub cannot be installed and used on-premises (unlike its close cousins, the Service Bus Queues and Topics, which can be installed on-premises when you install Azure Pack for Windows Server). Kafka, on the other hand, can be installed on-premises. Though this article is about the differences between Azure Event Hub and Kafka running on Azure, I thought that I should point this one out
Protocol Support: Kafka has HTTP REST based clients, but it does not support AMQP. Azure Event Hub supports AMQP
Coding paradigms are slightly different (as is to be expected). In my experience, only the JAVA libraries for Kafka are well maintained and exhaustive. Support in other languages exist, but are not that great. This page lists all the clients for Kafka written in various languages.
Kafka is written in Scala. Therefore, whenever you have to track the source code down from the JAVA API wrappers, it may get very difficult if you are not familiar with Scala. If you are building something where you need answers to non-standard questions like can I cast this object into this data type, and you need to look at the Scala code, it can hurt productivity
Azure Event Hub, apart from being fully supported by C# and .NET, can also use the JAVA QPID JMS libraries as client (because of its AMQP support): See here.
As QPID has support for C or Python as well, building clients using these languages is easy as well.
REST support for both means we can build clients in any languages, but Kafka prefers JAVA as the API language
Disaster Recovery (DR) - Azure Event Hub applies Replication on the Azure Storage Unit (where the messages are stored) - hence we can apply features like Geo-Redundant Storage and make replication across regions a single click solution.
Kafka, however, applies Replication only between its cluster nodes and has no easy in-built way to replicate across regions. There are solutions like the GO Mirror Maker Tool which are additional software layers needed to achieve inter-region replication, adding more complexity and integration points. The advice from Kafka creators for on-premises installation is to keep clusters local to datacenters and mirror between datacenters.
Kafka uses Zookeeper for Configuration Management. ZK is actually known for its lack of proper multi-region support. ZK performs writes (updates) poorly when there is higher latency between hosts (and spread across regions means higher latency).
For running Kafka on Azure VM-s, adding all Kafka instances to an Availability Set is enough to ensure not losing any messages, effectively eliminating (to a large degree) the need for Geo-Redundant Storage Units - as 2 VM-s in the same Availability Set are guaranteed to be in different fault and update domains, Kafka messages should be safe from disasters small enough to not impact the entire region
High Availability (HA) and Fault Tolerance - Until the point the whole region or site goes down, Kafka is highly available inside a local cluster because it tolerates failure of multiple nodes in the cluster very well. Again, Kafka's dependency on Zookeeper to manage configuration of topics and partitions means HA is affected across globally distributed regions.
Azure Event Hub is Highly Available under the umbrella Azure guarantee of HA. Under the hoods, Event Hub servers use replication and Availability Sets to achieve HA and Fault Tolerance.
It may be worth mentioning in this regard that Kafka's in-cluster Fault Tolerance allows zero downtime upgrades where you can rotate deployments and upgrade one node at a time without taking the entire cluster down. Azure Event Hub, it goes without saying, has the same feature with the exception that you do not have to worry about upgrades and versions!
Scalability - Kafka's ability to shard partitions as well as increase both (a) partition count per topic and (b) number of downstream consumer threads - provides flexibility to increase throughput when desired - making it highly scalable.
Also, the Kafka team, as of this article being written, is working on zero downtime scalability - using the Apache Mesos framework. This framework makes Kafka elastic - which means Kafka running on Mesos framework can be expanded (scaled) without downtime. Read more on this initiative here.
Azure Event Hub, of course, being hosted on Azure is automatically scalable depending on the number of throughput units purchased by you. Both storage and concurrency will scale as needed with Azure Event Hub. Unlike Event Hub, Kafka will probably never be able to scale on storage - but again these are exactly the kind of points that go back to the point where Kafka is IaaS and Event Hub is PaaS
Throttling - With Azure Event Hub, you purchase capacity in terms of TU (Throughput Unit) - where 1 TU entitles you to ingest 1000 events per second (or 1 MBPS, whichever is higher) - and egress twice that. When you hit your limit, Azure throttles you evenly across all your senders and receivers (.NET clients will receive ServerBusyException). Remember that room service analogy? You can purchase up to 20 TU-s from the Azure portal. More than 20 can be purchased by opening a support ticket.
If you run Kafka on Azure, there is no question of being throttled. Theoretically, you can reach a limit where the underlying storage account is throttled, but that is practically almost impossible to reach with event messaging where each message is a few kilo bytes big, and there are retention policies in place.
Kafka itself lacks any throttling mechanism or protection from abuse. It is not multi-tenant by nature, so I guess such features must be pretty low in the pecking order when it comes to roadmap
Security - Kafka lacks any kind of security mechanism as of today. A ticket to implement basic security features is currently open (as of August 2015: https://issues.apache.org/jira/browse/KAFKA-1682). The goal of this ticket is to encrypt data on the wire (not at rest), authenticate clients when they are trying to connect to the brokers and support role based authorizations and ACLS.
Therefore, in IoT scenarios where (a) each publishing device must have its own identity and (b) messages must not be consumed by non-intended receivers, Kafka developers will have to additionally build in complicated security instruments possibly built into the messages themselves. This will result in additional complexity and redundant bandwidth consumption.
Azure Event Hub, on the other hand, is very secure - it uses SAS tokens just like other Service Bus components. Each publishing device (think of an IoT scenario) is assigned a unique token. On the consuming side, a client can create a consumer group if the request to create the consumer group is accompanied by a token that grants manage privileges for either the Event Hub, or for the namespace to which the Event Hub belongs. Also, a client is allowed to consume data from a consumer group if the receive request is accompanied by a token that grants receive rights either on that consumer group, or the Event Hub, or the namespace to which the Event Hub belongs.
The current version of Service Bus does not support SAS rules for individual subscriptions. SAS support will be added for this in the future
Integration with Stream Analytics - Stream Analytics is Microsoft's solution to real time event processing. It can be employed to enable Complex Event processing (CEP) scenarios (in combination with EventHubs) allowing multiple inputs to be processed in real time to generate meaningful analytics. Technologies like Esper and Apache Storm provide similar capabilities but with Stream Analytics you get out-of-the-box integration with EventHub, SQL Databases, Storage, which make it very compelling for quick development with all these components. Moreover, it exposes a query processing language which is very similar to SQL syntax, so the learning curve is minimal. In fact, once you have a job created, you can simply use the Azure Management portal to develop queries and run jobs eliminating the need for coding in many use cases.
Once you integrate Azure Event Hub with Azure Stream Analytics, the next logical step is to use Azure Machine Learning to take intelligent decisions based on that Analytics data.
With Kafka, you do not get such ease of integration. It is, of course, possible to build such integration, but it is time consuming
Message Size: Azure Event Hub imposes an upper limit on message size: 256 KB, need for such policies of course arising from its multi-tenant nature. Kafka has no such limitation, but its performance sweet spot is 10 KB message size. Its default maximum is 1 MB.
In this regard, it is worth mentioning that with both Kafka and Azure Event Hub, you can compress the actual message body and reduce its size using standard compression algorithms (Gzip, Snappy etc.).
Another word of caution in this regard: If you are building an event driven messaging system, the need to send a massive XML or JSON file as the message usually indicates poor design. Therefore, when comparing these two technologies for message size, we should keep this in mind - the well designed system is going to exchange small messages less than 10 KB in size each
Storage needs: Kafka writes every message to broker disk, necessitating attachment of large disks to every VM running Kafka cluster (see here on how to attach a data disk to Linux VM). See Disaster Recovery above to understand how stored messages can be affected in case of disaster.
For Azure Event Hub, you need to configure Azure Storage explicitly from the publisher before you can send any messages. 1 TU gives you 84 GB of event storage. If you cross that limit, storage is charged at the standard rate for blob storage. This overage does not apply within the first 24 hour period (if your message retention policy is 24 hours, you can store as much as you want without getting charged for storage).
Again a design pointer here: a messaging system should not be doubling as a storage system. The current breed of persistent replicated messaging systems have storage built into itself for messaging robustness, not for long term retention of data. We have databases, Hadoop and No SQL solutions for such - and all these could be consumers of the Event Hub you use, enabling you to erase messages quickly but still retain their value
Pricing and Availability: For running Kafka on VM-s, you need to know this: https://azure.microsoft.com/en-us/pricing/details/virtual-machines/
For using Azure Event Hub, you need to know this (has link to pricing page at the top): https://azure.microsoft.com/en-us/documentation/articles/event-hubs-availability-and-support-faq/Performance: Now that we are down to comparing performance, I must go back to my managed multi-tenant service pitch first. You need to know that you are not comparing apples to apples. You can run a massive test on Kafka, but you cannot run it on Azure Event Hub: you will be throttled!
There are so many throughput performance numbers on Apache Kafka out there, that I did not want to set another up and offer more of the same thing. However, in order to compare Azure Event Hub and Kafka effectively, it is important to note that if you purchase 20 TU-s of Event Hub, you will get 20,000 messages ingested per second (or 20 MBPS of ingress, whichever is larger). With Kafka, this comparison concludes that a single node single thread achieves around 2,550 messages/second and 25 sending/ receiving threads on 4 nodes achieve 30K messages/second.
That makes the performance comparable to me, which is very impressive for Event Hub, as it is still a multi-tenant solution, meaning each and every tenant is getting that performance out of it! This, however, needs to be proved and I have not run multi-tenant tests simultaneously.
A point to note about the famous Jay Kreps test is that the message size there used is 100 bytes. Azure Event Hub guarantees 20,000 messages/second or 20 MBPS ingress to someone who has purchased 20 TU-s: that tells us that the expected message size is 1 KB. That is a 10 times difference in message size.
However, I did run single tenant test and tested something different: how long does a message take to reach the consumer? This approach provides a new angle to performance. Most test results published on the internet deals with throughput of ingestion. Therefore, I wanted to test something new and different.
Before discussing the results, let me explain an inherent inequality in these tests. The latency numbers here are of end-to-end message publishing and consumption. While in the case of Event Hub, the three actors (publisher, highway and consumer) were separated on the network - in case of Kafka, all three were on the same Linux Azure VM (D4 8 core).
With that, let us compare the results:
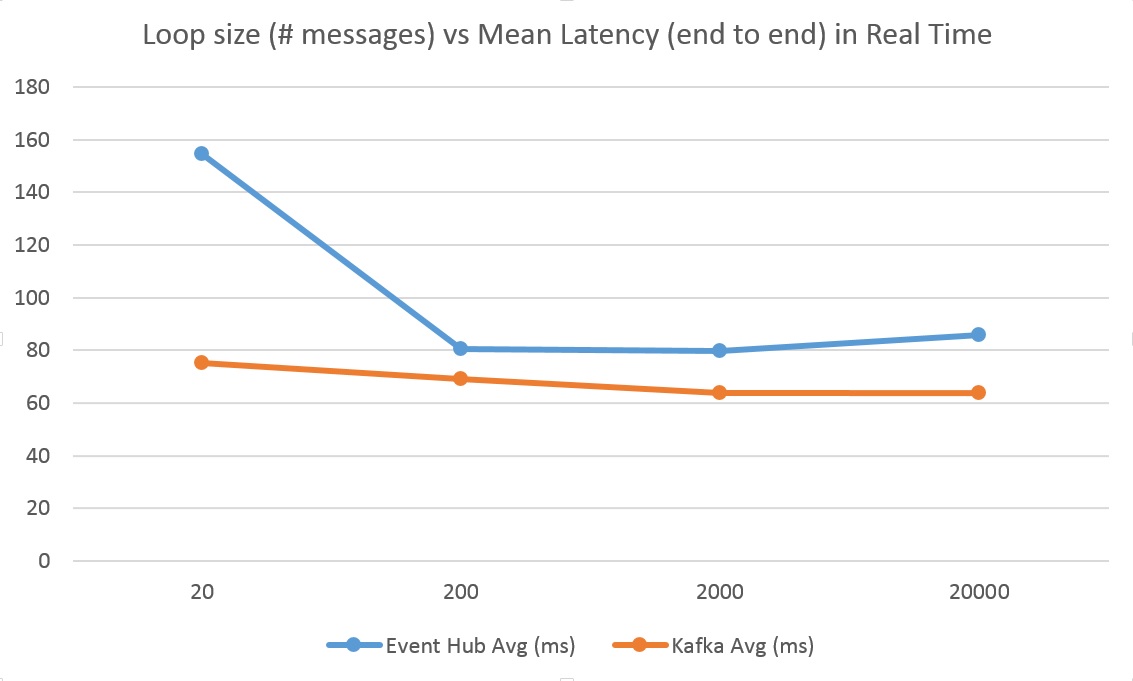
In spite of the fact that the Azure Event Hub end-to-end test involved multiple network hops, the latency was within a few milliseconds of Kafka (whereas the messages were traveling within the boundaries of the same machine in case of Kafka).
In essence, what I have measured shows no difference between the two. I am more convinced that Event Hub, in spite of being a managed service, provides a similar degree of performance compared to Kafka. If you add all the other factors to the equation, I would choose Azure Event Hub over running Kafka either on Azure or my own hardware.
Other Players
Kafka and Azure Event Hub are not the only players in the persistent replicated message queues space. Here are a few others:
Mongo - Mongo DB has certain features (like simple replication setup and document level atomic operations) that can let you built a persisted replicated messaging infrastructure on top of it. It is not highly scalable, but if you are already using MongoDB, you can use this without needing to worry about a separate messaging cluster. However, like Kafka, Mongo lacks inter-region replication ease
SQS - Amazon has a managed queue-as-a-service, SQS (Simple Message Queue) providing at-least-once delivery guarantee. It scales pretty well, but supports only a handful of messaging operations
RabbitMQ - Provides very strong persistence guarantees, but performance is mediocre. Rabbit uses replication and partitions; it supports AMQP and is very popular. Like Azure Event Hub, RabbitMQ has a web based console (in my opinion this is a big contributor to its popularity). It is possible to build a globally distributed system where replication is happening across regions. However, replication is synchronous-only, making it slow - but the designers traded some performance for certain guarantees, so this is as-designed
ActiveMQ - Unlike Rabbit, Active has both synchronous and asynchronous replication, and is a good choice if you are married to JMS API-s. Performance-wise, Active is better than Rabbit, but not by much
HornetQ - Very good performance but Hornet has open replication issues, and under certain circumstances (certain order of death), data may get corrupted across nodes. Very good choice if fault-tolerance is not the highest priority. It has a rich messaging interface and set of routing options
ZeroMQ - ZeroMQ is not a real messaging queue, neither is it replicated/ persistent. Though it does not belong to this elite group at face value, it is possible to build such a system using ZeroMQ, but that will be a lot of work!
Conclusion
In my opinion, it can safely be said that Azure Event Hub provides a better out-of-the-box solution for durable fault tolerant distributed persistent replicating messaging framework for most use cases. Is it practical to build a LinkedIn with it? Probably not, as that would be costly, as you will need to buy too many TU-s. At 5 million events per second, only a specialized data center instance can handle that volume. Technology-wise, the underlying Event Hub implementation will be able to handle it if we deployed it on a dedicated data center, but Event Hub is not meant for that kind of use case.
I will be happy to update any particulars if you leave comments!