How It Works: SQL Server 2005 Connection and Task Assignments
I have talked about how connections and tasks get assigned as PASS and during many other mentoring opportunities. I just finished working on an issue that forced me to dig deeper into the subject.
The customer reported that on a NUMA machine the connections are always getting assign to the same node. They had determined this by looking at the CPU usage information and the node_affinity assignments.
select endpoint_id, node_affinity, * from sys.dm_exec_connections
To set the stage the basic rules for connection to node assignments are.
- Use only the nodes the port affinity indicates. (See SQL Server Books Online for port to node binding details.)
- Do round-robin connection assignment among the available nodes. This takes into account the port affinity binding as well as the online status of the node. (A node is considered offline when all schedulers are offline).
After more investigation I found that these rules need to be tempered with an endpoint discussion.
select * from sys.endpoints
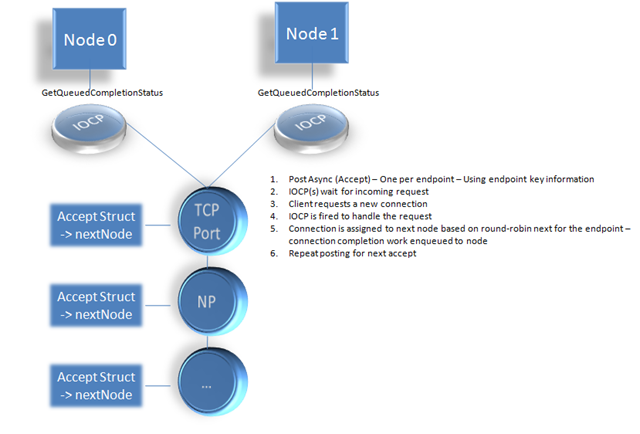
- When the SQL Server is started it establishes the listen on endpoints.
Each endpoint results in an internal endpoint structure. For the diagram above there would be an endpoint tracking the TCP Port, one tracking the Named Pipe and perhaps others for shared memory, and additional TCP ports. This structure contains the OVERLAPPED members as well as a nextNode member.
Each node has an I/O completion listener (GetQueueCompletionStatus) that all endpoints and communication channels are associated with.
As the diagram shows each endpoint posts an async accept using its associated accept structure. One of the IOCP listener threads is invoked (OS determined) during an connection request. The IOCP does the minimum accept logic then looks at the nextNode information. Incrementing the nextNode (round robin logic) the IOCP thread queues the request to the desired node to complete login processing.
The accept structure is again used to post an async accept request for the designated endpoint.
Thus, the message is tempered by round-robin assignments within each endpoint and not across all endpoints. It is possible to make a TCP connection followed by a Named Pipe connection and get connection affinity assignments to the same node.
Connect / Disconnect
Be careful when evaluating the assignments as some applications establish a couple of connections during initialization and disconnect all but one of them. This can make it look like the connection affinity is not working properly. Reviewing the pattern of connect and disconnects in a SQL trace along with understanding the endpoint used provides the proper insight.
Scheduler Assignments
Once the connection affinity is established a scheduler is selected.
- Only schedulers within the node are considered
- Only online schedulers are considered
- Only task counts are considered (task activity/weight is not a consideration)
- Scheduler assignment task place when the task is created
- Scheduler assignment binding remains in affect until the task completes.
Note: Task can often be thought of as a batch. Each batch is a new task request to server.
During initial connection the scheduler with the lowest number of tasks is selected. This scheduler becomes the preferred scheduler for the connection. Keeping the connection on the same node and when possible on the same scheduler helps maintain resource locality and increase performance capabilities.
After the connection is established incoming tasks for the session start by looking at the preferred scheduler. As long as the preferred scheduler does not have a task count ~20% larger than the other available schedulers on the node the preferred scheduler is used. If the threshold is exceeded the scheduler with the smallest task count is used.
Parallel Queries
Parallel queries bring a bit of a twist to the scheduler assignments. The controlling task (think of this as your connection) always follows the scheduler assignment rules just described.
The design is to keep all parallel threads within the same node when possible. It does not matter if this is the same node as the controlling task. Keeping all the parallel workers within the same locality increases performance significantly.
When a parallel query starts it looks at the number of available workers on each node. The node with the most available workers is selected as the node to queue the parallel worker to. So you could have Port A bound to only Node 0 but the query runs on Node 1 when run in parallel.
The other caveat with parallel query startup is that the SQL Server engine only looks at the available worker counts once per second. So in rare situations it is possible for multiple connections to start parallel queries and they end up on the same node when you might expect them to use separate nodes.
Bob Dorr
SQL Server Senior Escalation Engineer