Compressing an SAP database using report MSSCOMPRESS
- This blog has been re-published at https://techcommunity.microsoft.com/t5/Running-SAP-Applications-on-the/Compressing-an-SAP-database-using-report-MSSCOMPRESS/ba-p/367046
- This blog post might be outdated by now. The latest documentation regarding SQL Server Columnstore on SAP is available in https://www.sap.com/documents/2019/04/023e5928-487d-0010-87a3-c30de2ffd8ff.html
SAP released the report MSSCOMPRESS in SAP note 1488135. The report can be used to compress existing tables and indexes using the data compression feature of SQL Server 2008 (and all newer releases). You can choose between the compression type NONE, ROW or PAGE for the data (heap or clustered index) and the (non-clustered) indexes. MSSCOMPRESS performs the compression in dialog or using an SAP batch job. MSSCOMPRESS is particularly useful for two scenarios:
- Compressing (non-clustered) indexes after activating the index compression support for SAP as described in SAP note 1488135
- Re-compressing a SAP Unicode database in order to benefit from the improved Unicode compression of SQL Server 2008 R2
By releasing MSSCOMPRESS, the stored procedure sp_use_db_compression has become deprecated (see https://blogs.msdn.com/b/saponsqlserver/archive/2010/03/17/updated-version-of-sp-use-db-compression-version-2-42.aspx).
Prerequisites
If the report MSSCOMPRESS was not already imported into your SAP system by a basis support package, you have to import it manually. The details are described below.
MSSCOMPRESS can only be used for SQL Server 2008 or newer. You need the same privileges to use MSSCOMPRESS as you need for the SAP database utility SE14 (authority object S_DEVELOP).
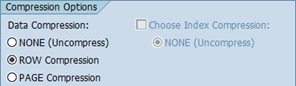
Before using MSSCOMPRESS you should implement the correction instructions of SAP note 1459005. This will activate the index compression support in the SAP data dictionary. As long as the SAP data dictionary is not up-to-date you can only compress the data (heap or clustered index) using MSSCOMPRESS. 
{kind=link}
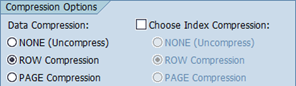
Once you have applied SAP note 1459005, you can compress data and (non-clustered) indexes using the report MSSCOMPRESS. 
{kind=link}
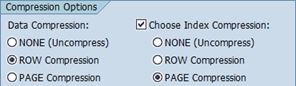
The default compression type for report MSSCOMPRESS is taken from the default compression type of the SAP data dictionary. The index compression type is in sync with the data compression type. However, you can choose the index compression type manually by checking the according checkbox: 
{kind=link}
Starting MSSCOMPRESS
Use SAP transaction SA38 or SE38 to start the ABAP report MSSCOMPRESS.  To get a brief description of MSSCOMPRESS, press the “i” button or choose “Application Help” from the “Help” menu. In the following, MSSCOMPRESS is described in detail.
To get a brief description of MSSCOMPRESS, press the “i” button or choose “Application Help” from the “Help” menu. In the following, MSSCOMPRESS is described in detail. 
In the lower section of the screen, a list of all database tables of your SAP ABAP system is displayed. The list does not include tables of an installed JAVA schema, since the data dictionary for JAVA does not support compression. There are SAP JAVA solutions which have huge database tables, for example the SAP Enterprise Portal (EP). However, almost all data in an EP system is stored in fields of SQL Server data type IMAGE or VARBINARY(MAX). These data types cannot be compressed in SQL Server 2008 (R2) anyway.
The list of tables displayed in MSSCOMPRESS contains the number of indexes, the data/index size and the data/index compression types for each table. The tables in the list are sorted by total size (data + index size). The number of indexes does not contain the clustered index. A clustered index (or primary key constraint) is considered to be DATA and all non-clustered indexes are INDEXES. The data compression type can be “ROW”, “PAGE” or “none”. For a partitioned table you may see a combined compression type, for example “ROW, PAGE”. This is the case, if some partitions are row compressed and some partitions of the same table are page compressed. The same applies for the index compression type. When a table does not have any non-clustered index, then the number of indexes is shown as 0 and the index compression type is empty (“ “).
Workflow Overview
To start the compression you have to perform 3 steps:
- Choose the tables you want to compress (by filtering and selecting)
- Choose the options (compression types and runtime options)
- Choose the type of compression run (dialog or batch)
Compressing huge tables may result in high resource consumption (CPU, I/O, temporary data space, transaction log space, blocking database locks). Therefore you should make sure that sufficient space is available during the compression using MSSCOMPRESS. Furthermore, the compression should not run during peak hours. It is recommended to use the SQL Server recovery model "Bulk-logged" during compression in order to minimize the transaction log space needed.
You can also compress the SAP database in chunks. For example, you may choose the 10 largest non-compressed tables using the filters in MSSCOMPRESS and schedule the compression for the weekend. The other tables can then be compressed during the next weekend(s).
Choosing the tables
To choose the tables, you want to compress, you can first filter the list of tables and then select the tables within the filtered list. Applying a filter modifies the displayed list of tables. You can apply multiple filters at the same point of time. In the following example all four possible filter types are applied: 
After applying these filters, the list contains the 10 largest tables, whose name starts with “/BI”, data compression is “ROW” and index compression is “none”. You can then further select the tables within the filtered list by clicking on them. Use the SHIFT and CTRL keys while clicking in order to expand your selection. In this example, three tables are selected: 
Choose the empty entry from the pop-up menu in order to remove a filter again. The name filter works a little bit different. You can enable and disable the name filter using the check box. Per default, the filter criteria is “/BI*”, which filters all SAP BW tables. After changing the filter criteria you have to press the ENTER key (or the ENTER button on the right-hand side of the filter criteria). 
Choosing the options
The compression options define the desired compression type of the tables after the compression run. Do not confuse them with the filter options “Data Compression Type” and “Index Compression Type”. They are used to choose the tables, which should be compressed. The filter options apply to the compression type of a table before the compression run.
You can choose the desired data and index compression type using the radio buttons. The SQL statement used for compression is
ALTER [TABLE| INDEX] … REBUILD WITH (DATA_COMPRESSION = [ROW | PAGE | NONE] …)
Before actually compressing, MSSCOMPRESS checks the current compression type for each table and index. If the current compression type fits the desired compression type then nothing is done for the concerned index. However, you can force to compress these tables and indexes independent from the current state by choosing the according checkboxes (“Force Data Rebuild” and “Force Index Rebuild”). These options are needed, if you want to compress an already compressed table again. This is particularly useful after upgrading SQL Server 2008 to SQL Server 2008 R2, in order to benefit from the compression improvements for Unicode strings. 
MSSCOMPRESS automatically removes the vardecimal storage format of a table when compressing it. You may change this in the menu “Goto” => “Advanced Options”. However, we do not see the advantage of changing this default behavior.
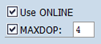
The compression options have an impact on the result of the compression run. There are two options which have an impact on the compression run itself: 
{kind=link}
You can configure the maximum number of threads used to execute a single SQL statement with the SQL Server configuration option max degree of parallelism. For an SAP system, this is typically set to 1. To overwrite this configuration for the compression run, set the checkbox “MAXDOP” and enter a value greater than 1. MSSCOMPRESS compresses table by table and index by index. It does not compress multiple tables at the same point in time, even of “MAXDOP” is set. If you want to compress many tables in parallel then you should schedule a few compression runs of distinct tables for the same period. The benefit of parallel compression runs depends on your hardware resources.
When setting the checkbox “Use ONLINE”, the database compression does not acquire table locks, which results in better concurrency. However, this does not work for some tables, for example tables having a text or image field. If you have set the checkbox, then the compression fails for these particular tables. MSSCOMPRESS automatically repeats the failed compression without using the online option.
Generally speaking, the online option makes sense when compressing a few tables in dialog during normal working hours. It does not make sense when compressing many tables in a batch job during off-peak hours.
Starting the compression
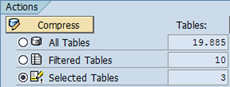
Use the radio buttons to choose, what you want to compress. Per default, all selected tables are compressed. You may also choose the filtered tables (all tables displayed in the list) or all tables (of the ABAP schema). 
{kind=link}
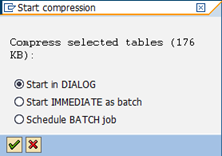
When pressing the “Compress” button, a dialog box occurs. Here you can choose whether you want to start the compression run in dialog, start it immediately as a batch job, or schedule a batch job for off-peak hours. 
{kind=link}
When compressing in dialog, a progress indicator is displayed at the lower left corner of the window. Once the compression run has finished, the compression type and data/index size is refreshed in the list of tables. Afterwards the current filter is applied again. The selected tables are still selected, which makes it easier to see the result of the compression run. However, this may not be the case when using filters, for example the filter option “Row-compressed”. After page-compressing a row-compressed table, the filtered list does not contain the table anymore (because the filter criteria does not apply for this table anymore). 
{kind=link}
Once you have started a compression run as a batch job, you can see the job status in the main screen of MSSCOMPRESS. However, you have to update the job status manually by pressing the button on the right-hand side of the job status field. 
{kind=link}

When using a batch job, compression types and data/index size in the list of filtered tables will not be updated automatically. However, you can do this manually by pressing the “Refresh” button. 
{kind=link}
Checking the log files
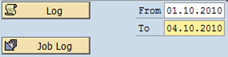
MSSCOMPRESS creates a compression log for each table or index compression. It is not stored as a file. It uses the standard SAP Application Log. You can display the compression logs by pressing the “Log” button. Per default only the logs from the current day are displayed. However, you may change the from-date and to-date before starting the application log. 

{kind=link}
If the compression is running in an SAP batch job, a job log is also written. Press the “Job Log” button to get the standard job selection screen of SAP. Here you can check the status and job log of any SAP batch job. 
You can read the job log while the job is still running. The job contains entries about the progress of the whole job (“… compressed 15% …”). The progress is calculated by the size of already compressed tables compared to the size of all tables, which are scheduled for compression. In order to save space in the database, MSSCOMPRESS always starts the compression with the smallest tables of the compression run. Therefore there seems to be only a very small progress, after the first tables have already been compressed. 
Importing the transport of MSSCOMPRESS
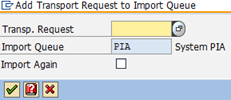
If the report MSSCOMPRESS was not already imported into your SAP system by a basis support package, you have to import it manually. This should be done by the SAP basis administrator. First of all you have to unzip the cofile (Kxxx.SID) and data file (Rxxx.SID) of the transport, which is attached to SAP note 1488135. Then copy the files to the cofiles (usr\sap\trans\cofiles\) and data directory (usr\sap\trans\data\). The next step is to add the request to the import queue in SAP transaction STMS. 

{kind=link}
Use the F4 help for field Transport Request to choose your transport. 
{kind=link}
Select the Request (SIDKxxx) and press the button “Import Request” 
{kind=link}
For SAP releases 720 and newer you may have to choose the import option “Ignore Invalid Component Version”. 
Dependent on the SAP release, this procedure might be slightly different. Your SAP basis administrator should be aware of the details.
Known issues
When pressing the “Compress” button, you may see the following warning: 
You can simply ignore this warning by pressing OK. It has no impact at all. The root cause of this warning is not an issue of the report MSSCOMPRESS. It is a known bug in the SAP Kernel and fixed by SAP note 1309615. After applying the newest SAP kernel patch you will no longer see this warning.