Improving Latency in Http Proxy scenario
Stream to stream copying is a scenario that is not straightforward to implement. It is especially important in a Proxy scenario.
Proxy
Let’s start from the beginning. What is a proxy?
A server that acts as an intermediary for requests from clients seeking resources from other servers (Wikipedia)
There are many reasons why you would want to have a Proxy server. The intermediary can add value to the request or to the response. For example it can make sure your backend server is not getting too many requests. It can also add caching so that your backend server is not even called. Other examples of value add are: security, compression, encryption, load balancing, etc.
For the past few months I've been helping out a team in Microsoft that has one of these services.
As you can imagine it is critical that we ensure that the response is being delivered to the user as fast as possible. We call this response time latency. In a proxy scenario it is very important it is as low as possible because the backend is the one doing most of the work. The proxy should be a thin layer.
The default implementation of a proxy would be something like this:
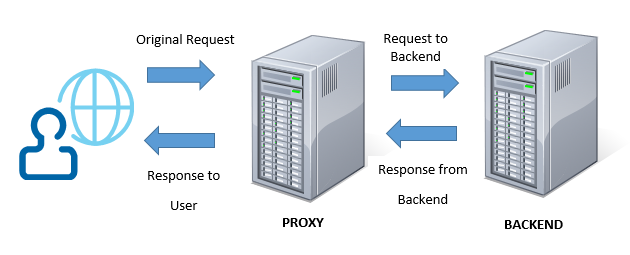
1) The Proxy receives the request
2) The Proxy makes a request to the backend
3) The Proxy gets the response from the backend
4) The Proxy passes this response back to the user.
So the Proxy will have two streams for each request. One stream for the Backend Response and one stream for the Proxy Response that we are generating. And as we discussed above it should be copying data from the origin (Backend response) to the destination (Proxy response) as fast as possible.
The default way to copy data from one stream in .Net is something like this:
await backendContent.CopyToAsync(context.Response.OutputStream);
This implementation has a few flaws:
1) It allocates too much. Like I’ve mentioned before Stream.CopyTo allocates an 80k buffer each time it is called. So the proxy would be allocating an 80k buffer regardless of the stream size for each request! This might not be a problem if it’s something that you only do once every month. But for a Proxy server this is not acceptable. Too much memory pressure.
There is a version of CopyToAsync that allows you to control the buffer size:
await backendContent.CopyToAsync(context.Response.OutputStream, _readChunkSize);
2) The problem with this method overload is that you need the ability of passing your own buffer. Otherwise every request will allocate memory. You need to be able to pool memory so that you don’t allocate too much. See my previous blog on how to do that.
There is another problem with both implementations.
3) They are slow
Let’s measure the 3rd point. I grabbed a couple of Azure VMs and did this:
1) Deploy Backend in Azure West (All it does is return a file with an arbitrary size)
2) Deploy Proxy in Azure East (All it does is call backend and return the same body)
3) Call Proxy from my dev box.
I used Fiddler to call my Proxy and measured how long it takes to download a 50MB file through it:
Overall Elapsed: 0:00:24.021
It takes more than 20 seconds to download a 50 MB file. We’ll see how much we can improve this.
Reason of the problem
Let’s look at the implementation of Stream.CopyTo (which calls CopyToAsync:
private async Task CopyToAsyncInternal(Stream destination, int bufferSize, CancellationToken cancellationToken)
{
byte[] buffer = new byte[bufferSize];
while (true)
{
int num = await this.ReadAsync(buffer, 0, buffer.Length, cancellationToken).ConfigureAwait(false);
int bytesRead;
if ((bytesRead = num) != 0)
await destination.WriteAsync(buffer, 0, bytesRead, cancellationToken).ConfigureAwait(false);
else
break;
}
}
As you can see it always dominated by the slowest part (reader or writer)
* If the writer takes too long to write, the reader cannot read more data.
* There is only one pending write on the wire.
So even though it is not blocking threads (it’s using await) it will not be as fast as possible. The underlying stream supports multiple writes on it. So there is no reason why we need to wait until it finishes writing it before we start writing another one.
Here is an example:
If your writes take 10 milliseconds to write to the wire you will be bound by the amount of data you can push every 10 milliseconds. So if each write is only pushing a 4K buffer you will be able to send only 400K data per second (4K * 10 * 10).
If you are able to read much faster than 400K/second this is not acceptable. What you want is to have the ability of scheduling more than one write at a time. This way you will be able to saturate your network link.
Proposal: Consumer – Producer pattern
My proposal to fix this is to decouple the reads from the writes. Of course we can only write what we have read but read and write operations happen at different rates. So I think it makes sense to make them independent.
A way to do this is to follow the Consumer/Producer pattern.
1) We have a queue where the Producer (the reader) puts buffers as soon as he reads data.
2) Then we have a Consumer (the writer) that grabs buffers as they become available and schedules a write to the wire. Note that it is critical that the consumer does not wait until the write is done before continuing. As mentioned before the HttpResponse OutputStream supports multiple writes.
These two will be running in independent threads and they will stop once the input stream is done and when we have written all the data to the output stream.
Read Loop
Action readLoop = async () =>
{
while (true)
{
// Now wait until there is a free buffer to read into.
ArraySegment<byte> freeBuffer = _freeReadBufferQueue.Take();
byte[] readBuffer = freeBuffer.Array;
int readBufferSize = readBuffer.Length;
// Fill the read buffer before enqueueing it for writing
int readTotal = 0;
int readImmediate;
do
{
readImmediate = await input.ReadAsync(readBuffer, readTotal, readBufferSize - readTotal);
readTotal += readImmediate;
}
while (readImmediate > 0 && readTotal < readBufferSize);
// Enqueue it in the dataQueue for this request
dataQueue.Add(new ArraySegment<byte>(readBuffer, 0, readTotal));
if (readTotal == 0)
{
// Done reading. Bail out of the read loop
break;
}
}
};
- The reader takes a buffer from the “Free buffers queue”. If this queue has a buffer it means there is space for him to read. If the queue is empty it means all of our buffers are being used.
- Then it fills this buffer (note the do-while) until there is no more content or it’s out of space.
- Then it adds this buffer to another queue. The dataqueue. This queue is the one that is read by the consumer.
- When it’s done reading we break out of the loop. Otherwise it starts at 1 again.
Write Loop
Action writeLoop = async () =>
{
while (true)
{
ArraySegment<byte> dataArraySegment = dataQueue.Take();
int dataRead = dataArraySegment.Count;
byte[] dataBuffer = dataArraySegment.Array;
if (dataRead == 0)
{
// If the dataQueue has no data it means we have reached the end
// of the input stream. Time to bail out of the write loop
_freeReadBufferQueue.Add(new ArraySegment<byte>(dataBuffer));
break;
}
// Schedule async write.
// Make sure you don't wait until it's done before continuing
output.BeginWrite(dataBuffer, 0, dataRead, (iar) =>
{
try
{
output.EndWrite(iar);
}
finally
{
// Enqueue the buffer back to the pool so that we can read more data
_freeReadBufferQueue.Add(new ArraySegment<byte>(dataBuffer));
}
}, null);
}
allWritesHaveBeenEnqueued.SetResult(null);
};
- We grab a buffer from the dataQueue that was populated by the producer
- If it’s of length zero it means we are done with the stream so we break out of the loop.
- Otherwise we schedule an asynchronous write. It is the callback of this method the onw that will return the buffer back to the freeReadBufferQueue.
As you can see we have both loops working independent from each other and using the Queues to communicate when they have data and when they are done.
For the implementation of the queues I’m using BlockingCollection. This was released by Microsoft for .Net 4.5. The only downside of this is that it blocks when there is no data in the queue. This can be improved.
So what is the performance for this code?
Downloading the same file now takes:
Overall Elapsed: 0:00:06.200
We got a 75% improvement in latency! Also if we go and measure the network utilization in our Proxy we can see that it nicely saturates the network when responding to our request.
The code for this article can be found here: https://github.com/krolth/Http-Proxy-dotnet
Notes
If you look at the attached code you will see that we are using preallocating the _freeReadBufferQueue in a static variable. We preallocate 1MB of memory and we use this for all of our requests. This way we ensure that regardless of how many requests we have we will not increase our memory footprint.
Another optimization we have is the use of a semaphore in CopyStreamAsync. This is to prevent one big request from hogging all the buffers from _freeReadBufferQueue. In my tests 40 buffers were good enough to return our payload. But if you are using this code I recommend you play around with these settings.
The reason I used 4k buffers is that I did not see a lot of improvement with 8k buffer.
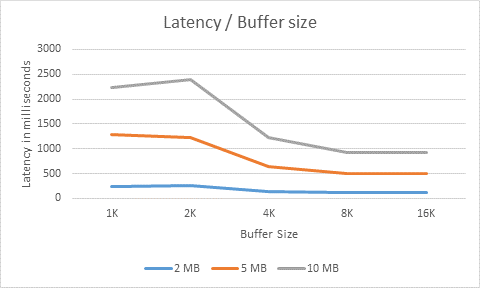
Here is a table with the latency I saw with different buffer sizes.