JavaScript Architecture
No, that isn’t meant to be an oxymoron. But something I’ve noticed recently is that people’s approach to JavaScript seems to be diverging down two common paths. This blog post is designed to encourage you to adopt the one you probably aren’t planning to adopt right now! The approaches I’m describing are depicted below;
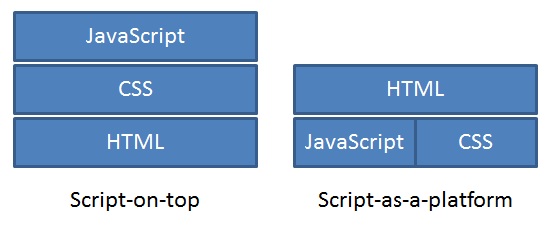
Keep that in mind and we’ll look at each in turn…
Script-on-top
What I’ve dubbed “script-on-top” is what I believe most developers do right now. That is, they look to sit JavaScript on top of the HTML and CSS; the script uses the HTML and CSS and manipulates them as though they are components just waiting to be orchestrated. You’ll often see code that looks a bit like this (I’m using jQuery);
1: $(document).ready(function () {
2: $('#combo').change(function () {
3: var value = $(this).val();
4: var result = myframework.getDisplayMessageFromServer(value);
5: $('#messagediv').html(result);
6: });
7: });
* Note that none of the script in this post is real. I just hacked it into notepad – but it demonstrates the point sufficiently.
There are some good practices there – not least the fact that the call back to the server is encapsulated within a reusable framework. This is layering, effectively creating a data access layer in JavaScript, and hence is following patterns that have been established for a long time for server-side code. The configuration for how to communicate with the server and the location of the server endpoint is all encapsulated within this framework.
However, I have a few problems with this approach.
1. I don’t like specifying element identifiers in JavaScript. Why? Because it feels wrong. It just does. Stick with me and you might start to agree. Fundamentally this comes down to the separation of concerns between CSS, HTML, and JavaScript.
2. If I have lots of drop-down lists that have very similar behaviour, I still have to wire up every single one. A lot of developers really do wire up every single one manually in code like that above. There are ways to apply behaviour in a blanket manner but none quite so good as my preferred approach… so hold that thought.
3. I don’t like the idea of having to write an entirely new User Interface “manager” component of some description. What often happens with the above approach is that when a page gets more complex developers create a central class that wires up all these events, maybe caches some data, and more. Why? Surely we’re done all that server-side, must I really Repeat myself (R capitalised in homage to DRY) on the client?
4. The URLs to each endpoint are embedded in the framework. But my URLs are “designed” on the server (especially if you’re using Routing, perhaps with ASP.NET MVC)… surely I don’t want to hard-code them in the script too?
Script-as-a-platform
So what is the alternative? I believe we need to turn our way of thinking about JavaScript on it’s head. Instead, think of CSS and JavaScript as defining a platform that our HTML mark-up simply refers to in order to build up a user interface. Rather than our JavaScript taking ownership of HTML elements, our HTML makes use of predefined JavaScript “behaviours” (yes, I know that is an emotive term for JavaScript so forgive me!) and CSS styles.
Such a mind-set leads to HTML that looks like this (I’m using ASP.NET MVC 3 with a Razor view);
1: <select
2: data-getmessage-output="#messagediv"
3: data-getmessage-source="@Url.Action("Message", "Ajax", new { item = "{placeholder}" })">
4: </select>
5:
6: <div id="messagediv"></div>
… and matching JavaScript a bit like this;
1: $(document).ready(function () {
2: $('*[data-getmessage-source]').change(function () {
3: var value = $(this).val();
4: var url = $(this)
5: .data('getmessage-source')
6: .replace('{placeholder}', value); ;
7: var output = $(this).data('getmessage-output');
8: var result = myframework.getDataFromServer(url);
9: $(output).html(result);
10: });
11: });
So what is the difference? The difference is that my JavaScript is a reusable component, and my HTML has output instructions to the client to make use of that component through the use of an HTML 5 Custom Data Attribute. It could easily have used a CSS class instead if the parameters to my component were simpler. The script is slightly longer, but it isn’t complex – and none of it will be repeated in individual pages.
As a result, the URL to the endpoint is no longer hard-coded in a JavaScript library. And all SELECTs that should have this behaviour get it automatically just by referencing this script. The pairing of output DIV and drop-down list is clearly defined in HTML, not tucked away in JavaScript somewhere. There are, in fact, no IDs in my JavaScript, which means that my HTML is completely owning the document structure while JavaScript provides behaviour for that structure... without detailed knowledge of it.
I can still create reusable JavaScript – in fact, my sample code could be hugely refactored into something much more reusable.
But most of all, there is no longer a need or temptation for a central orchestrating JavaScript component – our orchestrating is done by the HTML, which is generated server-side, so our server code is really pulling the strings. We’ve moved our mind-set from writing JavaScript to “make the UI work” into writing HTML that composes reusable JavaScript components and behaviours. The highlight is because I believe that’s a good summary description of what I’d encourage you to do.
Does It Matter?
Yes, I believe it does. Follow this composition approach and your JavaScript code will be easier to thoroughly test (because you won’t have lots of separate wiring up code for each page), and the act of composing will often feel simpler to the developer than writing imperative code to “pull strings” for any particular page.
So, what do you think?