SQLCMD and PowerShell: Generate 450 Million Names With 20 Lines of Code
(It's actually 487,861,706 names but it didn't seem like a good title). Skip to the solution.
Note on file sizes: As a full of this sample run require 25GB of disk space, I've placed a simple restriction in the sample code. Prior to running the code without the restriction, readers should be familiar with TempDB file size settings and be aware of how much space they normally require.
Say Goodbye to large data scripts
Who could ever find those big data files with a forgotten name sitting in a forgotten folder on a forgotten server, protected by permissions that nobody has? We wanted to forget them but coming up with large, non-repeating data scripts can be a lot of work. Fortunately our friends at the U.S. Census Bureau love sharing data.
One of the Census Bureau's publications is a list of frequently occuring first names and surnames. Today, we'll download these data files and insert them into a table using nothing more than SQL Server Management Studio in SQLCMD mode.
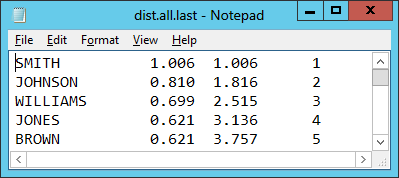
The data we're using an aggregate of 1990 U.S. Census data. The full detail of the files, data format, and sampling methodology are available here. For our purposes, all we need to know is that it is a fixed-width data ASCII file and the "Name" column the first 15 characters of each line.
The files themselves have the following statistics:
| Name/URL | Description | File Size | Count of Unique Names |
| dist.all.last | Last Names | 2mb | 88,799 |
| dist.female.first | Female First names | 146kb | 4,275 |
| dist.male.first | Male First Names | 41kb | 1,219 |
The file itself looks like this:
PowerShell 2.0 Script
We'll start out by testing the smallest data file, dist.male.first. We need a way to download this through PowerShell and Boe Brox has a blog post that shows us how. In his article, we see that the Net.WebClient class provides our needed functionality. We'll run our first test by downloading a file and looking at the first 200 characters:
$URI="https://www.census.gov/genealogy/www/data/1990surnames/dist.male.first"
$web=New-Object Net.WebClient
$result=$web.DownloadString($URI)
$result.Substring(0,200)
In the results, we see that individual names are the only entries using letters. Additionally, there are no hyphenated names, apostrophes, or any other special characters in the name. This makes parsing very easy.
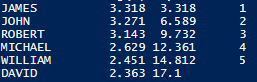
Having downloaded and viewed the file, we'll write a multi-line script in PowerShell, re-write it as a single-line script, then convert it to run in SQLCMD.
For multi-line, we will:
- Remove any characters that are not alphabetical or CR/LF, leaving only names on each line.
- Split each line into an array element; wrap the line in quotes/parenthesis. I.E. JAMES becomes ,('JAMES')
- Generate an INSERT statement on every 100th line.
- Test the results.
$URI="https://www.census.gov/genealogy/www/data/1990surnames/dist.male.first"
$web=New-Object Net.WebClient
$webResult=$web.DownloadString($URI)
# Using RegEx (Regular Expressions), eliminate anything that isn't Alpha or CRLF.
$webResult=$webResult -replace '[^a-z\r\n]',''
# Remove Blank Lines.
$webResult=$webResult -replace '\r\n[^a-z]',''
# Split each line into an array
$names=$webResult.Split("`n`r")
# Remove the empty line at the end of the file
$names=$names | Where-Object {$_.length -GT 1}
$lineCount=0
$names|ForEach-Object {
# Create a new batch every 100 lines
if ($lineCount-- -le 0) {
"GO`r`nINSERT #FirstName VALUES('$_')"
$lineCount=100
}
else
{
",('$_')"
}
} | Select-Object -First 10 # Test by selecting the first 10 lines
We should now have an output that looks like this:
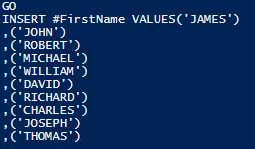
Before we can put everything on one line, we want to take the additional step of removing unnecessary variables. This can be done through piping rather than storing results in a variable. We'll also shorten the variable names that we can't remove. Our code now looks like this:
$URI="https://www.census.gov/genealogy/www/data/1990surnames/dist.male.first"
$lc=0
((New-Object Net.WebClient).DownloadString($URI) -replace'[^a-z\r\n]',''-replace'\r\n[^a-z]','').Split("`n`r") |
Where-Object {$_.length -GT1} |ForEach-Object {
if ($lc---le0) {
"GO`r`nINSERT #FirstName VALUES('$_')"
$lc=100
}
else
{
",('$_')"
}
} |Select-Object -First 10 # Test by selecting the first 10 lines
Finally, we remove all hope of readability by putting everything but the URI on one line like this:
$URI="https://www.census.gov/genealogy/www/data/1990surnames/dist.male.first"
$lc=0; ((New-Object Net.WebClient).DownloadString($URI) -replace '[^a-z\r\n]','' -replace '\r\n[^a-z]','').Split("`n`r") | Where-Object {$_.length -GT 1} |ForEach-Object { if ($lc -le 0) { "GO`r`nINSERT #FirstName VALUES('$_')"; $lc=100 } else { ",('$_')" } } | Select-Object -First 10
After testing the script one final time, we're ready to put it in SQLCMD.
Porting to SQLCMD
One More PowerShell SQLCMD caveat:
Adding quotes to your command can be a challenge. This is because SQLCMD and the Command Shell both attempt to strip quotes from strings. PowerShell often allows single quotes and double quotes interchangeably but it's not possible 100% of the time. With that, I (embarassingly) present the Quote variable:
:setvar Q """"""""
This variable, while not pretty, will be inserted into each of the sections that require double-quotes.
The Solution
The final query is shown below.
Reminder: As the full script results in a 25GB TempDB file, this script has been modified to return the first 20,000 rows. For demonstration purposes, a variable "SampleCount" limits the INSERT to 100 rows from each file (100 last * (100 first+100 first)). In addition to the 25GB disk requirement, running the full query on my system (a six-core desktop PC) took about 7 minutes. With that in mind, if you REALLY want to throttle your system to get all 487 million rows, simply comment out the second SETVAR command.
SET NOCOUNT ON
:out $(TEMP)\Names.sql
:setvar SampleCount ""
:setvar SampleCount "| Select-Object -First 100"
:setvar Q """"""""
:setvar PSCmd "PowerShell -InputFormat none -Command"
:setvar URI "https://www.census.gov/genealogy/www/data/1990surnames/dist.all.last"
!!$(PSCmd) "& { $lc = 0; ((New-Object Net.WebClient).DownloadString('$(URI)') -replace '[^a-z\r\n]','' -replace '\r\n[^a-z]','').Split($(Q)`n`r$(Q)) | Where-Object {$_.length -GT 1} | ForEach-Object { if ($lc-- -le 0) { $(Q)GO`r`nINSERT #LastNames VALUES('$_')$(Q); $lc = 100 } else { $(Q),('$_')$(Q) } } $(SampleCount) }"
:setvar URI "https://www.census.gov/genealogy/www/data/1990surnames/dist.female.first"
!!$(PSCmd) "& { $lc = 0; ((New-Object Net.WebClient).DownloadString('$(URI)') -replace '[^a-z\r\n]','' -replace '\r\n[^a-z]','').Split($(Q)`n`r$(Q)) | Where-Object {$_.length -GT 1} | ForEach-Object { if ($lc-- -le 0) { $(Q)GO`r`nINSERT #FirstNames VALUES('$_')$(Q); $lc = 100 } else { $(Q),('$_')$(Q) } } $(SampleCount) }"
:setvar URI "https://www.census.gov/genealogy/www/data/1990surnames/dist.male.first"
!!$(PSCmd) "& { $lc = 0; ((New-Object Net.WebClient).DownloadString('$(URI)') -replace '[^a-z\r\n]','' -replace '\r\n[^a-z]','').Split($(Q)`n`r$(Q)) | Where-Object {$_.length -GT 1} | ForEach-Object { if ($lc-- -le 0) { $(Q)GO`r`nINSERT #FirstNames VALUES('$_')$(Q); $lc = 100 } else { $(Q),('$_')$(Q) } } $(SampleCount) }"
:out STDOUT
IF OBJECT_ID('tempdb..#FullNames') IS NOT NULL
DROP TABLE #FullNames
IF OBJECT_ID('tempdb..#LastNames') IS NULL
CREATE TABLE #LastNames(LastName VARCHAR(30))
IF OBJECT_ID('tempdb..#FirstNames') IS NULL
CREATE TABLE #FirstNames(FirstName VARCHAR(30))
TRUNCATE TABLE #LastNames
TRUNCATE TABLE #FirstNames
GO
:r $(TEMP)\Names.sql
SELECT * INTO #FullNames FROM #LastNames CROSS JOIN #FirstNames
SELECT COUNT(*) AS NameCount FROM #FullNames
For readability (seriously), I've added extra spaces between lines. If you want the promised "20 lines of code" from the title, you can actually get it down to 17 by removing extra spacing and concatenating all of your T-SQL (putting a semicolon between each command). You can get it to 15 lines by removing the SampleCount variables.
Extending the Solution
We took a lot of steps to reduce this to the bare-minimum data for the demo but the best data representation would actually have repeating names. If America has 314 million people, our table should have 104,810 people named James Smith (and 2.22 people named Jared Ko). This is all available from the other columns in these tables.
We could also add demographic information, income ranges, give them all a place to live, and if we're still not tired, start building our international database.