Columnstore Index Performance: SQL Server 2016 – Multiple Aggregates
SQL product team has made significant improvements in columnstore index functionality, supportability and performance during SQL Server 2016 based on the feedback from customers. This blog series focuses on the performance improvements done as part of SQL Server 2016. Customers will get these benefits automatically with no changes to the application when they upgrade the application to SQL Server 2016.
The examples here are based on AdventureWorksDW2016CTP3 database that you can download from here. For each example, I will run the query in SQL Server 2014 and then contrast that with SQL Server 2016 and to reinforce the point that you get perfomance improvments without requiring any changes to your query or the workload.
SQL Server 2014
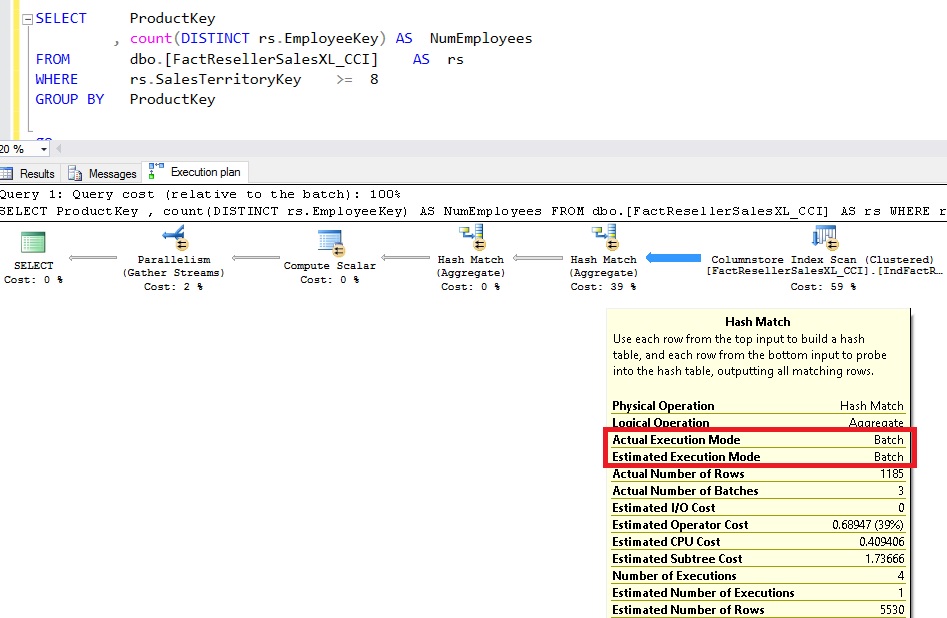
Let us consider the following query. All three operators, SCAN on columntore index and the two HASH MATCH operators are automatically run in BATCH mode. The picutre below shows the execution details of one of the HASH MATCH operator.
Now, let us change the query little bit by adding one more aggregate as circled in the Redbox below. When this query was run, the execution plan got lot more complicated and HASH MATCH operators were executed in ROW mode as shown below. However, the SCAN of columnstore index was still executed in BATCH mode.
Though not shown in the picture here, the query took 15x longer to execute. The reason for this slowdown was that SQL Server 2014 did not process multiple aggregates optimally.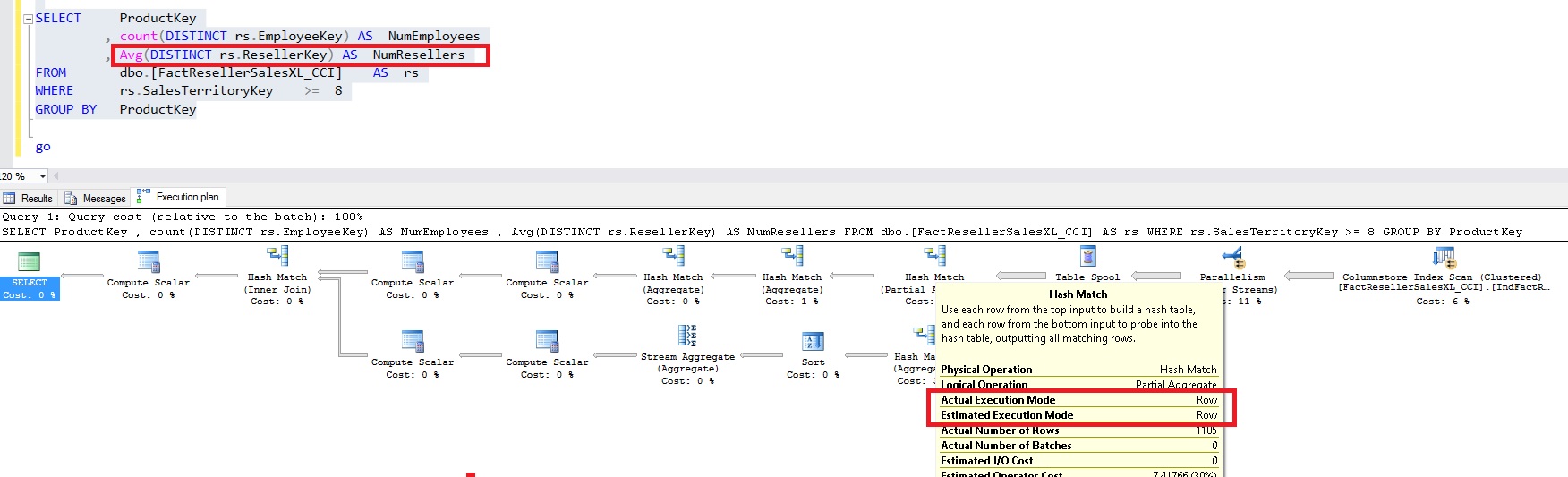
SQL Server 2016
This issue has been addressed in SQL Server 2016. I ran the query with double aggregates ‘as is’ with SQL Server 2016 as shown in the picture below. Note, that the query plan is essentially unchanged irrespective of number of aggregates computed with HASH MATCH operator executing in BATCH mode.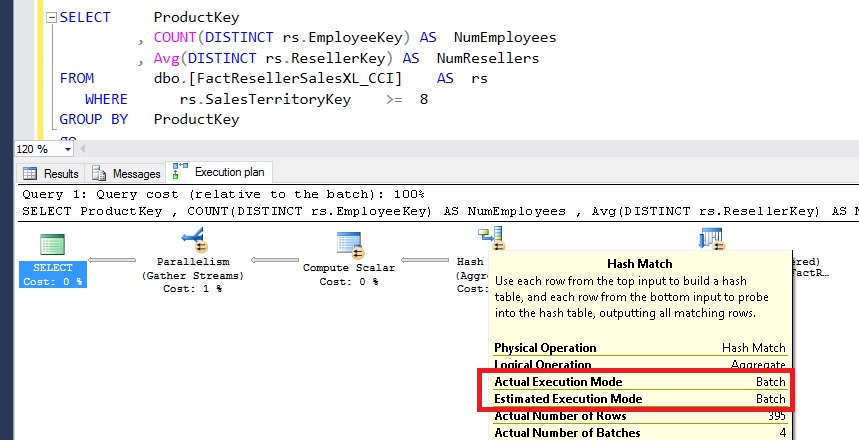
Though not shown in the picture above, this query ran 16x faster when compared with SQL Server 2014. This improvement in query performance is only available with database compatibility mode 130. Since 130 compatibility mode uses new cardinality estimator (CE) by default. We have seen few customer cases where new CE caused query performance regressions. You can work around that by forcing SQL Server via a Trace Flag 9481 or providing ‘use hints’ as described in SQL Server 2016 SP1 to use old CE
Thanks,
Sunil Agarwal
SQL Server Tiger Team Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam