Troubleshooting High HADR_SYNC_COMMIT wait type with Always On Availability Groups
HADR_SYNC_COMMIT indicates the time between when a transaction ready to commit in the primary replica, and all secondary synchronous-commit replicas have acknowledged the hardening of the transaction commit LSN in an AG. It means a transaction in the primary replica cannot be committed, until the primary replica received greater hardened LSNs from all secondary synchronous-commit replicas. If transactions in the primary replica are slower than usual, and HADR_SYNC_COMMIT is unusually long, it means there is some performance issue in at least one Primary-Secondary replica data movement flow, or at least one secondary replica is slow in log hardening.
This blog post drills down on all related monitoring metrics including performance counters and XEvents, and provides guidelines on how to utilize them to troubleshoot the root cause of the performance issue.
All the metrics explained below are listed as per the following log block movement sequence:
1. A transaction is initialized in a primary replica
2. Primary replica capture transaction logs and send to a secondary replica
3. The secondary replica receives and harden log block and eventually send new hardened lsn to Primary.
Availability Group Performance Counters
Some of the performance counters included below are applicable to both the primary and secondary, and hence are included twice in the list below.
| Perf Counter | AG Replica | SQL release | Explanation and Usage |
| Log Bytes Flushed/sec | Primary | SQL 2012+ | Total number of log bytes flushed per second in the primary replica. It represents the volume of logs that are available to be captured in primary replica and sent to secondary replica(s). |
| Log Pool LogWriter Pushes/sec | Primary | SQL 2016+ | Total number of log bytes are captured by LogWriter mode. LogWriter mode was introduced in SQL Server 2016 and it directly captures logs from memory log cache instead of log file. When LogWriter mode is on, it means there is almost no lag between log flush and log capture. |
| Bytes Sent to Replica/sec | Primary | SQL 2012+ | Total number of bytes sent to the internal message Queue of a single secondary replica (for both replica and database level data). The internal in-memory message queue which holds the captured and formatted data that will be sent to the targeted secondary replica. By default, the data in the internal message queue is compressed for both sync and async secondary replicas in SQL12 and SQL14. But only for an async secondary replica from SQL16. When data compression is enabled, the data volume of this perf counter is less than the corresponding value in Log Bytes Flushed/sec. |
| Flow Control/sec | Primary | SQL 2012+ | Number of flow control initiated in the last second. AG has internal throttling gates to control data flow. When the number of sequential messages that has not be acknowledged by secondary replica exceeds the gate value, data flow will be paused until receiving more acknowledge messages from secondary replica. More details can be found in "Flow Control Gates" section in https://msdn.microsoft.com/en-us/library/dn135338(v=sql.120).aspx with one correction: Database level gate values are 1792 for x64 and 256 for x86 environments. |
| Flow Control Time (ms/sec) | Primary | SQL 2012+ | Time in milliseconds messages waited on flow control in the last second. |
| Bytes Sent to Transport/sec | Primary | SQL 2012+ | Total bytes sent to transport (UCS) for the availability replica. It represents the volume of data dequeued for XmitQueue and sent to transport layer. Its values should be very close to "Bytes Sent to Replica/sec" with a very slight lag. |
| Bytes Received from Replica/sec | Secondary | SQL 2012+ | Total bytes received from the primary replica. It represents the volume of data received from transport (UCS) before any processing in secondary replica. Its values should be very close to "Bytes Sent to Replica/sec" on primary, with a lag influenced by the current network latency between this primary-secondary replica pair. |
| Log Bytes Flushed/sec | Secondary | SQL 2012+ | Total number of log bytes flushed per second in the secondary replica. When secondary receives new log packages from primary, it decompresses and hardens them before sending a progress message to primary for its new hardened lsn. The trend of this perf counter should align with the same perf counter in primary replica with some lags. |
| Bytes Sent to Replica/sec | Secondary | SQL 2012+ | Total number of bytes sent to the XmitQueue for delivering to the primary replica. They are all AG control messages, and data volume is very low. |
| Flow Control/sec | Secondary | SQL 2012+ | Number of flow control initiated in the last second. Although secondary replica only sends AG control messages to primary, it may hit transport level flow control when it has hundreds of databases, and primary replica cannot send acknowledge message in time. |
| Flow Control Time (ms/sec) | Secondary | SQL 2012+ | Time in milliseconds messages waited on flow control in the last second. |
| Bytes Sent to Transport/sec | Secondary | SQL 2012+ | Total bytes sent to transport (UCS) for the availability replica. |
| Bytes Received from Replica/sec | Primary | SQL 2012+ | Total bytes received from the secondary replica. |
In Perfmon, except "Log Bytes Flushed/sec" and "Log Pool LogWriter Pushes/sec" which is in SQLServer:Databases object, all other counters are in the SQLServer:Availability Replica object.
Network Performance Counters
There are a few performance counters in "Network Interface" object can be used for network performance monitoring:
| Perf Counter | Description |
| Bytes Received/sec | Shows the rate at which bytes are received over each network adapter. The counted bytes include framing characters. Bytes Received/sec is a subset of Network Interface\Bytes Total/sec. |
| Bytes Sent/sec | Shows the rate at which bytes are sent over each network adapter. The counted bytes include framing characters. Bytes Sent/sec is a subset of Network Interface\Bytes Total/sec. |
| Bytes Total/sec | Shows the rate at which bytes are sent and received on the network interface, including framing characters. Bytes Total/sec is the sum of the values of Network Interface\Bytes Received/sec and Network Interface\ Bytes Sent/sec. |
| Current Bandwidth | Shows an estimate of the current bandwidth of the network interface in bits per second (BPS). For interfaces that do not vary in bandwidth or for those where no accurate estimation can be made, this value is the nominal bandwidth. |
When a host machine has a network dedicated for SQL, the network "Bytes Sent/sec" should share the same trend as AG "Bytes Sent to Transport/sec" with slightly larger values in the primary replica. Same similarity is observed between network counter "Bytes Received/sec" and AG counter "Bytes Received from Replica/sec" on the secondary replica.
Please note that "Current Bandwidth" value is in BPS (bit per second). When comparing it to the "Bytes Total/sec", the "Current Bandwidth" value needs to be divided by 8 first. When "Bytes Total/sec" is consistently close or equal to ("Current Bandwidth"/8), the network bandwidth can be identified as the performance bottleneck.
Availability Group Extended Events
Although performance counters can present the overall performance in each AG data movement stage, they are not sufficient to find out which stage is slow when there is a performance issue because the data flow in AG is like a closed-loop system, the slowest node decides the final throughput of the system. When trying to study available performance counters after a performance issue has started, all perf counter values may have already been slowed down.
It will be useful to capture extended events and correlated them by common field(s) to track a single block log movement in the whole data flow. It will provide details for identifying which stage took most of time and narrowing down the root cause analysis scope.
Below is a list of extended events that can be evaluated for investigating performance issues related to high HADR_SYNC_COMMIT.
| Event Name | Replica | Description | Symptom Key & Value | Correlation Key(s) |
| log_flush_start | Primary | Occurs when asynchronous log write starts | log_block_id,database_id | |
| log_flush_complete | Primary | Occurs when log write complete. It can happen after hadr_capture_log_block because of its asynchronous nature of writes. | log_block_id,database_id | |
| hadr_log_block_compression | Primary | Occurs when log is ready to be captured and log compression is enabled. (If log compression is not enabled, this XEvent is not logged in SQL12 and SQL14, but it is always logged from SQL16. For SQL16, check Boolean value of property is_compressed.) | log_block_id,database_id | |
| hadr_capture_log_block | Primary | Occurs right after primary has captured a log block. | mode=1 | log_block_id, database_replica_id |
| hadr_capture_log_block | Primary | Occurs right before primary enqueues the captured log block to an internal message Queue of DbMgrPartner. A DbMgrPartner maps a database in the remote replica. No processing operation between mode 1 and 2. | mode=2 | log_block_id,database_replica_id |
| hadr_capture_log_block | Primary | Occurs after dequeuing a log block from the internal message Queue of DbMgrPartner and before sending to transport (UCS) | mode=3 | log_block_id,database_replica_id |
| hadr_capture_log_block | Primary | Occurs after the dequeued message reaches Replica layer and before sending to transport (UCS). Only message routing actions between mode 3 and 4. | mode=4 | log_block_id,database_replica_id,availability_replica_id |
| hadr_transport_receive_log_block_message | Secondary | Occurs when receiving new log block message from transport (UCS) | mode=1 | log_block_id,database_replica_id |
| hadr_transport_receive_log_block_message | Secondary | Occurs after enqueuing a new RouteMessageTask to DbMgrPartner for this new received log block. No process operations yet. | mode=2 | log_block_id,database_replica_id |
| hadr_log_block_decompression | Secondary | Occurs after decompressing log block buffer. Boolean value of "is_compressed" means the incoming log block buffer is compressed or not. | log_block_id,database_id | |
| log_flush_start | Secondary | Occurs when asynchronous log write starts | log_block_id,database_id | |
| log_flush_complete | Secondary | Occurs when log write complete | log_block_id,database_id | |
| hadr_apply_log_block | Secondary | Occurs right after log block is flushed and new redo target LSN is calculated in secondary | log_block_id,database_replica_id | |
| hadr_send_harden_lsn_message | Secondary | Occurs when SyncLogProgressMsg with new hardened lsn is constructed and before pushing this message to the internal message Queue of the database's DbMgrPartner. At this point, the previous received log block has been flushed to disk, but the current log block may not. | mode=1 | log_block_id (*Need to choose the immediate next log_block_id of this database),hadr_database_id |
| hadr_send_harden_lsn_message | Secondary | Occurs when SyncLogProgressMsg is dequeued from the internal message Queue and before sending to transport (UCS) | mode=2 | log_block_id (*Need to choose the immediate next log_block_id of this database),hadr_database_id |
| hadr_send_harden_lsn_message | Secondary | Occurs after the dequeued SyncLogProgressMsg reaches Replica layer and before sending to transport (UCS). No processing operation between mode 2 and 3. | mode=3 | log_block_id (*Need to choose the immediate next log_block_id of this database),hadr_database_id |
| hadr_receive_harden_lsn_message | Primary | Occurs when receiving new SyncLogProgressMsg which contains new hardened lsn of database in secondary replica from transport (UCS) | mode=1 | log_block_id (*Need to choose the immediate next log_block_id of this database),database_replica_id |
| hadr_receive_harden_lsn_message | Primary | Occurs after enqueuing a new RouteSyncProgressMessageTask to DbMgrPartner for this new received SyncLogProgressMsg. No processing operations yet. | mode=2 | log_block_id (*Need to choose the immediate next log_block_id of this database),database_replica_id |
| hadr_db_commit_mgr_harden | Primary | Occurs after minimal hardened lsn among primary replica and all synchronous-commit secondary replicas exceeds the lsn of the expected log block. | wait_log_block,database_id,ag_database_id | |
| hadr_db_commit_mgr_harden_still_waiting | Primary | Occurs when a committed lsn in primary has not been notified for the hardening from all synchronous-commit secondary replicas for more than 2 seconds. This Xevent will be logged every 2 seconds until logging hadr_db_commit_mgr_harden.In normal cases, the harden wait time is in tens of millisecond range, and this XEvent is not logged. | wait_log_block,database_id,ag_database_id |
*Regarding the comment "Need to choose the immediate next log_block_id of this database" for hadr_send_harden_lsn_message and hadr_receive_harden_lsn_message, it is because the ChangeApply side always returns a hardened lsn which is one block less than the currently received log block lsn. To ensure the primary replica received the expected hardened LSN from synchronous-commit secondary replica, the immediate next log block lsn is needed to trace the complete end-to-end logic flow for eventually reaching hadr_db_commit_mgr_harden.
To trace these, two XEvent queries are needed:
1. Get the immediate next log block lsn which is greater than the value in property "wait_log_block" of Xevent hadr_db_commit_mgr_harden
Query in secondary replica (because that the max size of a log block is 60KB, and 1 log block unit represents 512 bytes, the [next log_block_id] will not be 120 more than the current log_block_id)
log_block_id > [current log_block_id] && log_block_id <= [current log_block_id] + 120
pick the first log_block_id from the query result as the [next log_block_id]
2. Use current log block and next log blocks to get the end-to-end Xevent flow of a log block that contains the expected commit lsn.
Query in primary replica:
(name != hadr_receive_harden_lsn_message && log_block_id = [current log_block_id]) ||
(name == hadr_receive_harden_lsn_message && log_block_id = [next log_block_id]) ||
(name == hadr_db_commit_mgr_harden && wait_log_block = [current log_block_id])
Query in secondary replica:
(name != hadr_send_harden_lsn_message && log_block_id = [current log_block_id]) ||
(name == hadr_send_harden_lsn_message && log_block_id = [next log_block_id])
Screenshot for a sample XEvent flow in Primary replica (highlighted records):
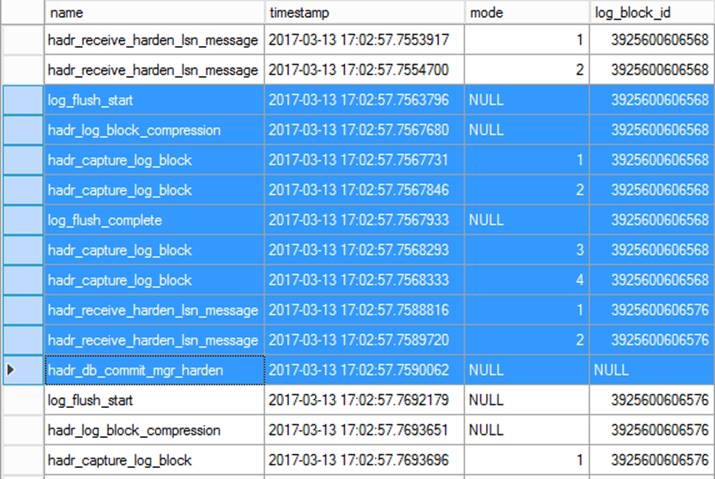
log_block_id (3925600606568) is got from property "wait_log_block" of Xevent hadr_db_commit_mgr_harden
Screenshot for a sample XEvent flow in Secondary replica (highlighted records):
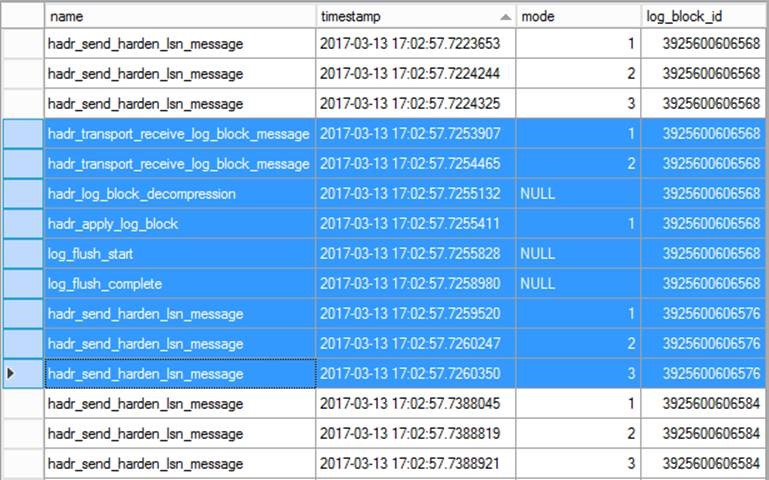
Based on the "wait_log_block" value in a hadr_db_commit_mgr_harden, the full timeline of this log_block data movement sequence can be tracked back following above table by combining the captured Xevents from primary replica and all synchronous-commit secondary replicas.
Optionally, the "database_id" and "ag_database_id" (which is database replica id in AG) can be combined with "wait_log_block" for the related Xevent logs lookup.
In addition, the mapping among database_id, ag_database_id and replica_id can be found from the output of sys.dm_hadr_database_replica_states.
Troubleshooting
There are multiple possible reasons to cause HADR_SYNC_COMMIT to be unusually long. With above performance counters and XEvents, it is possible to narrow down the root cause. If none of the resources has performance issue, please involve Microsoft Customer Support Team for further investigation
Slow Disk IO
With AG Xevents, the duration between log_flush_start and log_flush_complete for the same log_block_id in the secondary replica should be long when there is a disk IO issue. Another way to look for this value is to check value (in millisecond) of property "duration" in log_flush_complete.
When a secondary replica of an AG has compatible hardware configuration as the primary replica (which is recommended in MSDN – section "Recommendations for Computers That Host Availability Replicas (Windows System)" in https://msdn.microsoft.com/en-us/library/ff878487.aspx), and the host computer of the secondary replica is dedicated to this AG, it is not expected to see secondary replica has disk IO issue before the primary replica hit it. One exception is that the secondary replica enables read-only access, and it receives IO intensive reporting workloads. Frequent log backup and copy backup can be another potential cause to be looked at.
High CPU
When a secondary replica of an AG has compatible hardware configuration as the primary replica, and its host computer is for this AG only, it is not expected to see Secondary replica hit CPU issue. But it is possible when there is a heavy reporting workload on a read-only enabled secondary replica.
In addition, log compression in primary replica and log decompression in secondary replica can be CPU heavy operations. If compression is enabled (based on XEvent hadr_log_block_compression is logged in primary, or property is_compressed of XEvent hadr_log_block_decompression is true or not), it can be a possible cause for high CPU in both primary and secondary replicas. When hadr_log_block_compression is logged in primary replica with is_compressed=true, if the duration between log_flush_start and hadr_log_block_compression is long, while DISK IO is still fast, data compression can be identified as the cause. Similarly, the duration between hadr_transport_receive_log_block_message (mode=2) and hadr_log_block_decompression can be measured for the same detection.
When compression/decompression is identified to be the root cause of High CPU, for SQL Server 2012 and SQL Server 2014, disabling compression with TF1462 is a workaround option by sacrificing some network efficiency (bigger data packages to network). For SQL Server 2016 and above, disabling parallel compression (TF 9591) is another option.
Network Issues
After rooting out the disk IO and high CPU as the root cause of long HADR_SYNC_COMMIT, network performance needs to be checked.
With the "Network Performance Counters" mentioned above, the first thing is to check if "Bytes Total/sec" is close to "Current Bandwidth"/8 for the related Network Adapter in primary replica and all synchronous-commit secondary replicas. When any replicas show this situation, it means this network adapter has reached its network throughput capacity.
To check if the network throughput is mainly from AG data movement, the values of Network perf count "Bytes Sent/sec" and AG perf counter "Bytes Sent to Transport/sec" can be compared in Primary replica for a specific secondary replica as the sync partner, and the values of network perf counter "Bytes Received/sec" and AG perf counter "Bytes Received from Replica/sec" can be compared in Secondary replica. Their values and trend should be very close to each other.
XEvents can be applied here to examine the network latency. For the same log_block_id, the duration between hadr_capture_log_block (mode=4 in primary with the matching availability_replica_id to the secondary replica) and hadr_transport_receive_log_block_message (mode=1 in secondary) means the network latency for a log block to transport from primary to secondary replica. The duration between hadr_send_harden_lsn_message (mode=3 in secondary) and hadr_receive_harden_lsn_message (mode=1 in primary) represents the network latency for a log block lsn hardening message to move from secondary to primary.
Content Creator - Dong Cao, Principal Software Engineer, Data Platform Group, Microsoft
Sourabh Agarwal
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam