Loading data to SQL Azure the fast way
Introduction
Now that you have your database set up in SQL Azure, the next step is to load your data to this database. Your data could exist in various sources; valid sources include SQL Server, Oracle, Excel, Access, flat files and others. Your data could exist in various locations. A location might be a data center, behind a corporate firewall, on a home network, or even in Windows Azure.
There are various data migration toolsavailable, such as the SQL Server BCP Utility, SQL Server Integration Services (SSIS), Import and Export Data and SQL Server Management Studio (SSMS). You could even use the Bulk Copy API to author your own customized data upload application. An example of one such custom data migration application that is based on BCP is the SQL Azure Migration Wizard.
In this blog we discuss
1. Tools you have to maximize data upload speeds to SQL Azure
2. Analysis of results from data upload tests
3. Best Practices drawn from the analysis to help choose the option that works best for you
Choose the right Tool
Here are some popular tools that are commonly used for bulk upload.
BCP: This is a utility available with the SQL command line utilities that is designed for high performing bulk upload to a single SQL Server/Azure database.
SSIS: This is a powerful tool when operating on multiple heterogeneous data sources and destinations. This tool provides support for complex workflow and data transformation between the source and destination.
In some cases it is a good idea to use a hybrid combination of SSIS for workflow and BCP for bulk load to leverage the benefits of both the tools.
Import & Export Data: A simple wizard that does not offer the wide range of configuration that SSIS provides, but is very handy for schema migration and smaller data uploads.
SSMS: This tool has the option of generating SQL Azure schema and data migration scripts. It is very useful for schema migration, but is not recommended for large data uploads.
Bulk Copy API: In the case where you need to build your own tool for maximum flexibility of programming, you could use the Bulk Copy API. This API is highly efficient and provides bulk performance similar to BCP.
Set Up
To standardize this analysis, we have chosen to start with a simple flat-file data source with 1GB of data and 7,999,406 rows.
The destination table was set up with one clustered index. It had a size of 142 bytes per row.
We have focused this analysis on the two distinct scenarios of having data located inside and outside Windows Azure.
After sampling the various tools, we have identified BCP and SSIS as the top two performing tools for this analysis. These tools were used under various scenarios to determine the setup that provides fastest data upload speeds.
When using BCP, we used the –F and –L options to specify the first and last rows of the flat file for the upload. This was useful to avoid having to physically split the data file to achieve multiple stream upload.
When using SSIS, we split source data into multiple files on the file system. These were then referenced by Flat File Components in the SSIS designer. Each input file was connected to a ADO .Net Component that had the Use Bulk Insert when possible flag checked.
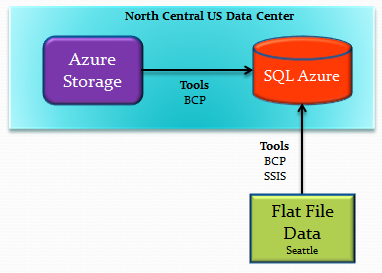
Approach
SQL Azure must be accessed from local client tool over the Internet. This network has three properties that impact the time required to load data to SQL Azure.
· Latency: The delay introduced by the network in getting the data packets to the server.
· Bandwidth: The capacity of the network connection.
· Reliability : Prone to disconnects due to external systems.
Latency causes an increase in time required to transfer data to SQL Azure. The best way to mitigate this effect is to transfer data using multiple concurrent streams. However, the efficiency of parallelization is capped by the bandwidth of your network.
In this analysis, we have studied the response of SQL Azure to concurrent data streams so as to identify the best practices when loading data to SQL Azure.
Results & Analysis
The chart below shows the time taken to transfer 1GB of data to a SQL Azure table with one clustered index.
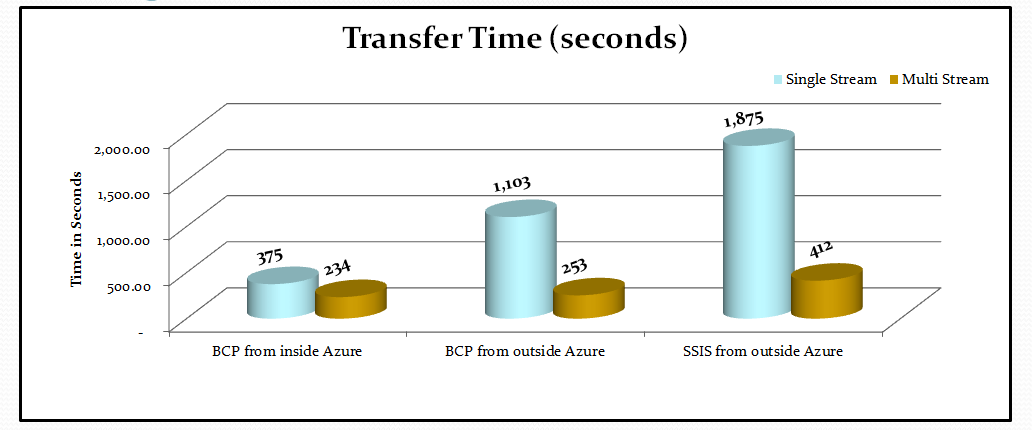
The columns are grouped by the data upload tool used and the location of the data source. In each grouping we compare the performance of single versus multiple streams of data.
From the results we observed the fastest transfer time when loading data from Windows Azure to SQL Azure. We see that using multiple streams of data clearly improved the overall usage of both tools. Moreover, using multiple streams of data helped achieve very similar transfer times from both outside and inside Windows Azure.
BCP allows you to vary the batch size (number of rows committed per transaction) and the packet size (number of bytes per packet sent over the internet). From the analysis it was evident that although these parameters can greatly influence the time to upload data, their optimum values depend on the unique characteristics of your data set and the network involved.
For our data set and network that was behind a corporate firewall
Tool |
Observation |
BCP |
Best performance at 5 streams, with a batch size of 10,000 and default packet size of 4K. |
SSIS |
Best performance at 7 streams. We had the Use bulk upload when possible check box selected on the ADO .NET destination SQL Azure component. |
Best Practices for loading data to SQL Azure
· When loading data to SQL Azure, it is advisable to split your data into multiple concurrent streams to achieve the best performance.
· Vary the BCP batch size option to determine the best setting for your network and dataset.
· Add non clustered indexes after loading data to SQL Azure.
o Two additional indexes created before loading the data increased the final database size by ~50% and increased the time to load the same data by ~170%.
· If, while building large indexes, you see a throttling-related error message, retry using the online option.
Appendix
Destination Table Schema
CREATE TABLE LINEITEM
(L_ORDERKEY bigint not null,
L_PARTKEY int not null,
L_SUPPKEY int not null,
L_LINENUMBER int not null,
L_QUANTITY float not null,
L_EXTENDEDPRICE float not null,
L_DISCOUNT float not null,
L_TAX float not null,
L_RETURNFLAG char (1) not null,
L_LINESTATUS char (1) not null,
L_SHIPDATE date not null,
L_COMMITDATE date not null,
L_RECEIPTDATE date not null,
L_SHIPINSTRUCT char (25) not null,
L_SHIPMODE char (10) not null,
L_COMMENT varchar (44) not null);
CREATE CLUSTERED INDEX L_SHIPDATE_CLUIDX ON LINEITEM (L_SHIPDATE);
CREATE INDEX L_ORDERKEY_IDX ON LINEITEM (L_ORDERKEY);
CREATE INDEX L_PARTKEY_IDX ON LINEITEM (L_PARTKEY);
Using the TPC DbGen utility to generate test Data
The data was obtained using the DbGen utility from the TPC website. We generated 1 GB of Data for the Lineitem table using the command dbgen –T L -s 4 -C 3 -S 1.
Using the –s option, we set the scale to 4 that generates a Lineitem table of 3GB. Using the –C option we split the table into 3 portions, and then using the –S option we chose only the first 1GB portion of the Lineitem table.
Unsupported Tools
The Bulk Insert T-SQL statement is not supported on SQL Azure. Bulk Insert expects to find the source file on the database server’s local drive or network path accessible to the server. Since the server is in the cloud, we do not have access to put files on it or configure it to access network shares.
Lubor Kollar and George Varghese