SQLSweet16!, Episode 2: Availability Groups Automatic Seeding
Reviewed by: Denzil Ribeiro, Murshed Zaman, Mike Weiner, Kun Cheng, Luis Vargas, Girish Mittur V, Arvind Shyamsundar, Mike Ruthruff
If you have been using Availability Groups (or Database Mirroring prior to that), you are probably used to backing up the primary and restoring (with norecovery) the secondary (first a full database backup, followed by transaction log backups) for creating an Availability Group (AG). Automatic Seeding will come as a breath of fresh air to you.
SQL Server 2016 introduces automatic seeding for Availability Groups, which can significantly ease the experience of creating an AG. Whether you used the AG wizard or scripts to create AGs, you likely created a file share first (where the backup files will be written to, and from where the secondary pick up the backup files to restore). With automatic seeding, gone are the file share and the numerous IOs to the file share. Instead, automatic seeding uses the database mirroring endpoints to stream the bytes (after reading from database files) to the secondary and apply them. Getting rid of the file share and the IO involved with it, automatic seeding dramatically reduces the seeding time for AGs. Moreover, if your AG involves multiple databases, you no longer need to perform backup + restore for each database individually; automatic seeding is a replica level setting and applies to all the databases in the AG.
You can choose mixed seeding techniques in an AG, i.e., use automatic seeding for some replicas and use backup + restore for other replicas.
Creating an AG with Automatic Seeding
As of this writing, the only way to use automatic seeding is using T-SQL. If you use the AG wizard to create AGs, you can generate the T-SQL script from the wizard and then edit it to include the automatic seeding setting. While stepping through the wizard, on the “Select Initial Data Synchronization” page, you need to select the option “Skip initial data synchronization” as shown in Figure 1.
[caption id="attachment_2965" align="alignnone" width="1117"]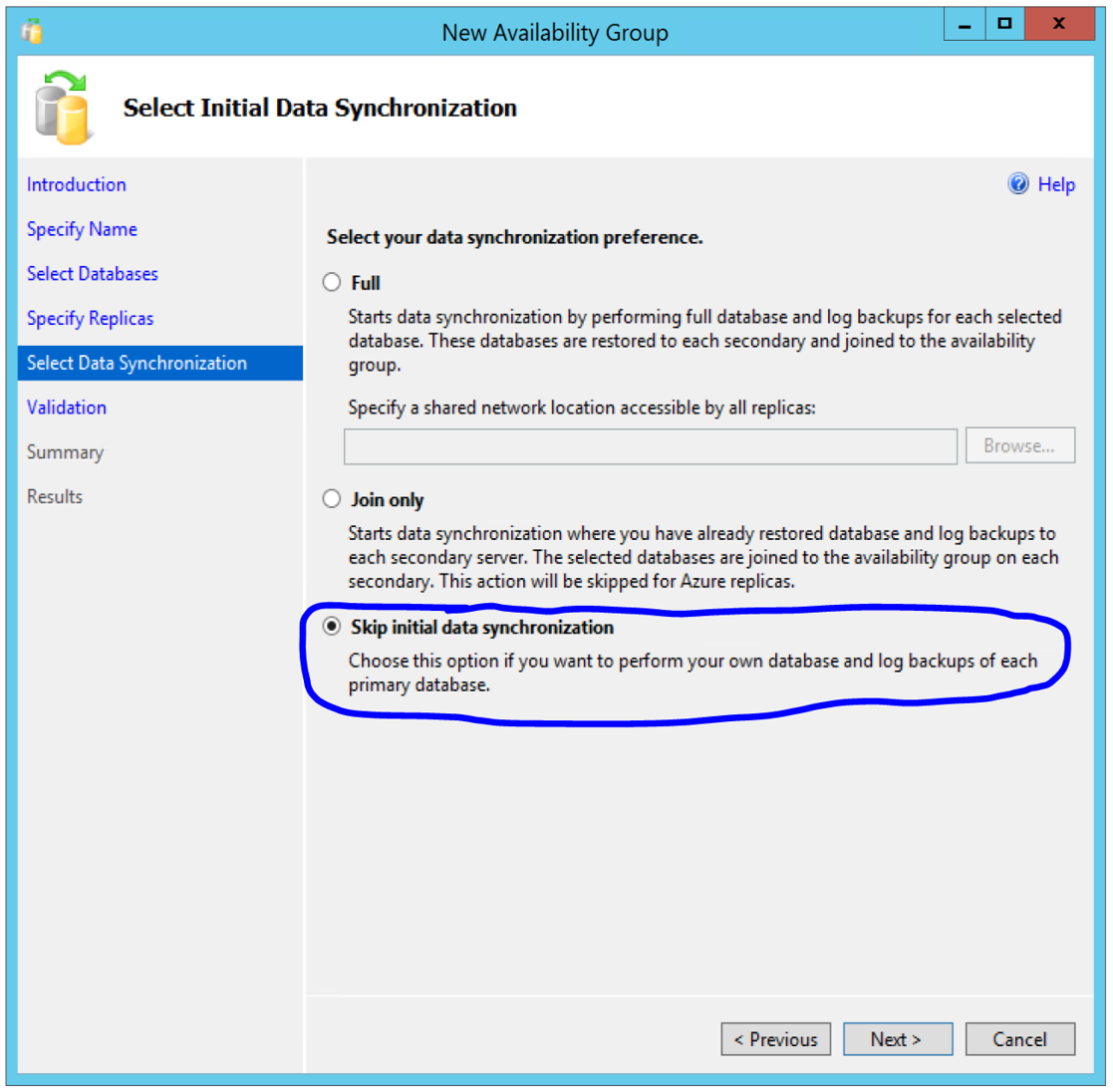 Figure 1: AG wizard selection to generate script for automatic seeding[/caption]
Figure 1: AG wizard selection to generate script for automatic seeding[/caption]
This selection is not intuitive, given your ultimate goal, but is a workaround till the future version of the wizard includes an option for automatic seeding. Step through the rest of the wizard, and on the last page of the wizard, DON’T click on “Finish”, rather click on “Script” to generate the T-SQL script to a new query window.
You need to make two changes to the generated script:
- Edit the CREATE AVAILABILITY GROUP command to specify automatic seeding (SEEDING_MODE = AUTOMATIC, is the only change you need to do on this statement), as shown in the following code sample (shows only the section of the Create AG script that needs changes):
:Connect <primary instance>
USE [master]
GO
CREATE AVAILABILITY GROUP <AG Name>
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY,
DB_FAILOVER = OFF,
DTC_SUPPORT = NONE)
FOR DATABASE <DB Name>
REPLICA ON
'<primary instance>' WITH
(ENDPOINT_URL = 'primary_TCP_endpoint:port',
FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
'<secondary instance>' WITH
(ENDPOINT_URL = 'secondary_TCP_endpoint:port',
FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
GO
2. On the secondary replica, grant CREATE ANY DATABASE to the AG, as shown in the code sample below:
:Connect <secondary instance>
ALTER AVAILABILITY GROUP <AG Name> JOIN;
GO
ALTER AVAILABILITY GROUP <AG Name> GRANT CREATE ANY DATABASE;
GO
Execute the full script after these edits to create an AG with automatic seeding.
Adding a replica to an existing AG
To use automatic seeding while adding a replica to an existing AG, add the replica as you would normally do, and after the replica is added, do the following two steps to start the seeding:
- On the newly added secondary replica, grant CREATE ANY DATABASE to the AG, as shown in the code sample below:
-- on the newly added secondary
ALTER AVAILABILITY GROUP <AG Name> JOIN;
GO
ALTER AVAILABILITY GROUP <AG Name> GRANT CREATE ANY DATABASE;
GO
- On the primary replica, modify the seeding mode for the newly added secondary replica, as shown in the code sample below:
-- on the primary
ALTER AVAILABILITY GROUP <AG Name>
MODIFY REPLICA ON <secondary instance> WITH (SEEDING_MODE = AUTOMATIC)
GO
Automatic Seeding is Faster than Backup-Restore
Automatic seeding eliminates the need for an intermediate file share for writing backup file and then use those backup files for restore. This helps reduce the end-to-end seeding time for an AG. Sweet!
Figure 2 compares the time taken to seed a database of about 115 GB through backup-restore (with backup compression) and automatic seeding.
[caption id="attachment_2955" align="alignnone" width="932"]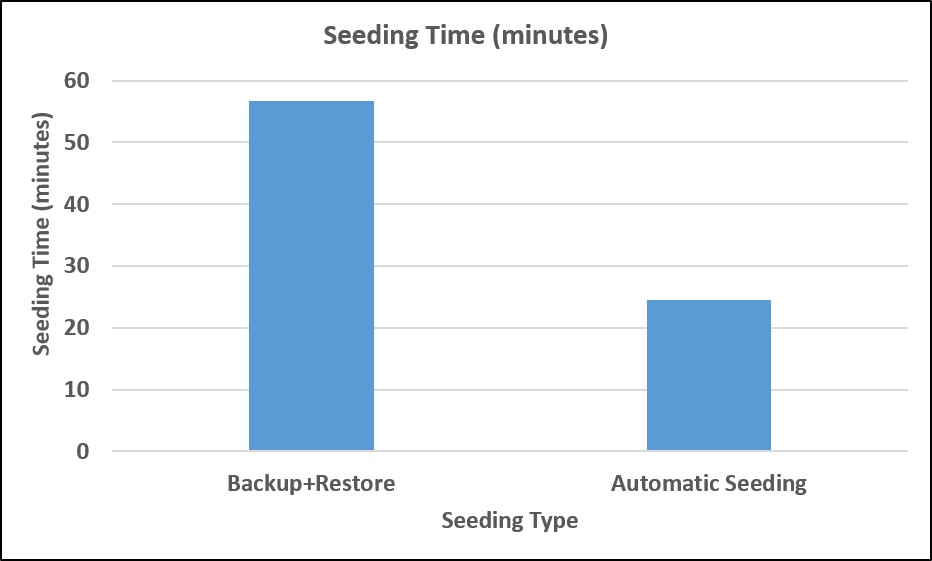 Figure 2: Automatic seeding faster than backup+restore[/caption]
Figure 2: Automatic seeding faster than backup+restore[/caption]
You can reduce the network traffic while seeding by compressing the stream. Use trace flag 9567 to compress the seeding stream. As illustrated in Figure 3, you can see significant reduction in network traffic.
[caption id="attachment_2945" align="alignnone" width="901"]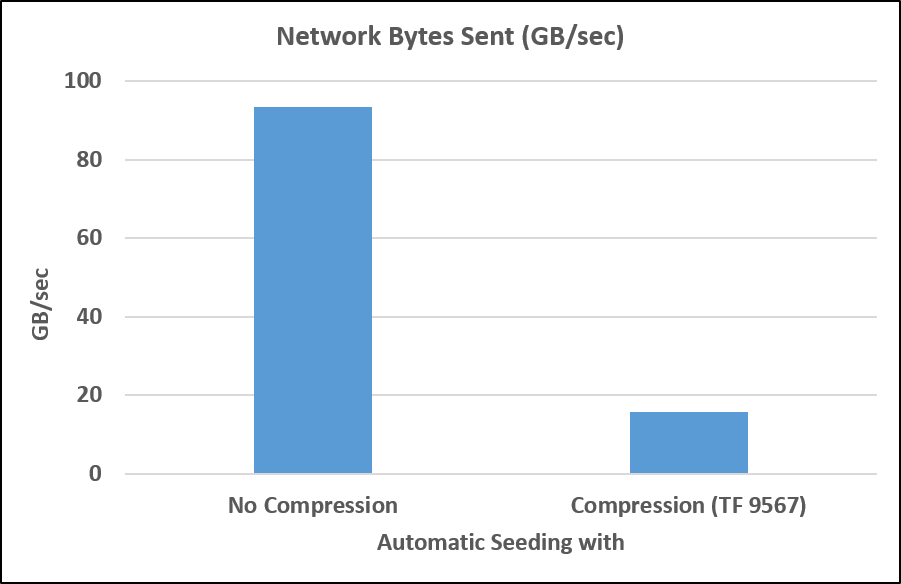 Figure 3: Reduced network traffic using seeding compression[/caption]
Figure 3: Reduced network traffic using seeding compression[/caption]
Important to Know
There are a couple of things to be aware of while using automatic seeding.
Transaction Log cannot be Truncated while Seeding
Automatic seeding blocks log truncation. If there is no or little workload on the primary while seeding the secondary, then there may be no impact. But if there is a workload on the primary generating significant transaction log, then you may run the risk of filing up the transaction log file. Be aware of the workload volume, log growth rate, and time to seed the replica(s) while using automatic seeding.
When using automatic seeding be aware that there is a known issue with diagnosing the reason for blocked log truncation. When log truncation is blocked for other reasons, the LOG_REUSE_WAIT_DESC column in the sys.databases view reflects the reason for the hold up. However, when log truncation is blocked due to automatic seeding, the LOG_REUSE_WAIT_DESC column in the sys.databases view shows value of “NOTHING”, indicating that nothing prevents log truncation and the log can actually be truncated (when a log backup is taken), which is misleading. This is a known issue, and is expected to be addressed in the product soon.
Incorrect value in the is_compression_enabled column in sys.dm_hadr_physical_seeding_stats while using compression
The DMV sys.dm_hadr_physical_seeding_stats shows the status of current ongoing seeding activities. The is_compression_enabled column in this DMV reflects whether the seeding is being done with compression (using trace flag 9567) or without compression. However, there is a known issue on this. While seeding with compression, this column shows a value of 0 (meaning no compression), which is incorrect. This known issue is expected to be addressed in the product soon.
My Wish List
Given that automatic seeding reduces the seeding time significantly, it is a very useful feature. I have three items on my wish list to make it practical for more scenarios.
- The Create AG wizard to have an option to specify automatic seeding. Generating the script through the wizard and then editing it cumbersome and error-prone. An option in the wizard to specify automatic seeding will significantly improve user experience.
- Should be able to truncate the log while seeding in progress. Filling up the transaction log file or the log drive is nightmare for any database. All activities on the database will come to a halt till log space is cleared. To eliminate that risk, it will be great if automatic seeding can read from transaction log backups, and allow the transaction log to be truncated while the seeding is in progress.
- The Create AG wizard and the DDL should provide an option to enable compression when using automatic seeding, instead of a trace flag (trace flags are instance level settings, whereas automatic seeding is scoped to an AG).
What is on your wish list?
Call to Action
Try out automatic seeding with your big and highly active databases, and let us know of your learnings, and share some data points, such as the time to seed, amount of compression achieved for the seeding stream (using trace flag 9567), log growth while seeding, etc. For further reading, the blog post from our Support team is a very good read, especially for troubleshooting scenarios.