Introduction to data science, machine learning, and the partner opportunity

At Build 2016, Microsoft CEO, Satya Nadella, outlined our approach for the new era of conversational intelligence, based on a belief that the most impactful data-driven solutions will go beyond analytics, and utilize the best of big data, cloud, and intelligence capabilities. Microsoft Azure Machine Learning, now part of Cortana Intelligence Suite, is democratizing data and intelligence. Its best-in-class algorithms and simple drag-and-drop interface let data scientists quickly and easily go from idea to deployment.
Since Build, I have been working with Azure Machine Learning and the Azure Machine Learning Studio, and thinking about the opportunities for partners to add more value to business intelligence, reporting, SharePoint, and data engagements.
This is really a new monetary stream for your customer where they can provide their IP and domain expertise as a service to their customers. In this age of technologies, business decision makers are looking for ways to bring in other sources of revenue. So it is important that you as a partner can provide this kind of business value to your end customers.
More and more, companies are employing data scientists to help them understand the data they have, and gain business insights from that data to make decisions about business strategy and direction. Think of data science as an interdisciplinary field where computer science and business analytics intersect.
The data science process
To understand the value of Microsoft intelligence and analytics tools to your customers, let’s look at the steps a data scientist takes to create a machine learning model for interpreting and evaluating existing data in order to forecast behaviors, outcomes, and trends.
- Find relevant data
- Acquire data
- Process and transform data
- Mine the data
- Deliver insights and value from data
These steps are iterative. Consider this a computer science problem, where there is a closed loop of feedback and input that continually improves the algorithm.
Step 1: Find relevant data
To identify the sources of data to use for solving a business problem or gaining important business insights, a data scientist should think broadly, and may need to collect analog sources of data in addition to digital sources.
For example, if you’re interested in using predictive analytics to build a preventive maintenance schedule for elevators in a building that is several decades old, maintenance records are likely to be on paper. To include the data from those paper records, you’ll need to digitize them first.
Step 2: Acquire data
The data need to be in an electronic format—a spreadsheet, SQL table, digitized documents, etc. Many companies have disparate data sources in various systems. A data scientist needs to acquire data from these systems and could use Azure SQL Data Warehouse to point to those disparate data sources.
Here are Azure Machine Learning Studio modules for finding and acquiring data:
Azure Machine Learning Studio has sample datasets you can use to practice the above modules as well as those in the remaining steps of the process.
Step 3: Process and transform data
After acquiring the data, you may need to group, or quantize, the data. You can assign data types for variables like Boolean, String, Integer, and more. You can create ranges of data, like age groups for user demographics.
In the elevator maintenance example introduced earlier, knowing the exact length of time since the cable was replaced may not be necessary. We could create categories of less than one year, 1 to 2 years, 2 to 4 years, and more than 5 years.
The data that have been acquired may need additional work, for things like blank fields, incomplete information, or irrelevant data. Processing and transforming the data to prepare it for use includes cleaning missing data, removing duplicate rows, clipping or rounding off outliers, and normalizing data for scale.
Step 4: Mine the data
At this point, we have relevant data in a usable format. It’s time to study, or mine, the data. Visualizations are a commonly used tool that help a data scientist understand relationships in the data and spot trends in certain columns or where one data value affects another.
Data visualization can take many forms: trend lines, scatter plots, histograms, or box plots. There are visualization libraries in both R and Python, and Microsoft Excel also has tools that help with visualization. You can also utilize these resources:
Step 5: Deliver insights and value from data
We now know the columns, or features, that are relevant to our machine learning problem. In some cases, we might need to insert calculated columns to help with the problem at hand. At this point, we also need to decide on the machine learning algorithm to use. Algorithms in machine learning can be categorized as supervised or unsupervised. I’ve provided a summary about these below, and there is a useful cheat sheet and user guide available from the Azure Machine Learning team, too.
- Machine learning algorithm cheat sheet
- How to choose algorithms for Microsoft Azure Machine Learning
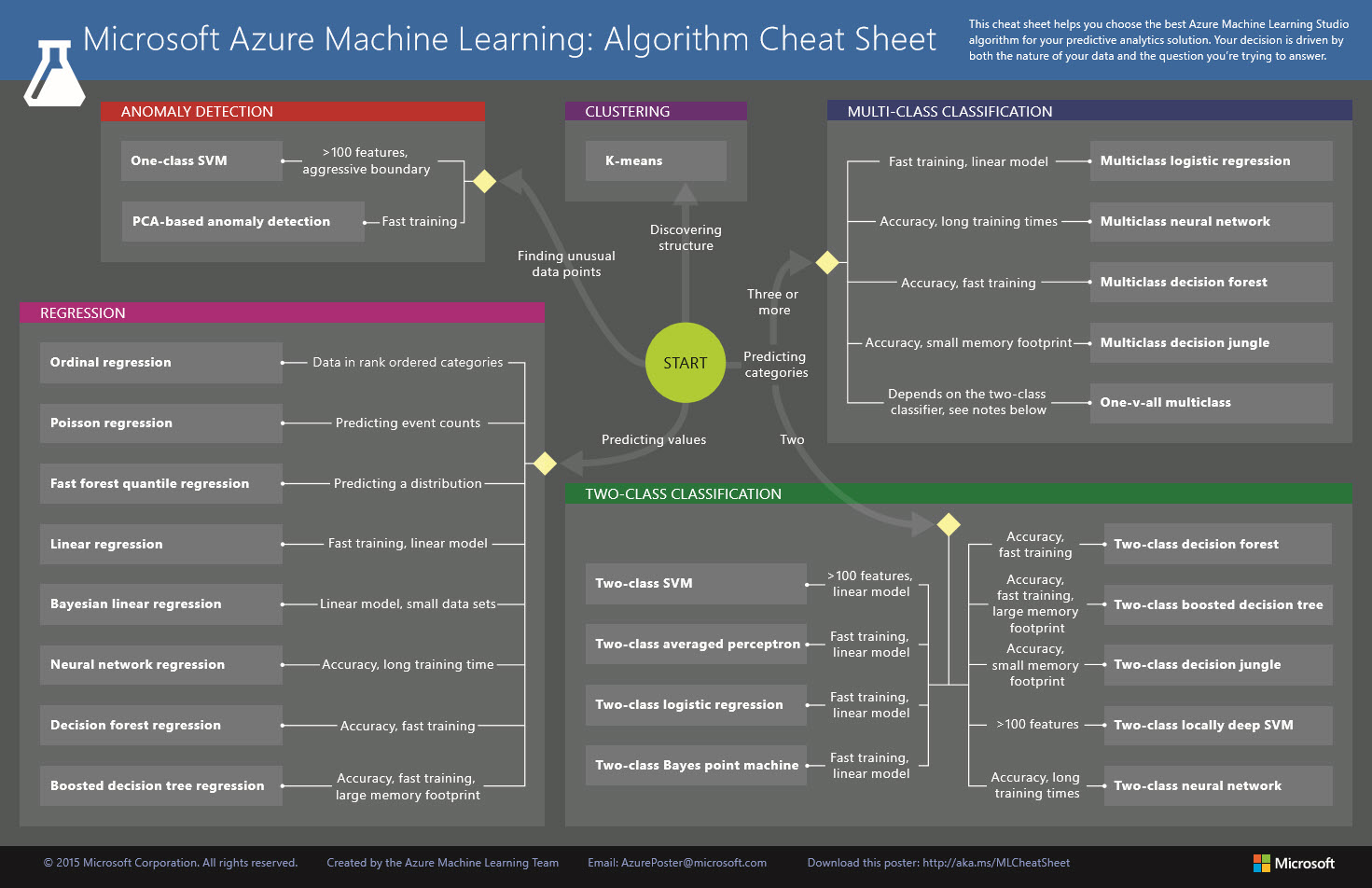
Supervised algorithms
Known data values are used to train a machine learning model. A function is created that accurately calculates known values in a dataset and can also can be used to predict unknown values for a test set of data. In Azure Machine Learning, you would use the Evaluate Model module to determine model performance and then determine the optimum parameter settings by performing a parameter sweep using the Tune Model Hyperparameters module. Finally you use the Cross-Validate Model module to ensure that the function and coefficients in the model are generalizable.
- In a regression algorithm, the output is the actual value that is being predicted. So the model is a function y=f(x), which gives out numeric values of y for values of x. In our elevator example, we could use a regression algorithm to find out how many more months an elevator work correctly given certain conditions. You can find this in Excel also. Learn more about regression algorithms
- In a classification algorithm, the output is a Boolean value—Yes or No, True or False. For example, “Given these conditions, will this elevator fail?” Learn more about classification algorithms
Unsupervised algorithms
Data points are organized in a certain way so that their structure can be described. In a clustering algorithm, data are grouped together in entities based on certain features. These are harder algorithms since there is no training set associated to train the model and compare results. Learn more about clustering algorithms
Recommender systems
A recommendation system recommends one or more items to users of the system. For example, online shoppers often get recommendations about what they might like based on their buying patterns. Recommenders may use regression, classification, or clustering models. A common approach is to create a filter-based recommender that uses matrix factorization. Azure Machine Learning supports the Matchbox model, which uses this approach. Learn more about recommender systems
In Azure Machine Learning, prepare data for a recommender using the Recommender Split option in the Split Data module. This distributes user-item pairs evenly between the training and test data sets.
After splitting the data, use the Train Matchbox Recommender module to train a recommender. Then, use the Score Matchbox Recommender module to generate the following kinds of predictions:
- Item Recommendation – predict recommended items for a given user
- Related Items – predict recommended items for a given item
- Rating Prediction – predict ratings for given users and items
- Related Users – predict users related to a given user
To measure the accuracy of predictions made by a recommendation model, use the Evaluate Recommender module.
Publishing your training experiment
In Azure Machine Learning Studio, you can quickly publish your machine learning experiment as a web service and make it publicly available. Follow the steps in this article to deploy an Azure Machine Learning web service. It can be imported as an add-in in Excel or Excel Web App so that an end user can use it to predict the values.
Bringing it all together
We have reviewed the five steps involved in a data science problem and explored how Azure Machine Learning addresses each step. In the Cortana Intelligence Gallery, you can see examples of this process from start to finish in these published experiments:
- Binary Classification: Credit risk prediction
- Regression: Demand estimation
- Recommender: Restaurant Ratings
More datasets and learning resources for data scientists are available on the Data Science at Microsoft Research page.
Now that you have a better understanding about the possibilities of machine learning, and how Azure Machine Learning is democratizing data and intelligence by making the tools and resources accessible to everyone, you should be able to start spotting use cases as you work with your customers. Look for opportunities to provide predictive analytics when you are working on your next SharePoint, reporting, or BI engagement.