Protect It
Safeguard Database Connection Strings and Other Sensitive Settings in Your Code
Alek Davis
This article assumes you're familiar with C# and Visual Basic .NET
Level of Difficulty123
SUMMARY
Protecting application secrets, such as database connection strings and passwords, requires careful consideration of a number of pertinent factors such as how sensitive the data is, who could gain access to it, how to balance security, performance, and maintainability, and so forth. This article explains the fundamentals of data protection and compares a variety of techniques that can be used to protect application settings. The author discusses what to avoid, such as hiding keys in source code and the use of Local Security Authority. In addition, he presents some effective solutions such as the Data Protection API.
Contents
Data Hiding
Restricting Access to Data
Encrypting Data
Weighing Your Options
Storing Encrypted Data
One-way and Two-way Encryption
Hashing Algorithms
Encryption Keys
Protecting Cryptographic Keys
Beware of Local Security Authority
Using DPAPI
Hiding Keys in the Application Source Code
Isolated Storage
Conclusion
The problem of protecting database connection strings, passwords, and other sensitive application settings is frequently discussed in developer newsgroups and online forums. While most security professionals agree that it is impossible to hide secrets using software, there are certain known techniques that can provide sufficient protection for most types of applications. All existing methods of data protection are based on three fundamental techniques: hiding, access control, and encryption. These techniques can be used individually or in combination. Whether you decide to protect application secrets by choosing an existing technology or by building your own data protection mechanism, your basic options will be limited to these three methods.
In this article I will discuss the fundamentals of data protection and compare several techniques that can help you better manage confidential data. I will identify the scenarios in which these techniques are appropriate and the times when they should be avoided. I will also provide references to code samples, tools, and APIs that can help you implement a data protection mechanism.
Data Hiding
Data hiding is sometimes referred to as security through obscurity. If you rely on this technique, you assume that only you know where sensitive information is stored and hope that nobody else will be able to figure it out. The caveat here is that the application must also know how to access the data, so being able to keep the secrets safe will largely depend on the ability of the application to protect this knowledge.
The most common places for hiding sensitive application settings include the application source code, configuration files, and the Windows® registry. Data can also be stored in such exotic locations as the IIS metabase, Universal Data Link (UDL) files, custom files, and elsewhere.
With few exceptions, simply hiding data offers little, if any, security. In most cases, the amount of work it requires for a hacker to discover your secrets is minimal. For example, an intruder may be able to discover the location of data by monitoring system changes performed by the running application (see Figure 1). This can be done with the help of utilities such as regmon, filemon, and diskmon from SysInternals.

Figure 1** Regmon **
The ease of decompiling .NET assemblies poses an even more serious threat. Using decompilers like Anakrino or Salamander, the application source code can be reverse engineered, exposing sensitive data or the application logic (see Figure 2).

Figure 2** Decompile **
Restricting Access to Data
If access to data is restricted, its location does not need to be kept secret. Instead, this technique relies on the technological features built into the operating system, which can prevent unauthorized entities from accessing data. Normally, access restrictions are based on the caller's identity or knowledge of a common secret (see Figure 3). Access Control Lists (ACLs), the Microsoft® Data Protection API (DPAPI), and isolated storage use this technique to protect data.
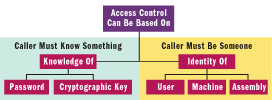
Figure 3** Access Control **
When applied correctly, restricted access can be one of the most efficient security measures, but unfortunately it has limitations. For example, access control based on user identity does not work well for applications running as anonymous users or under different user contexts. Another problem with identity-based access control is that it may not prevent different applications running under the same identity from accessing each other's data. Figure 4 lists common issues associated with identity-based access controls.
Figure 4 Problems with Identity-based Access Control
| Identity Type | Problems |
|---|---|
| User | Will not work for applications running as anonymous users, such as ASP.NET applications. Will not work for applications which can run under multiple identities. Requires data to be set and retrieved by the same user. Allows unrelated applications running under the same user identity to access each other's data. |
| Machine | Allows all applications running on the same machine to access each other's data. May lose data if the machine is rebuilt. |
| Assembly | Requires data to be set and retrieved from the same application. Only supported by code access security and isolated storage. |
On the other hand, when access control is based on the knowledge of a secret, protecting this secret becomes a problem. Additional difficulties associated with restricted access depend on a particular implementation. For example, ACLs can be hard to manage in a large enterprise environment and protected storage may require administrative privileges on the part of the caller, thus violating the rule of least privilege.
Encrypting Data
When encryption is used, neither hiding nor controlling access to data are the primary goals. Since the information is encrypted, knowing where to find it and being able to access it does not necessarily make the information useful to an unauthorized person—unless the intruder finds the decryption key.
Even though it is a time-tested data protection technique, encryption does not offer a perfect solution, but merely transforms the problem of protecting data into a problem of protecting cryptographic keys. As with any other types of sensitive data, cryptographic keys are protected using the same techniques: hiding and access control.
When choosing or building a data protection mechanism, you should weigh its vulnerabilities against potential threats. This assessment may be easier if you think of your solution in terms of the basic data protection techniques already discussed. For example, if you store database connection information containing a user's SQL credentials in a UDL file (see Figure 5), your data security essentially relies on file permissions (ACLs), which are a form of restricted access. (To a certain degree, it also relies on data hiding, but in this particular case, data hiding is a very weak security measure because it takes little effort to find a UDL file.) While ACLs play a vital role in data protection, it is important to understand that if a hacker manages to get read access to the UDL file, your SQL credentials will be revealed.
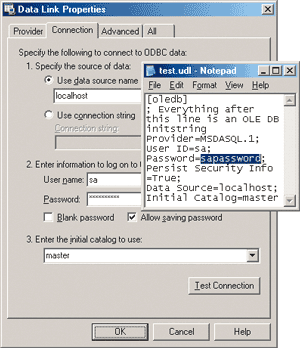
Figure 5** Credentials in UDL File **
Unless the potential threat is very low or your data is not very valuable, you should avoid solutions that use just one data protection technique. Normally, the more techniques the solution employs, the more secure it is.
Weighing Your Options
As has already been said by many security experts, the best method of protecting secrets is not keeping secrets in the first place. For example, if you want to protect database connection strings containing SQL credentials, consider not using SQL authentication. If your application can use Windows authentication to connect to a database server instead of SQL authentication, you will not need to worry about protecting SQL credentials at all.
Unfortunately, storing sensitive information cannot always be avoided. If you absolutely need to store confidential data, start your search for the right solution by analyzing your application and its security requirements. The following questions can help to determine which option will work best for you:
- How valuable is the information you are protecting? What kind of damage can you expect to suffer if your data security is compromised?
- What kind of users are you protecting your data from? Are you protecting data from opportunistic hackers such as employees who would love access to the information they are not supposed to see, but who will not intentionally attack the system? Or are you protecting data from motivated hackers who are willing to spend time, effort, and money to compromise the system? How far do you think a potential hacker would go to get your data?
- Does your application absolutely need to know the unencrypted text of the sensitive data?
- Are you protecting database connection strings, or do you also want to manage other types of data?
- How many identities does the application accessing your data use? Does it run under a single user identity or does it use multiple user identities?
- Which versions of the operating system is it necessary for the application to support?
- What is more important, application performance or security? Will you be willing to sacrifice performance to achieve a more secure application?
- What is the mechanism responsible for defining data? Is it done manually, using a text editor for example, or is it done programmatically? If the data is created programmatically, are the application settings being defined from the same application that uses them or from another application?
- How many applications in your organization or company use data protection? If it's more than one application, do they all have the same requirements? Do you want to reuse a single solution, which satisfies the requirements of all applications, or do you want to have a different data protection mechanism for each of your applications?
- When your application is deployed, how hard will it be for support personnel to manage its security? Will the team supporting your application accept your solution?
Depending on the answers to these questions, you may want to choose one approach over another. Later in this article, I will look at several data protection technologies which can be used for the most common types of applications, but first I will outline certain options you should avoid under any circumstances.
All methods of storing sensitive data in plain text are considered insecure because they can expose data to anyone who manages to get read access to the data source—a task that may be easier than you think. You should avoid keeping unencrypted data in the Windows registry, configuration files, the COM+ catalog, isolated storage, custom files, the IIS metabase, and UDL files. Moreover, you should never, ever store sensitive data in plain text.
You may never achieve absolute security, but sufficient security is definitely feasible. Some applications have security requirements that call for complex and unorthodox solutions, especially in areas like banking, military secrets, law enforcement records, and scientific research. Most, however, entail the following three steps: encrypting data, restricting access to encrypted data using ACLs, and hiding and restricting access to encryption keys.
When implementing data protection, you may consider other security aspects such as data tampering, but since data tampering does not affect secrecy, I will not be discussing it in this article. Instead, I will cover the more practical issues of where to store your encrypted data, which type of encryption and cryptographic algorithm to use, and how to protect your cryptographic keys.
Storing Encrypted Data
Unless you have a compelling reason to do otherwise, store encrypted data in the application configuration files or Windows registry. The main advantages of both options include the ability to protect data using ACLs and the ease of programmatic access. Any other type of data storage is likely to lack at least one of these advantages and even though it might add another benefit, it is unlikely to justify the extra implementation effort.
Although some developers insist that Microsoft .NET Framework-based applications should never use the registry, it is not written in stone. The main shortcoming of the registry is that it does not fit well in the XCOPY deployment scenario, but since many applications these days are deployed with the help of setup programs and require certain configuration steps to be performed on the systems where they are installed, XCOPY compliance may not be necessary. Another drawback of the registry is that it is specific to the Windows platform and may not work with other operating systems. This limitation will only become a major problem when platforms other than Windows start supporting the common language implementation (CLI).
If you care about XCOPY deployment or interoperability with platforms other than Windows, use configuration files; otherwise, select the option that best fits your needs. If you have to store settings that are shared by several applications, or define these settings programmatically, you may find the registry easier to manage. Application-specific settings, which are not changed programmatically, can be stored in configuration files. In either case, do not forget to apply appropriate ACLs to the data store. For example, it would be a good idea to assign the read-access rights on a file or registry key holding sensitive data to the user account under which the application runs. Similarly, write-access should be explicitly assigned to the user—or a group of users (such as Administrators)—allowed to modify data. Everybody else should be denied all access rights.
One-way and Two-way Encryption
There are two methods of encrypting data: one-way (commonly called hashing) and two-way. Technically, hashing is not encryption, but because both techniques can address data protection in a similar manner—that is, by transforming plain text data into ciphertext—I will treat them as logical counterparts.
While hashing can serve other purposes, in the area of data protection it offers certain advantages over two-way encryption. First, hashing is a bit easier to use. Second, because hashing does not use encryption keys, it eliminates the key management problem, which will be discussed later in this article. The main disadvantage of hashing is that it does not support decrytion, but in a few cases this problem can be a blessing in disguise.
Password-based authentication is a typical case in which hashing is more appropriate than two-way encryption. If your application keeps passwords for authentication purposes only, do not encrypt them with a symmetric or public key, but store their hashed values instead. When a user logs in, instead of decrypting and comparing plain text passwords, the application can compare password hashes. To reduce the risk of dictionary attacks, always use salt values with hashes. A salt value is random data that is appended to the plain text before it is hashed and stored along with the hash so it can be used later when another plain text value is compared to the hash. To see an example of using salted hashes for password-based authentication, check out the Security Briefs column in the August 2003 issue of MSDN® Magazine.
Hashing Algorithms
MD5 and SHA-1 are the most popular hashing algorithms. SHA-1 hashes are 160-bits long, while MD5 hashes are 128-bits long. The SHA-1 algorithm is a little slower, but more secure than MD5. In addition to MD5 and SHA-1, the .NET Framework provides support for 256, 384, and 512-bit versions of the SHA algorithm, which should be even more secure, though probably slower.
The easiest way to hash data is by calling the HashPasswordForStoringInConfigFile method of the FormsAuthentication class, as in the following example:
using System.Web.Security; ••• string base64HashValue = FormsAuthentication.HashPasswordForStoringInConfigFile ("mypassword", "sha1");
The Loaded User Profile
Even though Microsoft documentation lists a loaded user profile as one of the requirements of an application that wants to use DPAPI with a user store, it does not define exactly what a loaded user profile is. If you are puzzled by this term, you can think of it as the profile of an interactive user, which is created when the user first logs onto the system. All applications launched by users interactively run with the loaded profile of the interactive user. Noninteractive applications, such as Windows services configured to run as LocalSystem, cannot load a user profile, and therefore cannot use DPAPI with a user store. The same is true for system processes, such as the ASP.NET process, which run as built-in system accounts. To allow Windows services to use DPAPI with a user store, they must be configured to run as a local or domain user with an already created profile. In practical terms, this means that the user must log onto the system interactively at least once before the application can make DPAPI calls on behalf of the user.
Unfortunately, this method only supports MD5 and SHA-1 hashing algorithms, so if you want to use SHA-256, SHA-384, or SHA-512 hashes, you will need to write a few more lines of code. An example at How To: Hash Data with Salt explains how to generate and compare hashes using different hashing algorithms.
Encryption Keys
If your application needs to know the text values of sensitive data, you cannot use hashing. In this case, use two-way encryption with either symmetric or public-private keys. If you are not sure which type of encryption keys to choose, use symmetric keys. The main disadvantage of public-key encryption is slow performance, which can be in the range of 1,000 times worse than symmetric-key encryption. Public-key encryption also imposes certain limitations on the size of the text-based data that can be encrypted. While public-key encryption can be used for data protection, practically anything you want to do using public keys can be accomplished with the help of other technologies. Because public keys are best suited for secure key exchange and digital data signing, I will omit them from this discussion and concentrate instead on symmetric-key encryption.
When choosing an encryption algorithm, it makes sense to select the most secure algorithm with the longest possible key. Out of all symmetric-key algorithms supported by the .NET Framework, the U.S. government-approved Rijndael algorithm (also referred to as the Advanced Encryption Standard, or AES, algorithm) is considered the most secure. This algorithm supports 128, 192, and 256-bit keys. See the article "Encrypt It: Keep Your Data Secure With the New Advanced Encryption Standard" by James McCaffrey in this issue for more information about Rijndael.
The Rijndael algorithm has another advantage over other symmetric-key algorithms supported by the .NET Framework. While other algorithms are offered in the form of thin .NET Framework wrapper classes over existing CryptoAPI modules, Rijndael (implemented as the RijndaelManaged class) is written completely in managed code. Note that some developers consider this a disadvantage and prefer to use an unmanaged implementation of the Rijndael algorithm to achieve better performance.
Unfortunately, this implementation of the Rijndael algorithm is only supported on Windows XP or later and on the systems with the .NET Framework installed. If your application needs to be compatible with unmanaged applications running on Windows 2000 or earlier, use Triple DES, which is a better version of the less secure DES algorithm. The Triple DES algorithm supports 112 and 168-bit keys, though 168-bit keys are recommended. Due to inconsistencies in the way the parity bits of the key are treated, 168-bit Triple DES keys are sometimes referred to as 192-bit keys. If you want to allow a managed and an unmanaged application to encrypt or decrypt data with the same Triple DES key, be aware that the pass phrase (password) from which the key is derived should only contain printable ASCII characters; otherwise, the generated keys will not match (this is due to a limitation of the .NET implementation of the Triple DES algorithm).
Original DES, RC2, and RC4 algorithms are generally considered less secure than Rijndael and Triple DES and therefore should be avoided. Under no circumstances should homegrown encryption algorithms be used. Never assume that if you are the original author of code, nobody will be able to crack it.
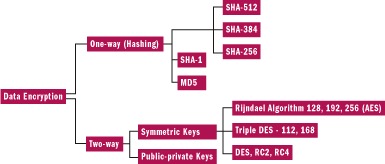
Figure 6** Data Encryption Schemes **
Figure 6 describes the various data encryption schemes that you can use.
Protecting Cryptographic Keys
When using symmetric keys to encrypt and decrypt application data, it is important to be able to generate the same key over time. This poses the problem of protecting keys or key generation logic (not to be confused with encryption algorithms). While several techniques can be used to accomplish this task, they all have shortcomings. Let's look at the available options and the scenarios for which they are most appropriate.
Persistent symmetric keys can be generated in two ways: by defining the key yourself or by letting the operating system do it for you. When choosing the first option, you can hardcode the actual key bytes in the application source code or implement a consistent logic to derive the key from certain unchangeable characteristics. These characteristics normally include a pass phrase, from which the key is derived, and may also include other values such as an initialization vector. Whether hardcoding the key bytes or implementing the key generation logic, you are essentially hiding the key in the application source code. This option gives you more control and flexibility, but it also puts your data at greater risk if your application source code is reverse engineered. Alternatively, you can store the key in a persistent location, such as a file or the registry, and protect this location by ACL. However, because this approach is prone to maintenance errors, I don't recommend it.
A more secure, but also more restrictive way of generating the key is to let the operating system do it for you. This can be done using such operating system features as Local Security Authority (LSA) or DPAPI.
Beware of Local Security Authority
During the heyday of Windows NT® 4.0, the LSA Policy functions LsaStorePrivateData and LsaRetrievePrivateData provided a reasonably secure way of protecting application secrets. Although the LSA Policy functions are available on Windows 2000 and later (and still used for protecting such settings as passwords defined for Windows services), Microsoft does not recommend them, so I am only mentioning these functions for completeness and to explain why they should be avoided.
One problem with the LSA Policy functions is that along with key management and encryption they handle data storage using the protected area of the Windows registry. This may seem like a good thing, but it is not because the amount of storage available to the LSA Policy functions is limited to 4096 slots, half of which are already taken by the system. If applications keep using the LSA Policy for storing sensitive data, they will be at risk of running out of space. Next, because only highly privileged users can call the LSA Policy functions, they will not work for applications running under unprivileged accounts, such as ASP.NET. What's worse, there are tools such as LSADUMP2, which can reveal the LSA secrets. The bottom line: do not use the LSA Policy functions for data protection.
Using DPAPI
As an alternative to the LSA Policy functions, Microsoft recommends using a subset of CryptoAPI called DPAPI. DPAPI includes two functions which can be used for data protection: CryptProtectData and CryptUnprotectData. These functions are implemented in crypt32.dll and can also be called from .NET Framework-based applications via P/Invoke. DPAPI is part of the operating system and is available on Windows 2000 and later.
Unlike the LSA functions, DPAPI does not handle data storage, but it can generate machine- or user-specific keys to encrypt and decrypt data. To differentiate between the two types of keys, DPAPI documentation refers to them as machine store and user store.
Machine-specific keys are generally not safe because they can be used by anyone who gains access to the system. It is possible to generate a more secure version of a machine-specific key by passing a password (also known as secondary entropy) to a DPAPI function. This option is better because it requires a caller to know the value of this password, but it also creates the challenge of storing the password, which brings us back to the original problem. Another issue with machine-specific keys is that they are not guaranteed to be the same if a change in the environment occurs. Such changes as moving the application to another computer or rebuilding the system can risk breaking the application using DPAPI with machine-specific keys.
While user-specific keys are considered more secure, they have the same limitations as any other type of identity-based access control. First, because user keys can only be generated by programs running with loaded user profiles, they will not work with ASP.NET applications and applications running as certain built-in accounts. While there is a way to overcome this limitation by using serviced components, it comes at a cost of greater complexity and degraded application performance. It also requires a serviced component to run under a privileged account, which violates the principle of least privilege. If you decide to use DPAPI with user-specific keys, you must also be aware that only the user who encrypts data can decrypt the results. Obviously, this will not work for applications that can run under different user accounts or whose settings can be defined by different users. Another problem with user-specific keys is that they allow all applications running under the same user profile to access each other's data, which can be a potential security breach. As with DPAPI using a machine store, this problem can be also addressed by requiring the caller to provide secondary entropy, but as in the previous example it will pose a problem of storing this entropy. Unfortunately, DPAPI does not allow you to use machine and user-specific keys at the same time (on the same CryptProtectData call).
DPAPI is recommended for applications that run under the single user account with a loaded user profile and whose settings are defined by the same user. (For more information, see the sidebar "The Loaded User Profile.") A typical example would be a Windows service application running under an account of a local or domain user. If your application satisfies these requirements, it should use DPAPI with user-specific keys. For other applications, you can use DPAPI with machine-specific keys protected by secondary entropy (see "Use DPAPI (Machine Store) from ASP.NET" or the sample at Use DPAPI to Encrypt and Decrypt Data). You can define this entropy in the application source code and obfuscate the application binary so the entropy cannot be easily found. If you choose this approach, however, be aware that even obfuscated code can be reverse engineered. To find out what obfuscation can and cannot do for you, read the article "The Premier Obfuscator for Microsoft .NET Applications!" by Brent Rector at and "Obfuscate It: Thwart Reverse Engineering Attempts on Your Visual Basic .NET or C# Code" by Gabriel Torok and Bill Leach in this issue.
If your application cannot use DPAPI with user-specific keys directly and cannot tolerate the risk of reverse engineering, consider implementing DPAPI with a serviced component, but be aware that this option will affect your application's performance. (see "Use DPAPI (User Store) from ASP.NET with Enterprise Services"). If you choose this option, be prepared to implement an authorization scheme to prevent malicious applications and users from calling the serviced component, which may not be a simple task. To see how this issue can be addressed, take a look at the CipherSafe.NET tool and the accompanying documentation; this application illustrates the use of DPAPI for sensitive application management and offers an interesting approach to solving the authorization problem.
Hiding Keys in the Application Source Code
While security professionals keep urging application developers to stop "hiding" cryptographic keys (and other sensitive data) in their application source code, application developers continue ignoring this advice. The explanation of this resentment can be twofold. One obviously inexcusable reason why developers choose this approach is that it is very easy to implement. The other explanation is that the alternative options may not work in some situations. For example, consider a scenario in which several applications (say Windows services) running on different computers have to use the same key for encrypting and decrypting data stored in a database. In this situation, using DPAPI for encryption is not practical, so developers may choose to embed the key in the application source code. This would be easy, but not secure. A better approach would be to require an administrator to define the encryption key at application installation, encrypt its value via DPAPI with a user-specific key of the account under which the application runs, and save the encrypted value in the Windows registry or the application configuration file. Be aware, though, that while this method is a more secure technical implementation, it poses procedural challenges.
Another situation in which embedding the key in the application source code may be the only option is when the application data owners have limited or no access to the machines hosting their applications. A Web hosting environment is one of the obvious examples. If embedding the key in the application source code is your only option, you must realize the associated risks and address them accordingly.
The major risk in this case comes from reverse engineering and at this time it can only be addressed by obfuscation. Obfuscation does not make reverse engineering impossible, but it can make the process expensive and time consuming. Compare Figure 7, which shows a decompiled assembly obfuscated by a Demeanor, to Figure 3. Because all nonpublic symbols in the obfuscated assembly are renamed using unprintable characters and the strings are encrypted, reconstructing application logic from the assembly may be next to impossible. Commercial decompilers, such as Salamander, can make the job of reverse engineering easier by converting nonprintable characters to their printable equivalents and converting application classes into source files, but they cost money and still require a hacker to make sense of the unreadable symbols (this is where spaghetti code could actually help you!).
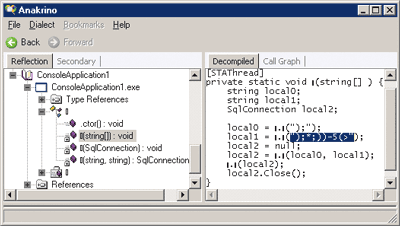
Figure 7** Decompile of Obfuscated Assemblies **
If you define the key in the application, in addition to obfuscating the assembly, try not to store the actual key bytes in the source code. Instead, implement key-generation logic using persistent characteristics, such as the encryption algorithm, key size, pass phrase, initialization vector, and salt (see an example at Encrypt and Decrypt Data Using a Symmetric (Rijndael) Key). This will introduce an extra layer of indirection, so the key will not be accessible by simply dumping the symbols from the application binary. As long as you do not change key-generation logic and key characteristics, the resulting key is guaranteed to be the same. It may also be a good idea not to use static strings as key-generation characteristics, but rather build them on the fly. Another suggestion would be to treat the assembly the same way as the data store should be treated, that is, by applying the appropriate ACLs. And only use this option as a last resort, when none of the other data protection techniques work and your only alternative is leaving sensitive data unencrypted.
Isolated Storage
Isolated storage is sometimes mentioned as a method of protecting data. It lets you restrict data access to the application assembly. While this option can be helpful, isolated storage is not recommended for protecting sensitive data because it does not use encryption; it is better suited for storing user-specific application settings. To store sensitive user-specific application data, use DPAPI along with isolated storage.
Conclusion
When it comes to protecting sensitive application data, there are no perfect solutions. None of the existing software technologies can guarantee absolute security. The goal is to pick the best, or "least worst" option that will work for your application and comply with your security requirements. Understanding how the various techniques and technologies provide data protection will help you assess vulnerabilities and prevent you from succumbing to a false sense of security.
Whether you decide to build or buy a data protection solution, make sure that it uses strong encryption, provides reasonable protection for cryptographic keys, and restricts access to encrypted data. While no software solution will make your application data absolutely safe, the right approach can help you avoid the most common types of security breaches.
For related articles see:
Data Access Security
Security: Protect Private Data with the Cryptography Namespaces of the .NET Framework
Windows Data Protection
For background information see:
Create an Encryption Library
Store an Encrypted Connection String in the Registry
Writing Secure Code
Alek Davis is a senior developer of a security engineering team at Intel Corporation in Folsom, CA. He has experience in developing apps for Windows with a focus on enterprise application security. Alek has a B.S. degree in Computer Science and an M.S. degree in Software Engineering, both from the California State University, Sacramento.