Cutting Edge
Design Smarter Tracing for ASP.NET Pages
Dino Esposito
Code download available at:CuttingEdge0409.exe(125 KB)
Contents
Basics of the Trace Context
Capturing the Trace Output
Response Output Filters
Creating Expandable Trace Sections
Selecting Trace Sections
Conclusion
Tracing is important to the success of your ASP.NET applications. When tracing is enabled for an ASP.NET page, a large chunk of runtime information is appended to the page's output for your perusal. This information includes request details, the page's control tree, and the contents of commonly used collections like Session, Application, and Form displayed in HTML for you to consume. Figure 1 shows a typical ASP.NET page with tracing enabled. As you can see, the trace information is part of the page.
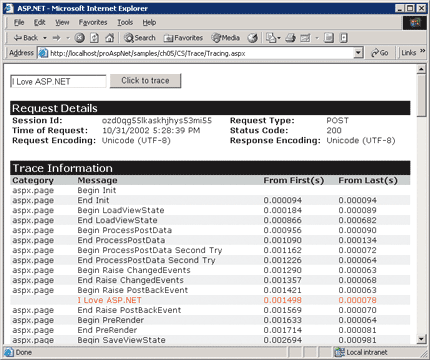
Figure 1** Page Trace Output **
Although you can write custom messages to the trace log, the ASP.NET trace context is hardly customizable. For example, there's no way for you to dictate which tables of information should be displayed, you have no control over fonts, you can't add entire new blocks of information, and so forth. Most of the time you are overwhelmed with so much information that you have to scroll up and down looking for the few lines you really care about.
Being able to control the contents of the trace output can enhance the effectiveness of the whole debug process; changing the layout of the trace output can make the page more readable. In this column, I'll lay the foundation of a smarter trace system for ASP.NET pages. My implementation goals are to dynamically expand and collapse each displayed block of information (Request Details, Control Tree, Session State) and hide unneeded blocks of information. These enhancements alone will let you control what is displayed and make the development cycle of your page more seamless.
Basics of the Trace Context
An ASP.NET page populates its trace log using methods on the TraceContext class. An instance of the TraceContext class is created when the HTTP request is set up for execution and is exposed through the Trace property of the HttpContext class. (The same TraceContext object is also mirrored through the Trace property of the Page class.)
The TraceContext class features a handful of properties and methods. The IsEnabled property indicates whether tracing is enabled for the page. The value that this property returns is affected by the value of the Trace attribute in the @Page directive, as well as the Enabled attribute in the <trace> section of the Web.config file. The Trace attribute enables tracing for the specific page, while the Enabled attribute in the <trace> section enables tracing for all pages in the application. Note that if tracing is enabled for the application, the page-specific Trace attribute can be used to override the application-wide setting, let-ting you enable tracing for all but a few pages. The TraceContext's TraceMode property gets and sets the order in which the traced rows are displayed in the page. The property is of type TraceMode—an enumeration that includes the values SortByCategory and SortByTime.
You can write your own messages to the log using either the Write or Warn method. Both have three overloads, which all behave in the same way. Write and Warn are nearly identical methods—the only noticeable difference is that the Warn method always outputs messages in red (see Figure 1).
The simplest overload just emits the specified text in the Message column, as shown here:
public void Write(string); public void Write(string, string); public void Write(string, string, Exception);
In the second overload, the first string argument represents the name of the category you want to use for the message. The second argument is the message itself. The category name can be used to sort the content of the Trace Information section; it can be any name that makes sense to the application to better qualify the message. Finally, the third overload adds an extra Exception object in case the message is tracing an error. Note that although the text being passed to both the Write and Warn methods is meant to be displayed in HTML pages, no HTML formatting tag is ever processed. The text is HTML-encoded so that if, for example, you attempt to use bold characters the result will be a trace message with "<b>" and "</b>" substrings.
It is interesting to note that the IsEnabled property in the TraceContext class is a read/write property. This means that you can also turn tracing on and off programmatically at any time:
public void Page_PreRender(object sender, EventArgs e) { // Enable tracing now Trace.IsEnabled = true; }
It goes without saying that the later you enable tracing, the more system-defined messages you lose. If you turn it on in the PreRender event, you won't see all the standard and custom message emitted during the page loading and the postback event handling.
ASP.NET also supports application-level tracing through the trace viewer tool—an HTTP handler exposed through trace.axd. Once tracing has been enabled for the application, each page request routes all the page-specific trace information to the viewer. You can view the trace viewer by requesting trace.axd from the root application directory. A typical output of the trace viewer tool is shown in Figure 2.
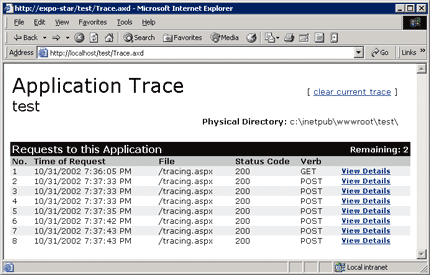
Figure 2** Trace.axd **
The ASP.NET trace viewer acts as a centralized console that gathers all the trace information generated by the pages in a given application. Each request, up to the maximum number fixed in the <trace> section of the Web.config file, is identified by a row in the viewer's interface and can be consulted until the viewer's cache is cleared (the new mostRecent flag in ASP.NET 2.0 allows this behavior to be modified, keeping the most recent request's data rather than the first request's data).
The output seen through the trace viewer and individual pages is generated by one component—the TraceHandler class—which is responsible for the layout of the trace output. The class is public and unsealed and can be inherited. The TraceHandler class also contains a couple of protected (but not virtual) methods that would be a good starting point for further investigation. All in all, though, TraceHandler is not documented and is not extensible.
To implement a smarter ASP.NET tracing mechanism, you'll need to do a bit more work. In this introduction I'll provide the background necessary for you to understand the next steps and ways you can enhance the tracing process.
Capturing the Trace Output
The additional output generated by the tracer is automatically appended to the page output when the HTTP handler in charge of the request has finished with the ASPX page. The HTTP handler for an ASPX resource is implemented in the Page class. The following pseudocode shows the sequence of steps taken by the ProcessRequest method of the Page class:
void ProcessRequest(HttpContext context) { SetIntrinsics(context); FrameworkInitialize(); ProcessRequestMain(); ProcessRequestEndTrace(); ProcessRequestCleanup(); }
The handler first binds all intrinsic objects to the HTTP context that will accompany the request from beginning to end. After that, it creates the framework for the page. The page framework is the tree of server controls declared in the ASPX source file. Each control is instantiated and initialized as specified in the ASPX markup. Next, within ProcessRequestMain the page begins its interaction with the user code through the events that form the page lifecycle—Init, Load, and so forth. When the ProcessRequestMain method returns, the response output stream contains the page markup. At this point, and before cleaning up all resources allocated to service the request, the trace output is flushed to the output stream.
The TraceContext class gathers all the system-provided information and the user-defined messages in a DataSet. Each trace section (for example, Request Details) corresponds to a table in the DataSet (in ASP.NET 1.x, this DataSet is internal to the System.Web assembly; however, ASP.NET 2.0 provides access to it through the OnTraceFinished Page event). Each time a call to the Warn or Write method is made, a new row is added to the trace information table. All of this information is formatted and rendered by the TraceHandler class when it's time to terminate the request. As you can see, the TraceContext class relies on the capabilities of the same class used by the trace viewer tool—TraceHandler.
As I mentioned earlier, touching the TraceHandler class is unsafe and difficult, if not impossible. So to enhance the layout of the page's tracer you must be able to capture and modify the trace output. One way to do this is to write an HTTP module to intercept the EndRequest or PreSendRequestContent application events. (For an application-specific implementation, you can also handle events in the global.asax file.)
The EndRequest event is the last event in the HTTP chain of execution when ASP.NET responds to a request. The PreSendRequestContent event arrives a little earlier, just before ASP.NET sends content to the client. In both events, you have access to the response output stream, but unfortunately there's not much you can do to modify the data in the stream. The response output stream is exposed through the OutputStream property. The stream object that stores the raw contents of the outgoing HTTP content body is an instance of an internal class named HttpResponseStream. For performance reasons, though, the output stream is a write-only stream in which, for example, the CanRead and CanSeek properties (common to all Stream objects) return false.
In the end, the HTTP module approach only works if you want to append some text to the outgoing stream (PreSendRequestContent) or add some text just before the request is terminated (EndRequest). To process the response, you need to take another route, one which is also much easier to code.
Response Output Filters
The response filter is a Stream-derived object that can be associated with the HttpResponse object to monitor and filter any output that's generated. You set a response filter through the Filter property of the HttpResponse class, as shown here:
void Page_Load(object sender, EventArgs e) { Response.Filter = new CustomTraceStream(Response.Filter); }
When the response is flushed, ASP.NET first writes headers; next, it checks for an installed output filter. If one is found, ASP.NET retrieves the currently buffered content of the output stream and passes it to the Write method of the filter stream. (Note that in doing so, ASP.NET doesn't read the buffered content from the write-only output stream; it reads from an internal byte array where the content is cached.)
The Write method of the filter stream receives the content as an array of bytes, modifies it at will, and overrides the response buffer for the browser. At this point, ASP.NET fires the PreSendRequestContent event and emits the browser's response. The overall scheme is shown in Figure 3.

Figure 3** HttpResponse.Flush **
Building a response filter is a matter of creating a new class that inherits from Stream and overriding some of the methods. The class is required to have a constructor that accepts a Stream object. For this reason, you can't just set Response.Filter to a new instance of, say, MemoryStream or FileStream. Both of these stream classes lack such a constructor, so an exception would be thrown. Overall, a response filter class is more of a wrapper stream class than a complete stream implementation. Figure 4 shows the code at the foundation of a typical response filter class. The stream parameter in the constructor is required to pass the new class a reference to the real response output stream. This is an essential piece of information if you have plans to modify the output being returned.
Figure 4 Response Filter Class
using System; using System.IO; using System.Text; namespace MsdnMag { namespace SmartTrace { public class CustomTraceStream : MemoryStream { // Private members private Stream m_outputStream; // Ctor public CustomTraceStream(Stream outputStream) { InitStream(outputStream); } private void InitStream(Stream outputStream) { m_outputStream = outputStream; } // Write method does it public override void Write(byte[] buffer, int offset, int count) { // Gets a string out of input bytes Encoding enc = HttpContext.Current.Response.ContentEncoding; string theText = enc.GetString(buffer, offset, count); // Manipulates the output of the page // (This includes everything: viewstate, // script, body, tracing) ••• // Renders the string back to an array of bytes byte[] data = enc.GetBytes(theText); // Persists changes back to the response stream m_outputStream.Write(data, 0, theText.Length); } } } }
When it comes to writing a response filter class, you can choose to inherit from MemoryStream or any other stream class that you think would be helpful. Choosing to build from a non-abstract base class is advantageous because it saves you from writing some boilerplate code. If you inherit from the base Stream class, you need to override a number of abstract members including CanRead, CanWrite, and Read.
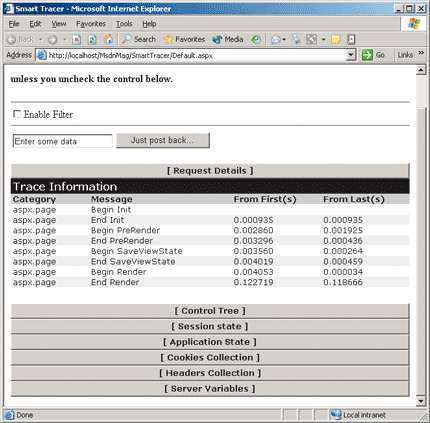
Figure 5** Expandable Sections **
So how can you use a response filter to enhance the trace output? The answer is simple: capture the default page output with a response filter, extract the trace output, and rewrite it to meet your expectations. The first step is to add some script code to the trace content to make it possible to click to expand or collapse each section (see Figure 5).
Creating Expandable Trace Sections
As you saw in Figure 4, the Write method of the response filter receives the HTTP content as an array of bytes. The byte array is converted to an ASCII string for easier manipulation:
string theText = HttpContext.Current. Response.ContentEncoding.GetString( buffer, offset, count);
The byte array carries everything that composes the page output including viewstate, script, comments, and so on. The trace content is just part of the output. The first step is separating the trace output from the rest of the page. By design, when page-level tracing is enabled, the trace output is located at the bottom of the page wrapped in a <div> tag with a particular ID:
<div id= "asptrace"> ••• <table> request details </table> <table> trace information </table> ••• </div>
Note that at this time the output of the page doesn't contain any text appended by HTTP modules that intercept the PreSendRequestContent or EndRequest events.
The trace output consists of some stylesheet definitions and a bunch of HTML tables. There is one table for each block of information. Predefined trace blocks are listed and described in Figure 6. The idea is to add a bit of JavaScript code to each table so that by simply clicking the table you can show/hide its contents. For example, the following code hides an HTML button element using the CSS display attribute:
button.style["display"] = 'none';
The problem is that none of the <table> tags has an ID. Giving each table a unique ID is therefore the first order of business.
Figure 6 Trace Sections
| Section Name | Description |
|---|---|
| Request Details | Information about the current request such as session ID and timestamp |
| Trace Information | System-defined and user-defined messages sorted by time or category |
| Control Tree | Renders the hierarchy of the controls in the page, each with the corresponding view state size |
| Session State | All of the items stored in Session |
| Application State | All of the items stored in the Application intrinsic object |
| Cookies Collection | Name and content of all cookies attached to the response |
| Headers Collection | Name and content of all headers attached to the response |
| Form Collection | Name and content of all input fields packed in the HTTP response |
| QueryString Collection | Name and content of all query string parameters |
| Server Variables | Name and content of all server variables available |
Let's create a worker class to manage all required changes to the trace output. I'll call the class TraceOutputManager and give it a couple of public methods—Parse and Flush. The Parse method extracts and analyzes all the trace output and saves bits and pieces of it in internal data structures. The TraceOutputManager class maintains distinct members for the page output (without the trace content), the portion of the trace content before the first section, and the portion of it that follows the last section. In addition, each section is saved into a custom class that contains a unique ID, the display name, and the markup of the corresponding <table> tag (see the code in Figure 7).
Figure 7 Section Information
public class TraceOutputSection { // Section type (from TraceSections enum) public TraceSections Code; // Display name (i.e., Request Details) public string Name; // Unique ID (i.e., RequestDetails) public string ID; // HTML output of the section public string Body; }
The algorithm to assign a unique ID is arbitrary. I decided to retrieve the title of the table (Request Details) and use it cleared of any blanks. The markup of the section, any markup contained between two successive <table> and </table> tags, is stored in the Body property and is modified by injecting any required extra attributes, such as ID and onclick. The following code shows how the sample code parses the trace output in the response filter:
public override void Write( byte[] buffer, int offset, int count) { string theText = HttpContext.Current.Response.Content.Encoding.GetString(buffer, offset, count); TraceOutputManager tracer; tracer = new TraceOutputManager(theText); tracer.Parse(); ••• }
To toggle the visibility of each table, add an onclick handler to each; thus, whenever the user clicks within the table, the display attribute is turned off and the table disappears. Great, but once it's hidden, how can you show it again? Because the table is now invisible, there's no page element to click. Here's one workaround.
Just associate each table with a client-side <button> element. This element is invisible at first, but shows up when the table is hidden. Likewise, when you click the button, the display attribute of the button and table are reversed—the button is hidden and the table is displayed:
function Toggle(showInfo, table, button) { if (showInfo) { table.style["display"] = ''; button.style["display"] = 'none'; } else { table.style["display"] = 'none'; button.style["display"] = ''; } }
Figure 8 shows the core code to unpack the trace output in individual section objects—instances of the TraceOutputSection class outlined earlier. Each section consists of the following markup:
<button ID="Name_Button" onclick="Toggle(true, Name, Name_Button)" /> <table ID="RequestDetails" onclick="Toggle(false, Name, Name_Button)"> ••• </table>
In the preceding code, Name is a placeholder for the actual section name. The Flush method on the helper TraceOutputManager class composes the modified text of the various sections into a string. Figure 9 shows the source code of the Flush method.
Figure 9 Flush Method
public string Flush(TraceSections options) { // Define the builder object StringBuilder traceBuilder = new StringBuilder(); // Append the whole page response (without original trace output) traceBuilder.Append(m_pageResponse); // Append the modified trace content BuildTraceOutput(traceBuilder, options); // Return the new page output return traceBuilder.ToString(); } void BuildTraceOutput(StringBuilder sb, TraceSections options) { // Append the Toggle Javascript function sb.Append(m_clientScript); // Append the trace CSS and opening tag sb.Append(m_tracePrefix); // Append the sections foreach(TraceOutputSection sec in m_traceSections) { if ((sec.Code & options) == sec.Code) sb.Append(sec.Body); } // Append the closing tags sb.Append(m_traceSuffix); }
Figure 8 Parse Output into Individual Objects
private void ExtractSections() { // Split on </table> to create info blocks per each section in the // output like "Request Details", "Trace Information", and so on Regex r = new Regex("</table>"); string[] sections = r.Split(m_body); foreach(string s in sections) { if (!s.Equals(String.Empty)) { // The title of the section follows the pattern: // <h3><b>Title</b></h3> string sectionName = DetermineSectionName(s); // Pack info into an ad hoc structure TraceOutputSection sec = new TraceOutputSection(); sec.Name = sectionName; sec.ID = sectionName.Replace(" ", ""); sec.Code = (TraceSections) Enum.Parse(typeof(TraceSections), sec.ID); // Prefix the <table> block with a <button> tag which will // provide a way to expand the block once collapsed string buttonBase = "<button id=\"{0}_Button\" style=\"{2}\" onclick=\"Toggle(true, {0}, {0}_Button)\">[ {1} ] </button>\r\n"; string buttonMarkup = String.Format(buttonBase, sec.ID, sec.Name, "display:none;width:100%;font-weight:700; font-family:verdana;"); // Create the builder used to construct the new HTML fragment StringBuilder sb = new StringBuilder(s); // Append the closing </table> sb.Append("</table>"); // Add ID and ONCLICK attributes string jsBase = "Toggle(false, {0}, {0}_Button)"; string attribs = String.Format(" ID=\"{0}\" onclick=\"{1}\" ", sec.ID, String.Format(jsBase, sec.ID)); sb.Insert("<table".Length, attribs); // Merge button and table StringBuilder sb1 = new StringBuilder(buttonMarkup); sb1.Append(sb.ToString()); // Finalize sec.Body = sb1.ToString(); m_traceSections.Add(sec); } } }
The following code snippet, excerpted from the response filter class, outlines the high-level steps of the whole process:
TraceOutputManager tracer; tracer = new TraceOutputManager(theText); tracer.Parse(); theText = tracer.Flush(m_options); byte[] data = HttpContext.Current.Response.ContentEncoding.GetBytes(theText); m_outputStream.Write(data, 0, theText.Length);
The text of the original page output is passed to the TraceOutputManager for parsing. The trace content is then separated from the standard page output and enhanced with new HTML elements and script code. Each block of information is treated individually. Then, all sections are combined into a single string when the modified trace output is flushed. The resulting string is then transformed into an array of bytes and written to the original response stream.
Finally, the ASP.NET runtime fires the PreSendRequestContent event and emits the response for the browser. You can now click anywhere in the text of each trace section and have it collapse to a page-wide button. To expand a section, just click on the corresponding button (see Figure 5).
The sections that will be displayed depend on the page's behavior. If the Session or Application state is empty, the corresponding sections are omitted. Likewise, you'll find FormCollection only if there are some input fields to carry out.
Selecting Trace Sections
In some of the listings discussed so far, I make use of the TraceSections enum type defined in Figure 10. The type lists all of the standard sections you can find in a trace output and its introduction helps to programmatically select which sections are to be output. As of ASP.NET 1.x, you can't control which information appears in the trace output. This makes the text that's appended larger—often unnecessarily so. If you just want to trace the flow of messages, why do you need the control tree or server variables in the output?
Figure 10 TraceSections Enum
[Flags] public enum TraceSections : int { All = 0xFFFF, RequestDetails = 0x01, TraceInformation = 0x02, ControlTree = 0x04, SessionState = 0x08, ApplicationState = 0x10, CookiesCollection = 0x20, HeadersCollection = 0x40, FormCollection = 0x80, QuerystringCollection = 0x100, ServerVariables = 0x200 }
For this reason, each section is given a code after parsing that corresponds to a value in the TraceSections enum. The Flush method checks the code of each parsed section against the list of displayable sections. The text for the section is appended to the final response only if a match is found:
if ((sec.Code & options) == sec.Code) sb.Append(sec.Body);
You specify the desired sections in the constructor of the response filter, as shown here:
CustomTraceStream stm; stm = new CustomTraceStream(Response.Filter, TraceSections.RequestDetails | TraceSections.TraceInformation); Response.Filter = stm;
This code configures the trace output manager to display only Request Details and Trace Information (see Figure 11).
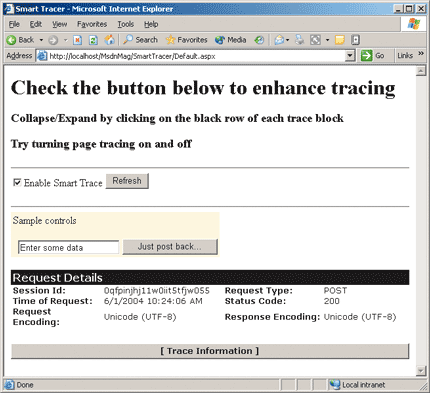
Figure 11** Smart Trace Info **
Conclusion
Tracing is a powerful ASP.NET feature designed to make Web development easier. Needless to say, tracing should not be enabled for deployed applications because of the extended output and the overhead it adds to the request. However, as long as tracing is disabled, you can leave Trace.Write and Trace.Warn statements in your production code because these statements are just ignored in this case.
This column focused on enhancing the layout of an ASP.NET trace for use mostly at development time. By writing a response filter, you gain read/write access to the page response before the markup is sent to the browser. Note that the response filter feature can be useful far beyond the examples discussed here. It's the only way you have to modify the text being displayed before this text is sent to the client. Other solutions based on HTTP modules only let you append text.
ASP.NET tracing is different from .NET tracing—a feature based on special components named listeners. Listeners are pluggable components that capture the output of apps and store it on various media. For more on tracing in .NET, see "Visual Basic .NET: Tracing, Logging, and Threading Made Easy with .NET".
To take advantage of built-in and custom listeners, you should trace through the classes in the System.Diagnostics namespace and, as far as ASP.NET applications are involved, avoid the Trace object. Built-in listeners allow you to write directly to the Windows® event log and a text file. In ASP.NET 2.0, System.Diagnostics tracing is integrated with ASP.NET tracing so that you can pipe traces from one into the other. Changes discussed in this column affect only the behavior of the ASP.NET Trace object.
Send your questions and comments for Dino to cutting@microsoft.com.
Dino Esposito is a Wintellect instructor and consultant based in Italy. Author of Programming ASP.NET and the newest Introducing ASP.NET 2.0 (both from Microsoft Press), he spends most of his time teaching classes on ASP.NET and ADO.NET and speaking at conferences. Get in touch with Dino at cutting@microsoft.com or join the blog at https://weblogs.asp.net/despos.