Test Run
Software Testing Paradoxes
James McCaffrey
Code download available at:TestRun0512.exe(120 KB)
Contents
Simpson's Paradox
Braess's Paradox
Parrondo's Paradox
Paradoxes are fun. In this month's column I show you three interesting cases that can occur when you are performing software testing. They're fundamentally mathematical in nature, and they can be a useful addition to your troubleshooting arsenal.
In the first part of this column, I explain Simpson's Paradox. This is the situation when Software System A is worse in every area of comparison than Software System B, yet System A can still be shown to be the better system. In the second part, I demonstrate Braess's Paradox, which is when adding a perfectly good load-balancing server actually reduces network performance in a most surprising way. I finish up with a look at Parrondo's Paradox, where two completely independent but faulty systems can, incredibly, produce a correct system.
Simpson's Paradox occurs quite frequently. Although the chances of you actually encountering Braess's or Parrondo's Paradoxes are slim, I think you'll find reading about them quite entertaining.
Simpson's Paradox
Imagine you have two different software system prototypes: Prototype A and Prototype B. You want to evaluate which prototype is better based on user feedback. Suppose that for ease-of-use, Prototype A received an excellent evaluation by 50 out of 200 people, while Prototype B received excellent from 15 out of 100 people (see Figure 1). From this data, Prototype A is clearly superior to Prototype B in terms of ease-of-use, with Prototype A getting 25 percent excellent and Prototype B getting just 15 percent.
Figure 1 Comparing Prototype A and Prototype B
| Ease of Use Data | Prototype A | Prototype B |
|---|---|---|
| Number excellent scores | 50 | 15 |
| Total users | 200 | 100 |
| Score | 25% | 15% |
| Security Data | Prototype A | Prototype B |
| Number excellent scores | 85 | 300 |
| Total users | 100 | 400 |
| Score | 85% | 75% |
Now, suppose that for security features, Prototype A receives a rating of excellent from 85 out of 100 people, while Prototype B receives excellent from 300 out of 400 people. From this data, you can see that Prototype A (with 85 percent excellent) is again clearly superior to Prototype B (with just 75 percent excellent). So, which prototype do you conclude is better? Before you answer, let's combine the data from Figure 1 into a single table as shown in Figure 2.
Figure 2 Combined Data for Security and Ease-Of-Use
| Combined Data | Prototype A | Prototype B |
|---|---|---|
| Number excellent scores | 135 | 315 |
| Total users | 300 | 500 |
| Score | 45% | 63% |
If you combine the number of excellent evaluations, you see that Prototype A receives 135 out of 300, which is just 45 percent excellent. Meanwhile, Prototype B dominates with 63 percent excellent, based on its 315 out of 500. So Prototype B is superior, right? Or is Prototype A superior? And if it is, how can you explain away the combined data?
This is an example of Simpson's Paradox and it is a real phenomenon. There is no trick involved. The correct answer is that Prototype A is the better system; you should not combine the data together into a single table, as I've done in Figure 2. A brief, informal description of Simpson's Paradox is: a situation in which two or more sets of data lead to one conclusion when evaluated individually, but lead to an opposite conclusion when the sets are combined. If you look back at the data in Figure 1, you'll notice that the total number of evaluations for each prototype is different in each column. This is a necessary condition for Simpson's Paradox.
The preceding example is a bit artificial, but it illustrates Simpson's Paradox quite clearly. The important point is that Simpson's Paradox does actually happen, even with real-world data, and it is an occurrence you should be on the alert for. The paradox can easily sneak by you, especially if you are only presented with summary data and don't get a chance to see the original, uncombined data. Here is an example where the numbers are made up, but the scenario is based on an actual incident. The actual example appeared in "Sex Bias in Graduate Admissions: Data from Berkeley" by P.J. Bickel, E.A. Hammel, and J.W. O'Connell (1975).
Consider the graduate school admission data for a university, shown in Figure 3. The data shows that 4000 of 9000 males (44.4 percent) who applied to the university were admitted for graduate study, but only 1500 of 4500 females (33.3 percent) were admitted. Is this a case of some sort of gender inequity? Not necessarily. The data in Figure 3 represents combined admissions for four departments in the university. Take a look at Figure 4, which represents the data for each individual department. With these figures, you find that women were admitted at a higher rate than men in every case! Clearly the uncombined data in Figure 4 presents a better picture of admissions than the combined data in Figure 3. Even though this data is significantly simplified from the real incident, you can see that Simpson's Paradox can be quite difficult to spot.
Figure 4 Uncombined Graduate School Admissions Data
| Men | Women | |||||
|---|---|---|---|---|---|---|
| A | 2000 | 2400 | 45% | 400 | 450 | 47% |
| B | 1200 | 1000 | 55% | 100 | 80 | 56% |
| C | 700 | 900 | 44% | 600 | 730 | 45% |
| D | 100 | 700 | 13% | 400 | 1740 | 19% |
| Total | 4000 | 5000 | 1500 | 3000 | ||
Figure 3 Combined Graduate School Admissions Data
| Admitted | Rejected | Acceptance Rate | |
|---|---|---|---|
| Men | 4000 | 5000 | 44.4% |
| Women | 1500 | 3000 | 33.3% |
Simpson's Paradox is not a true paradox in the mathematical sense. A mathematical paradox produces a logically inconsistent result, whereas examples of Simpson's Paradox are unexpected and surprising, but fully explainable. There is a lot of information available on the Web about Simpson's Paradox if you want to investigate further. The moral is that when you are looking at test result data, you should first question whether the data is aggregated from other sources. If it is, you need to look at the original uncombined data. Additionally, if you are generating a test result data report, be very careful about combining the data in an attempt to simplify your presentation. When people say that "statistics can be made to say whatever you want," this is exactly the sort of situation they're referring to.
Braess's Paradox
Now let's take a look at Braess's Paradox. My example uses a traditional scenario—automobile traffic—but I also describe how the paradox maps more broadly to software testing and other situations. The original work for Braess's Paradox is "Über ein Paradox der Verkerhsplannung," by Dietrich Braess (1968). My example, however, is based upon several examples I found that were, in turn, based on examples attributed to Mark Wainwright. I was unable personally to locate Wainwright's original work.
Braess's Paradox is quite complex so I present a simplified, discrete approximation rather than the full problem. Suppose there are four towns—Town A, Town B, Town C, and Town D—as shown in Figure 5. Each road connecting any two of the towns has an associated cost given by the equation shown next to the road in the figure. The cost is a function of the number of cars (n) on the road. You can imagine that the cost represents the time it takes to travel the road, or the amount of gasoline required, or some other factor that you'd like to minimize. Now suppose that each morning there are six cars that leave Town A, one at a time, and all are headed to Town D. Car 1 leaves and has a completely open road. The car has two routes to choose from: A-B-D or A-C-D. The cost of A-B-D is [4(1) + 1] + [1 + 16] = 22. Because of the symmetry in the map, the cost of route A-C-D is also 22. Let's assume that Car 1 selects route A-B-D and starts on its way.
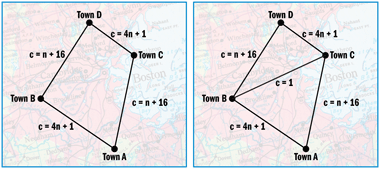
Figure 5** Road Network: Braess's Paradox **
Now Car 2 prepares to leave. He sees Car 1 on route A-B-D and knows that route A-B-D will now cost [4(2) + 1] + [2 + 16] = 27, so he selects route A-C-D with a cost of 22. Car 3 sees that there is one car on each route and selects route A-B-D with a cost of 27. Car 4 then selects route A-C-D, which has a cost of 27. Car 5 sees the four cars evenly distributed and he decides to take route A-B-D bringing its cost to [4(3) + 1] + [3 + 16] = 32. Finally, Car 6 selects route A-C-D, which also costs 32. All six cars are now en route from Town A to Town D. Because there are three cars on each path and the two paths are symmetric, the cost for each car will be 32.
Here's where Braess's Paradox comes into play. What do you suppose will be the effect of adding a new, efficient shortcut road between Town B and Town C? Common sense says that adding more road capacity should decrease the cost to our drivers. But since this phenomenon is called "Braess's Paradox" and not "Braess's Common Sense," you can guess that's not what happens.
Suppose that the map in Figure 5 is modified with a highly efficient shortcut between Town B and Town C, with a cost function equal to a constant 1. On the first morning with the new shortcut road in place, Car 1 prepares to leave Town A. He has four reasonable routes, each with an associated cost:
A-B-D cost = [4(1) + 1] + [1 + 16] = 22 A-C-D cost = [1 + 16] + [4(1) + 1] = 22 A-B-C-D cost = [4(1) + 1] + 1 + [4(1) + 1] = 11 A-C-B-D cost = [1 + 16] + 1 + [1 + 16] = 35
This looks promising. Car 1 selects route A-B-C-D and uses the new shortcut to reduce his travel cost significantly, at least for the moment. Car 2 prepares to leave. He sees Car 1 has selected route A-B-C-D and analyzes his potential costs:
A-B-D cost = [4(2) + 1] + [1 + 16] = 26 A-C-D cost = [1 + 16] + [4(2) + 1] = 26 A-B-C-D cost = [4(2) + 1] + 1 + [4(2) + 1] = 19 A-C-B-D cost = [1 + 16] + 1 + [1 + 16] = 35
After some quick math, Car 2 also elects route A-B-C-D. Even though Car 1 is on that route already, the efficiency of the shortcut still makes that route the best choice.
Now Car 3 prepares to leave and considers his options:
A-B-D cost = [4(3) + 1] + [1 + 16] = 30 A-C-D cost = [1 + 16] + [4(3) + 1] = 30 A-B-C-D cost = [4(3) + 1] + 1 + [4(3) + 1] = 27 A-C-B-D cost = [1 + 16] + 1 + [1 + 16] = 35
Again, the shortcut route A-B-C-D remains the best choice. Car 4 now prepares to leave Town A, observes the choices of the first three drivers and determines his costs:
A-B-D cost = [4(4) + 1] + [1 + 16] = 34 A-C-D cost = [1 + 16] + [4(4) + 1] = 34 A-B-C-D cost = [4(4) + 1] + 1 + [4(4) + 1] = 35 A-C-B-D cost = [1 + 16] + 1 + [1 + 16] = 35
The traffic on the shortcut now makes route A-B-C-D more costly than routes A-B-D and A-C-D. Let's assume Car 4 selects route A-B-D. (If Car 4 takes route A-C-D, the details are slightly different but the overall result is the same).
Car 5 now prepares to leave and analyzes the options:
A-B-D cost = [4(5) + 1] + [2 + 16] = 39 A-C-D cost = [1 + 16] + [4(4) + 1] = 34 A-B-C-D cost = [4(5) + 1] + 1 + [4(4) + 1] = 39 A-C-B-D cost = [1 + 16] + 1 + [2 + 16] = 36
So Car 5 decides to take route A-C-D. The last car, Car 6, now prepares to leave, observes the decisions made by the first five cars and comes up with this analysis:
A-B-D cost = [4(5) + 1] + [2 + 16] = 39 A-C-D cost = [2 + 16] + [4(5) + 1] = 39 A-B-C-D cost = [4(5) + 1] + 1 + [4(5) + 1] = 43 A-C-B-D cost = [2 + 16] + 1 + [2 + 16] = 37
Car 6 chooses route A-C-B-D because it has the lowest cost. With all six cars on the road, you can determine each car's cost:
Car 1 route A-B-C-D, cost = [4(4) + 1] + 1 + [4(4) + 1] = 35 Car 2 route A-B-C-D, cost = [4(4) + 1] + 1 + [4(4) + 1] = 35 Car 3 route A-B-C-D, cost = [4(4) + 1] + 1 + [4(4) + 1] = 35 Car 4 route A-B-D, cost = [4(4) + 1] + [1 + 16] = 34 Car 5 route A-C-D, cost = [2 + 16] + [4(4) + 1] = 35 Car 6 route A-C-B-D, cost = [2 + 16] + 1 + [1 + 16] = 36
Recall that without the shortcut road, the cost to each car was 32. By adding additional road capacity we have actually increased the cost to every driver!
This example provides a feel for the actual Braess's Paradox. Because of its obvious relation to data packets traveling on a network system, Braess's Paradox has been investigated heavily by researchers. You can informally summarize the paradox: it is sometimes possible to increase network congestion by increasing the number of routes between nodes. From a software testing point of view, Braess's Paradox can arise when running network performance tests. To be honest, the chances of you running into Braess's Paradox are very slim. But the phenomenon does exist and the moral is that you should not assume that adding capacity to a network will necessarily improve performance. If your add capacity and do not see the performance improvement you were expecting, Braess's Paradox is one of the things to investigate.
Parrondo's Paradox
Essentially, Parrondo's Paradox states that two losing gambling games, let's call them Game A and Game B, can be set up so that when they are played one after the other, they become winning games. There are many ways to construct examples of Parrondo's Paradox, the simplest is to use three biased coins.
Game A is a simple coin-flipping game. You flip a coin and if the coin comes up heads, you win $1. If the coin comes up tails, you lose $1. Coin 1 is slightly biased so that it comes up heads with probability of p1 = 0.495 (and therefore tails has a probability of 1-p1 = 0.505). If you play this game over and over, you will steadily lose money over time. Game B is slightly more complicated, with two coins. The first coin in this game, Coin 2, has a probability of winning (heads) p2 = 0.095. This is a very bad coin. Coin 3, the second coin, has a probability of winning p3 = 0.745. This is a good coin.
You start out with some fixed amount of money, say $300. To play Game B you have two steps. First, you check to see if the amount of money you have is a multiple of 3 ($300, $297, $303, or such). If your current capital is a multiple of three, you flip Coin 2 (the very bad coin) and either win $1 or lose $1. If your current capital is not evenly divisible by 3, you flip Coin 3 (the good coin) and win $1 or lose $1. Although it is not entirely obvious, if you play Game B over and over, you will certainly lose money over time.
At this point, you have two losing games. What do you suppose happens if we play Game A and then Game B either in a random pattern or a fixed pattern like ABB, ABB, ABB, and so on? Astonishingly, when played together, the losing games will actually win over time! The code accompanying this column gives a very lightweight simulation written in C#. Figure 6 shows a screen shot of the last part of a sample run of the program.
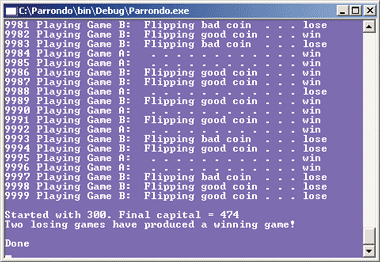
Figure 6** Parrondo's Paradox in Action **
The game was created by the Spanish physicist Juan M. R. Parrondo. In 1999, G. P. Harmer and D. Abbott published "Losing Strategies Can Win by Parrondo's Paradox, "naming the paradox after Parrondo. Since then, there has been quite a bit of research on this game and its variants, including the effects of changing the various probabilities of the three coins and changing the pattern which determines whether to play Game A or Game B.
Realistically, the chances of you encountering Parrondo's Paradox are remote. In one far-fetched scenario, you start with some fixed amount of process priority (corresponding to capital in Parrondo's Paradox), you have some subroutine that increases or decreases the process priority based on CPU usage (corresponding to Game A), and you have a second subroutine that increases or decreases process priority contingent upon the current priority (corresponding to Game B). The two subroutines are designed to probabilistically reduce process priority separately over time. However, when the two subroutines are called over and over, they actually increase process priority. Admittedly, this is a real stretch, but Parrondo's Paradox is just too interesting to be left out of this column!
Send your questions and comments for James testrun@microsoft.com.
James McCaffrey works for Volt Information Sciences, Inc., where he manages technical training for software engineers working at Microsoft. He has worked on several Microsoft products including Internet Explorer and MSN Search. James can be reached at jmccaffrey@volt.com or v-jammc@microsoft.com.