Memory Lane
Rediscover the Lost Art of Memory Optimization in Your Managed Code
Erik Brown
This article discusses:
|
This article uses the following technologies: .NET Framework, C# |
Code download available at:MemoryOptimization.exe(136 KB)
Contents
Type Sizing
Singletons
Pooling
Data Streaming
Performance Monitoring
CLR Profiler
Conclusion
Memory is the one resource all programs require, yet wise memory usage is becoming a lost art. Managed applications written for the Microsoft® .NET Framework rely on the garbage collector to allocate and clean up memory. For many applications, the three to five percent of CPU time spent performing garbage collection (GC) is a fair trade-off for not having to worry about memory management.
But for applications in which CPU time and memory are precious resources, minimizing the time spent garbage collecting can greatly improve application performance and robustness. If an application can more effectively use available memory, then it stands to reason that the garbage collector would run less often and for shorter periods of time. So rather than looking at what the garbage collector is or is not doing in your applications, take a look at memory usage directly.
Most production machines have a huge amount of RAM, and in the grand scheme of things, optimizations such as using short integers instead of regular ones may seem a little pointless. In this article I'll change your mind. I will look at type sizing, various design techniques, and how to analyze a program's memory utilization. My examples will focus on C#, but the discussion applies equally to Visual Basic® .NET, managed C++, and any other .NET-targeted languages you can think of.
I assume you understand the basics of how garbage collection works, including related concepts like generations, the disposal pattern, and weak references. If you are not familiar with these concepts, Jeffrey Richter has a good article on garbage collection at Garbage Collection: Automatic Memory Management in the Microsoft .NET Framework.
Type Sizing
Memory usage ultimately depends on the types defined and used by the assemblies in your program, so let's begin by examining the size of various types in the system.
Figure 1 shows the size in bytes of the core .NET value types defined in the System namespace, along with their equivalent C# types. I used unsafe code and the C# sizeof operator to verify the size of these value types in managed memory. Using the Marshal.SizeOf method instead of the sizeof operator will result in different values for some of these types, including bool and char, since Marshal.SizeOf computes the unmanaged size of a marshaled type, and these types are non-blittable (meaning that they may require conversion when passed between managed and unmanaged code). More on this in a moment.
Figure 1 .NET Value Types
| System Type | C# Type | Managed Size in Bytes | Default Unmanaged Size in Bytes |
|---|---|---|---|
| System.Boolean | bool | 1 | 4 |
| System.Byte | byte | 1 | 1 |
| System.Char | char | 2 | 1 |
| System.Decimal | decimal | 16 | 16 |
| System.Double | double | 8 | 8 |
| System.Single | float | 4 | 4 |
| System.Int16 | short | 2 | 2 |
| System.Int32 | int | 4 | 4 |
| System.Int64 | long | 8 | 8 |
| System.SByte | sbyte | 1 | 1 |
| System.UInt16 | ushort | 2 | 2 |
| System.UInt32 | uint | 4 | 4 |
| System.UInt64 | ulong | 8 | 8 |
The size of a structure (a value type) is computed as the sum of the sizes of its fields, plus any overhead added by aligning these fields to their natural boundaries. The size of a reference type is the size of its fields rounded up to the next 4-byte boundary, plus 8 bytes of overhead. (To get a sense for how much space is being used by your reference types, you can measure the change in heap size when allocating them, or you can use the CLR Profiler tool discussed later.) This means that all reference types occupy at least 12 bytes, so any object fewer than 16 bytes long might be more efficient as a structure in C#. Of course, a structure is problematic if you need to store a reference to the type, since frequent boxing can eat up both memory and CPU cycles. It's important, then, to use structures with care.
Since field alignment can influence the size of a type, field organization within a type plays a significant role in its ultimate size. The layout of a type and the organization of the fields with that layout are influenced by the StructLayoutAttribute applied to a type. By default, the C#, Visual Basic .NET, and C++ compilers all apply a StructLayoutAttribute to structures, specifying a Sequential layout. This means that the fields are laid out in the type according to their order in the source file. However, in the .NET Framework 1.x, a request for a Sequential layout is not respected by the just-in-time compiler (JIT), though it is by the marshaler. In the .NET Framework 2.0, the JIT does enforce a Sequential layout (if specified) for the managed layout of value types, though only if there are no reference type field members. Thus, the sizing of types is probably more important in the next version of the Framework. In all versions, a request for an Explicit layout (where you as the developer specify the field offsets for each and every field) is respected by both the JIT and by the marshaler.
I make this distinction because the marshaled layout of a type is typically not the same as the stack or GC heap layout of that type. A marshaled type's layout must match that of its unmanaged counterpart. The managed layout, however, is only used from managed code compiled by the JIT. So the JIT is able to optimize the managed layout based on the current platform without concern for external dependencies.
Consider the following C# structure (for simplicity, I have avoided specifying any access modifier for these members):
struct BadValueType { char c1; int i; char c2; }
As with the default packing in unmanaged C++, integers are laid out on four-byte boundaries, so while the first character uses two bytes (a char in managed code is a Unicode character, thus occupying two bytes), the integer moves up to the next 4-byte boundary, and the second character uses the subsequent 2 bytes. The resulting structure is 12 bytes when measured with Marshal.SizeOf (it's also 12 bytes when measured with sizeof on the .NET Framework 2.0 running on my 32-bit machine). If I reorganize this as follows, the alignment works in my favor, resulting in an 8-byte structure:
struct GoodValueType { int i; char c1; char c2; }
Another noteworthy point is that smaller types use less memory. That may seem obvious, but many projects use standard integers or decimal values even when they are unnecessary. In my GoodValueType example, assuming the integer values will never be greater than 32767 or less than -32768, I can cut the size of this type even further by using a short integer, as shown in the following:
struct GoodValueType2 { short i; char c1; char c2; }
Properly aligning and sizing this type reduced it from 12 to 6 bytes. (Marshal.SizeOf will report 4 bytes for GoodValueType2, but that's because the default marshaling for a char is as a 1 byte value.) You will be surprised how much the size of your structures and classes can be reduced if you pay attention.
As mentioned, it's very important to realize that the managed layouts of structures can greatly differ from unmanaged layouts, especially on the .NET Framework 1.x. The marshaled layout could be different from the internal layout, so it's possible (and, in fact, probable) that the types I've described will report different results when using the sizeof operator. As a case in point, all three structures I've shown so far have a managed size of 8 bytes on the .NET Framework 1.x. You can examine the layout of one of these types by the JIT using unsafe code and pointer arithmetic:
unsafe { BadValueType t = new BadValueType(); Console.WriteLine("Size of t: {0}", sizeof(BadValueType)); Console.WriteLine("Offset of i: {0}", (byte*)&t.i - (byte*)&t); Console.WriteLine("Offset of c1: {0}", (byte*)&t.c1 - (byte*)&t); Console.WriteLine("Offset of c2: {0}", (byte*)&t.c2 - (byte*)&t); }
On the .NET Framework 1.x, running this code results in the following output:
Size of BadValueType: 8 Offset of i: 0 Offset of c1: 4 Offset of c2: 6
Whereas on the .NET Framework 2.0, the same code will result in this output:
Size of BadValueType: 12 Offset of i: 4 Offset of c1: 0 Offset of c2: 8
While it may seem like a regression for the newer version of the Framework to increase the size of the type, it's actually expected behavior and a good thing that the JIT now respects the specified layout. If you'd prefer to let the JIT determine the best layout automatically (resulting in the same output as is currently generated by the 1.x JIT), you can explicitly mark your structure with a StructLayoutAttribute, specifying LayoutKind.Auto. Just keep in mind that for purely managed applications running on the .NET Framework 1.x that don't do any interop with unmanaged code, the savings you're trying to achieve by doing manual ordering of fields to get better alignment could be elusive.
Figure 2 illustrates some additional considerations. The Address class shown represents a United States address. This type is 36 bytes long: 4 bytes for each member, plus 8 for its reference type overhead (note that the sizeof operator in C# is only for value types, so again I'm relying on values as reported by Marshal.SizeOf). A large medical application that manages payments to doctors and hospitals might need to handle thousands of addresses simultaneously. In this case, minimizing the size of this class could be important. The ordering within the type is okay, but consider AddressType (see Figure 2).
Figure 2 AddressType
enum AddressType { Home, Secondary, Office } class Address { public bool IsPayTo; public AddressType AddressType; public string Address1; public string Address2; public string City; public string State; public string Zip; }
While enumerations are stored as integers by default, you can specify the integral base type to use. Figure 3 defines the AddressType enumeration as a short. By changing the IsPayTo field to byte as well, I have reduced the unmanaged size of each Address instance by more than 10 percent, from 36 to 32 bytes, and reduced the managed size by at least 2 bytes.
Figure 3 Reducing Type Size
enum AddressType : short { Home, Secondary, Office } class Address { byte _isPayTo; AddressType _addrType; string _address1; string _address2; string _city; string _state; string _zip; public bool IsPayTo { get { return (_isPayTo == 1); } set { _isPayTo = (byte)(value ? 1 : 0); } } public string State { get { return _state; } set { if (value == null) _state = null; else _state = String.Intern(value.ToUpper()); } } public AddressType AddressType { get { return _addrType; } set { _addrType = value; } } public string Address1 { get { return _address1; } set { _address1 = value; } } public string Address2 { get { return _address2; } set { _address2 = value; } } public string City { ... } public string Zip { ... } }
Finally, the string type is a reference type, so every string instance refers to an additional block of memory to hold the actual string data. In the Address type, if I ignore the various U.S. territories, then the state field has 50 possible values. It might be worth considering an enumeration here since it would remove the need for a reference type and store the value directly in the class. The base type for the enumeration could be a byte rather than the default int, resulting the field requiring 1 byte rather than 4. While this is a viable alternative, it does complicate data display and storage because the integer value would have to be converted into something a user or storage mechanism understands each time it is accessed or stored. This situation brings to light one of the more common trade-offs in computing: speed versus memory. It is often possible to optimize memory usage at the expense of some CPU cycles, and vice versa.
An alternate option here is to use interned strings. The CLR maintains a table called the intern pool that contains the literal strings in a program. This ensures that repeated use of the same constant strings in your code will utilize the same string reference. The System.String class provides an Intern method that ensures a string is in the intern pool and returns the reference to it. This is illustrated in Figure 3.
Before I conclude the discussion of the sizing of types, I also want to mention base classes. The size of a derived class is the size of the base class plus the additional members defined by a derived instance (and any extra space required for alignment, as discussed earlier). As a result, any base field that is not used in the derived type is a waste of good memory. A base class is great for defining common functionality, but you must make sure that each data element defined is truly necessary.
Next, I'll discuss some design and implementation techniques for efficient memory management. The memory an assembly requires depends largely on what the assembly does, but the memory actually used by an assembly is affected by how an application goes about its various tasks. This is an important distinction to keep in mind when designing and implementing an application. I'll examine the idea of a singleton, memory pooling, and data streaming.
Singletons
The working set of an application is the set of memory pages currently available in RAM. The initial working set is the memory pages the application consumes during startup. The more tasks performed and memory allocated during application startup, the longer before an application is ready and the larger the initial working set. This is especially important for desktop applications, where a user is often staring at the splash screen waiting for the application to be ready.
The singleton pattern can be used to delay the initialization of an object as long as possible. The following code shows one way to implement this pattern in C#. A static field holds the singleton instance, which is returned by the GetInstance method. The static constructor (implicitly generated by the C# compiler to execute all of the static field initializers) is guaranteed to execute before the first access to a member of the class and initializes the static instance, as shown in the following code:
public class Singleton { private static Singleton _instance = new Singleton(); public static Singleton GetInstance() { return _instance; } }
The singleton pattern ensures that only a single instance of a class is normally used by an application, but still allows alternate instances to be created as required. This saves memory because the application can use the one shared instance, rather than having different components allocate their own private instances. Use of the static constructor ensures that memory for the shared instance is not allocated until some portion of the application requires it. This might be important in large applications that support many different types of functionality, since the memory for the object is only allocated if the class is actually used.
This pattern and similar techniques are sometimes called lazy initialization, since the initialization is not performed until actually required. Lazy initialization is quite useful in a number of scenarios when the initialization can occur as part of the first request to an object. It should not be used where static methods would suffice. In other words, if you're creating a singleton to have access to a bunch of instance members of that singleton class, consider whether it would make more sense to expose the same functionality through static members, as that would not require you to instantiate the singleton.
Pooling
Once an application is up and running, memory utilization is affected by the number and size of objects the system requires. Object pooling reduces the number of allocations, and therefore the number of garbage collections, required by an application. Pooling is quite simple: an object is reused instead of allowing it to be reclaimed by the garbage collector. Objects are stored in some type of list or array called the pool, and handed out to the client on request. This is especially useful when an instance of an object is repeatedly used, or if the object has an expensive initialization aspect to its construction such that it's better to reuse an existing instance than to dispose of an existing one and to create a completely new one from scratch.
Let's consider a scenario in which object pooling would be useful. Suppose you are writing a system to archive patient information for a large insurance firm. Doctors collect information during the day and transmit it to a central location each evening. The code might contain a loop that does something like this:
while (IsRecordAvailable()) { PatientRecord record = GetNextRecord(); ... // process record }
In this loop, a new PatientRecord is returned each time the loop is executed. The most obvious implementation of the GetNextRecord method would create a new object each time it is called, requiring the object to be allocated, initialized, eventually garbage collected, and finalized if the object has a finalizer. When using an object pool, the allocation, initialization, collection, and finalization only occur once, reducing both the memory usage and the processing time that is required.
In some situations, the code could be rewritten to take advantage of a Clear method on the type with code like this:
PatientRecord record = new PatientRecord(); while (IsRecordAvailable()) { record.Clear(); FillNextRecord(record); ... // process record }
In this excerpt, a single PatientRecord object is created and a Clear method resets the contents so it can be reused within the loop. The FillNextRecord method uses an existing object, avoiding the repeated allocations. Of course, you still pay for a single allocation, initialization, and collection each time this code snippet is executed (though that's still better than paying for it every time through the loop). If the initialization is expensive, or the code is called simultaneously from multiple threads, the impact of this repeated creation may still be an issue.
The basic pattern for object pooling looks something like this:
while (IsRecordAvailable()) { PatientRecord record = Pool.GetObject(); record.Clear(); FillNextRecord(record); ... // process record Pool.ReleaseObject(record); }
A PatientRecord instance, or pool of instances, is created at the start of the application. This code retrieves an instance from the pool, avoiding the memory allocation, construction, and eventual garbage collection. This produces a great savings of time and memory, although it requires the programmer to explicitly manage objects in the pool.
The .NET Framework provides object pooling for COM+ assemblies as part of its Enterprise Services support. Access to this functionality is provided via the System.EnterpriseServices.ObjectPoolingAttribute class. COM+ provides pooling support automatically, so you don't have to remember to retrieve and return the objects explicitly. On the other hand, your assembly must operate within COM+.
For pooling any .NET object, I thought it would be interesting to write a general-purpose object pool for this article. My interface for this class is shown in Figure 4. The ObjectPool class provides pooling for any .NET type.
Figure 4 ObjectPool in .NET
public class ObjectPool { // ObjectPool is implemented as a Singleton public static ObjectPool GetInstance() { ... } // Delegates used by the interface public delegate object CreateObject(); public delegate void UseObject(object obj, object [] args); // Initiate pooling for the given type public void RegisterType(Type t, CreateObject createDelegate, short minPoolSize, short maxPoolSize, int creationTimeout) { ... } // Terminate pooling for the given type public void UnregisterType(Type t) { ... } // Get and release objects in the pool public object GetObject(Type t) { ... } public void ReleaseObject(object obj) { ... } // Execute the given method using an object from the pool public void ExecuteFromPool(Type t, UseObject executeDelegate, object [] args) { ... } }
Before a type can be pooled, it must first be registered. Registration identifies a creation delegate to call when a new instance of the object is required. This delegate simply returns the newly instantiated object and leaves the construction logic up to the client supplying the delegate. Like the Enterprise Services ObjectPooling attribute, it also accepts the minimum number of objects to keep active in the pool, the maximum number of objects to allow, and a timeout value for how long to wait for an available object. If the timeout is zero, then a caller will always wait until a free object is available. A nonzero timeout is useful in real-time or other situations where an alternate action may be required if an object is not readily available. After the registration call returns, the requested minimum number of objects is available in the pool. Pooling of a given type can be terminated with the UnregisterType method.
After registration, the GetObject and ReleaseObject methods retrieve and return objects from and to the pool. The ExecuteFromPool method accepts a delegate and arguments in addition to the desired type. The execute method invokes the given delegate with an object from the pool, and ensures that the retrieved object is returned to the pool after the delegate completes. This adds the overhead of a delegate invocation, but relieves you from having to manage the pool manually.
Internally, the class maintains a hash table of all pooled objects. It defines an ObjectData class to hold internal data related to each type. This class is not shown here, but maintains the registration information and records usage information for the type and maintains a queue of pooled objects.
The ReleaseObject method internally uses a private ReturnToPool method to restock the pool with the given object, shown in Figure 5. The Monitor class locks the operation. If fewer than the minimum number of objects is available, then the reference to the object is placed in the queue. If the minimum number of objects is already allocated, then a weak reference to the object is enqueued. If necessary, a waiting thread is signaled to pick up the newly enqueued object.
Figure 5 ReleaseObject Method
private void ReturnToPool(object obj, ObjectData data) { Monitor.Enter(data); try { data.inUse—; int size = data.inUse + data.inPool; if (size < data.minPoolSize) { // Return actual object to the pool data.pool.Enqueue(obj); data.inPool++; } else { // Min available, so enqueue weak reference WeakReference weakRef = new WeakReference(obj); data.pool.Enqueue(weakRef); } // Notify waiting threads if (data.inWait > 0) Monitor.Pulse(data); } finally { Monitor.Exit(data); } }
Using a weak reference here keeps objects that are above the minimum around as long as possible, but makes them available for GC as required. The inUse field of ObjectData tracks objects given to the app, while the inPool field tracks how many actual references are in the pool. The inPool field ignores any weak references.
One of the most important things to implement when authoring a pool is a suitable object lifetime policy. Weak references form the basis of one such policy, but there are others, and which policy to use is based on circumstance.
For the GetObject method, the internal RetrieveFromPool method is shown in Figure 6. The Monitor.TryEnter method is used to ensure the application does not wait too long for the lock. If the lock cannot be obtained in the timeout period, null is returned to the caller. If the lock is held, the DequeueFromPool method is called to retrieve an object from the pool. Notice how this method accounts for possible weak references in the queue with the do-while loop.
Figure 6 RetrieveFromPool Method
private object AllocateObject(ObjectData data) { return data.createDelegate(); } private object DequeueFromPool(ObjectData data) { object result; do { // This presumes pool is non-empty result = data.pool.Dequeue(); if (result is WeakReference) result = ((WeakReference)result).Target; else data.inPool—; } while (result == null && data.pool.Count > 0); return result; } private object RetrieveFromPool(ObjectData data) { object result = null; int waitTime = (data.creationTimeout > 0) ? data.creationTimeout : Timeout.Infinite; try { // Try to obtain lock int startTick = Environment.TickCount; if (Monitor.TryEnter(data, waitTime) == false) return null; if (data.pool.Count > 0) result = DequeueFromPool(data); if (result == null) { // Pool empty or all weak refs if (data.maxPoolSize == 0 || data.inUse < data.maxPoolSize) result = AllocateObject(data); else { if (waitTime != Timeout.Infinite) waitTime -= (Environment.TickCount - startTick); result = WaitForObject(data, waitTime); } } // Update inUse counter. if (result != null) data.inUse++; } finally { Monitor.Exit(data); } return result; }
Back in the RetrieveFromPool code, if an entry is not found in the queue, a new object is allocated via the AllocateObject method, as long as fewer than the maximum number of objects is available. Once the maximum is reached, the WaitForObject method waits for an object until the creation timeout is reached. Note how the time to wait is adjusted before calling WaitForObject to account for time spent acquiring the lock. The WaitForObject code is not shown here, but is available in the download for this article.
There were two options for what should happen when the retrieval timeout occurs: return null or throw an exception. A disadvantage of returning null is that it forces a caller to check for null each time an object is obtained from the pool. Throwing an exception avoids this check, but makes the timeout more expensive. If timeouts are not expected, then throwing an exception might be a better choice. I decided to return null, because when timeouts are not expected, this check could be skipped. When timeouts are expected, the cost of checking for null is lower than the cost of catching an exception.
Figure 7 shows the code for the ExecuteFromPool method, with the error checking and comments removed. This code uses the private methods to retrieve an object from the pool and call the provided delegate. The finally block ensures that the object is returned to the pool even if an exception occurs.
Figure 7 ExecuteFromPool Method
private ObjectData GetObjectData(Type t) { // The private ObjectData class holds stats for each type. ObjectData data = Table[t.FullName] as ObjectData; if (data == null) throw new ArgumentException(...); return data; } public void ExecuteFromPool(Type t, UseObject executeDelegate, object [] args) { ObjectData data = GetObjectData(t); object obj = null; try { // Retrieve an object from the pool obj = RetrieveFromPool(data); if (obj == null) throw new ObjectPoolException(...); // Execute given delegate with pooled object executeDelegate(obj, args); } finally { // Return retrieved object to pool if (obj != null) ReturnToPool(obj, data); } }
Object pooling helps level out the number of allocations made on the heap, since the most common objects in an application can be pooled. This can get rid of the sawtooth pattern often seen for the managed heap size in .NET-based applications, and reduces the time an application spends performing garbage collection. I will look at a sample program that uses the ObjectPool class later.
Note that the managed heap is very efficient at allocating new objects, and the garbage collector is very efficient at collecting lots of small and short-lived objects. If your objects are not used with high frequency or do not have a high creation or destruction cost, then object pooling might not be the right strategy. As with any performance decision, profiling an application is the best way to get a handle on the real bottlenecks in the code.
Data Streaming
When managing large chunks of data, sometimes an application simply needs a lot of memory. Object pooling only helps reduce the memory required for class allocations and the time required for object creation and destruction. It does not really address the fact that some programs must handle a lot of data to perform their work.
When a large amount of data is required on an ongoing basis, the most you can do is manage memory as best you can, or perhaps compress or otherwise keep it as compact as possible. (Again, the classic trade-off between memory and speed arises, as compression reduces memory consumption but that compression requires cycles.) When data is required temporarily, you might be able to reduce the amount of memory utilized using data streaming. Data streaming is achieved by working on part of the data at a time, rather than all or most of the data all at once. Compare the DataSet and DataReader classes in the System.Data namespace. While you can load the results of a query directly into a DataSet object, a large query result will consume a large amount of memory. A DataSet also requires that the memory is accessed twice: once to fill the tables, and then later to read the tables. The DataReader class can incrementally load the results of the same query and present a single row at a time to an application. This is ideal when the entire resultset is not actually required, since it more effectively uses the available memory.
The String class provides a number of opportunities to consume large amounts of memory unintentionally. The simplest example is the concatenation of strings. Concatenating four strings incrementally (adding one string at a time to the new string) will internally produce seven string objects, since each addition produces a new string. The StringBuilder class in the System.Text namespace joins strings together without allocating a new string instance each time; this efficiency greatly improves memory utilization. The C# compiler also helps in this regard because it transforms a series of string concatenations in the same code statement into a single call to String.Concat.
The String.Replace method provides another example. Consider a system that reads and processes a number of input files sent from an external source. These files might require preprocessing to put them into an appropriate format. For discussion purposes, suppose I had a system that had to replace each occurrence of the word "nation" with "country", and each occurrence of the word "liberty" with "freedom". This can be done quite easily with the following code snippet:
using(StreamReader sr = new StreamReader(inPath)) { string contents = sr.ReadToEnd(); string result = contents.Replace("nation", "country"); result = result.Replace("liberty", "freedom"); using(StreamWriter sw = new StreamWriter(outPath)) { sw.Write(result) } }
This works perfectly, at the expense of creating three strings that are the length of the file. The Gettysburg Address is roughly 2400 bytes of Unicode text. The U.S. Constitution is over 50,000 bytes of Unicode text. You see where this is going.
Now suppose each file was roughly 1MB of string data and I had to process up to 10 files concurrently. Reading and processing these 10 files will consume, in our simple example, around 10MB of string data. This is a rather large amount of memory for the garbage collector to allocate and clean up on an ongoing basis.
Streaming the file allows us to look at a small portion of the data at a time. Whenever I find an N or an L, I look for the words and replace them as required. Sample code is shown in Figure 8. I use the FileStream class in this code to illustrate operating on data at the byte level. You can modify this to use the StreamReader and StreamWriter classes instead if you want.
Figure 8 File Streaming
static void ProcessFile(FileStream fin, FileStream fout) { int next; while ((next = fin.ReadByte()) != -1) { byte b = (byte)next; if (b == 'n' || b == 'N') CheckForWordAndWrite(fin, fout, "nation", "country", b); else if (b == 'l' || b == 'L') CheckForWordAndWrite(fin, fout, "liberty", "freedom", b); else fout.WriteByte(b); } } static void CheckForWordAndWrite(Stream si, Stream so, string word, string replace, byte first) { int len = word.Length; long pos = si.Position; byte[] buf = new byte[len]; buf[0] = first; si.Read(buf, 1, word.Length-1); string data = Encoding.ASCII.GetString(buf); if (String.Compare(word, data, true) == 0) so.Write(Encoding.ASCII.GetBytes(replace), 0, replace.Length); else { si.Position = pos; // reset stream so.WriteByte(first); // write orig byte } }
In the code, the ProcessFile method receives the two streams and reads one byte at a time, looking for an N or L. When one is found, the CheckForWordAndWrite method examines the stream to see if subsequent characters match the desired word. If a match is found, the replacement is written to the output stream. Otherwise, the original character is placed in the output stream, and the input stream is reset to the original position.
This method relies on the FileStream class to buffer the input and output files appropriately, so that the code can work byte by byte to perform the necessary processing. By default, each FileStream uses a buffer of 8KB, so this implementation uses much less memory than the prior code that reads and processes the entire file. Even so, this process makes a function call to FileStream.ReadByte and one to FileStream.WriteByte for most characters in the input stream. You might be able to find a happier medium by reading a series of bytes into a buffer at a time, thus saving the method calls. Again, a profiler is your friend.
The streaming classes in .NET are constructed to allow multiple streams to work together on a common base stream. Many classes derived from Stream include a constructor that takes an existing Stream object, allowing a chain of Stream objects to operate on the incoming data and produce a succession of modifications or transformations to the stream. For an example, see the .NET Framework documentation for the CryptoStream class, which shows you how to encrypt a byte array from an incoming FileStream object.
Now that I have examined some design and implementation issues related to memory utilization, a brief discussion on testing and tuning an application is in order. Almost any application is bound to have various performance and memory issues. The best way to discover them is to measure these items explicitly and track down problems as they are revealed. Windows® performance counters and the .NET CLR Profiler or other profilers are two great ways to achieve that end.
Performance Monitoring
The Windows Performance Monitor does not solve performance problems, but it does help identify where you should look for them. There is an exhaustive list of performance counters related to memory utilization and other performance metrics available at Chapter 15 — Measuring .NET Application Performance.
Performance tuning is ideally an iterative task. Once a set of performance metrics are identified and a test environment is established where these metrics can be applied, the application is run within the test environment. Performance information is gathered using Performance Monitor. The results are analyzed to produce some suggested areas for improvement. The application or configuration is modified based on these suggestions, and the process begins again.
This process of testing, gathering, analyzing, and modifying a system applies equally well to all aspects of performance, including memory utilization. The modification of a system may include rewriting a portion of the code, changing the configuration or distribution of apps within the system, or other changes.
CLR Profiler
The CLR Profiler tool is great for memory utilization analysis. It profiles the behavior of an application as it is running and provides detailed reports on the types allocated, how long they are allocated, the details of each garbage collection, and additional memory-related information. You can download this free tool from Tools & Utilities .
The profiling tool is quite intrusive, so is not suitable for general performance analysis. For analyzing the managed heap, however, it is very impressive. To see a small sample of its capabilities, I wrote a small PoolingDemo program that uses the ObjectPool class I discussed earlier. Lest you think pooling is only for big or expensive objects, this demo defines a MyClass object as follows:
class MyClass { Random r = new Random(); public void DoWork() { int x = r.Next(0, 100); } }
The program allows you to choose between a non-pooling and a pooling test. The non-pooling code does the following:
public static void BasicNoPooling() { for (int i = 0; i < Iterations; i++) { MyClass c = new MyClass(); c.DoWork(); } }
On my desktop machine, one million iterations takes about 12 seconds to complete. The pooling code avoids the allocation of the MyClass object within the loop:
public static void BasicPooling() { // Register the MyClass type Pool.RegisterType(typeof(MyClass), ...); for (int i = 0; i < Iterations; i++) { MyClass c = (MyClass)Pool.GetObject(typeof(MyClass)); c.DoWork(); Pool.ReleaseObject(c); } Pool.UnregisterType(typeof(MyClass)); }
In this code, I use a static Pool property to invoke ObjectPool.GetInstance. At one million iterations, this pooling test takes roughly 1.2 seconds to complete, approximately 10 times faster than the non-pooling code. Of course, my example is contrived to emphasize the costs associated with obtaining and releasing references to instances of objects. The MyClass.DoWork is almost certainly inlined by the JIT compiler, and the per-iteration savings (10 seconds over one million iterations) is quite small. Still, this example illustrates how object pooling can eliminate a certain amount of overhead. In situations where such overhead is important or the time to create or finalize an object is expensive, object pooling may prove beneficial.
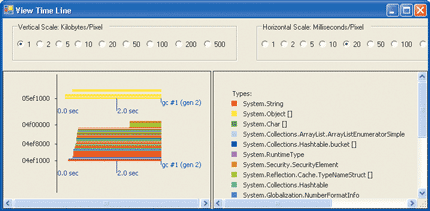
Figure 9** Time Line View With Object Pooling **
Reducing the iterations to 100,000 and running the CLR Profiler over this code produces some interesting results. Figure 9 shows the Time Line View when using object pooling and Figure 10 shows it when no pooling is used. This view shows a time line of the managed heap with different types represented by different colors, and includes the timing of each garbage collection. In Figure 9, pooling produces a fairly level heap, with a single garbage collection as the application exits. In Figure 10, without pooling, the heap must recover the data allocated by each Random class. The red represents integer arrays, which is the bulk of the data. The Time Line View without object pooling shows that 11 garbage collections were performed by the non-pooling test.
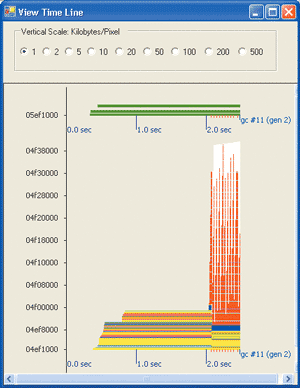
Figure 10** Time Line View Without Object Pooling **
CLR Profiler can also show allocation views by class type or over time, identify the number of bytes allocated by each method, and display the sequence of methods executed over the life of the test. The CLR Profiler download, available on the MSDN®Magazine Web site, contains some fairly extensive documentation, including a section with sample code showing common garbage collection problems and how they show up in the various CLR Profiler views.
Conclusion
I'm sure by now you're thinking differently about memory utilization in your code—where it is good and where it could be better. I've covered a range of issues here, from the sizing of types to tools that can help you discover memory issues in your code. I discussed the performance and memory benefits of pooling frequently used objects rather than relying on the .NET runtime to allocate and then garbage collect the objects, and I looked at streaming as a way to reduce the amount of memory required for processing large objects. The rest is up to you.
Erik Brown is a senior developer and architect at Unisys Corporation, a Microsoft Gold Certified Partner. He is author of the book Windows Forms Programming with C# (Manning Publications Company, 2002).