CLR Inside Out
Thread Management In The CLR
Erika Fuentes and Eric Eilebrecht
This column is based on prerelease versions of the CLR Threading System and the Task Parallel Libraries. All information is subject to change.
Contents
Common Issues in Concurrency
Lock Contention
Synchronization
Scheduling
Types and Sizes of Workloads
Memory Hierarchy Awareness
Dangerous Tuning
Noise
Concurrency Control
A Final Note on Extracting Parallelism
The ongoing technological evolution from single-core to manycore architectures is bringing great benefits. Consider, for instance, a threaded environment where the efficient use of multiple threads can promote better performance through the use of multiple cores and parallelism, for example, an ASP.NET application using multiple threads to make many independent queries to a database.
Using multiple cores does bring about new problems, however. You'll likely see an increase in the complexity of programming and synchronization models, you'll need to control concurrency, and performance tuning and optimization will be more difficult. Additionally, many of the new factors that affect the performance and behavior of concurrent applications are not well understood. Thus, tuning for performance has become challenging, especially when the targeted optimizations are not application-specific but rather general purpose.
Threading in the CLR is an example of a concurrent environment where many factors (such as those introduced by multiple-core architectures) can influence the behavior and performance of concurrency. Lock and cache contention and excessive context switching are just a few. Ongoing work on the CLR ThreadPool aims to make it easier for developers to exploit concurrency and parallelism for higher concurrency levels and better performance by integrating the Parallel Frameworks into the runtime and internally dealing with some of the most common problems.
In this column, we will describe some of the common issues developers encounter and the important factors to be considered when tuning multithreaded managed code, particularly in multiprocessor hardware. We also describe how future changes in the ThreadPool should deal with some of these issues and help alleviate the programmers' work. Furthermore, we will discuss some important aspects of concurrency control, which can help you to understand the behavior of apps in highly multithreaded environments. We will assume that you are familiar with the basic concepts of concurrency, synchronization, and threading in the CLR.
Common Issues in Concurrency
Most software was designed for single-threaded execution. In part, this is because the programming model of single-threaded execution reduces complexity and is easier to code. Existing single-threaded applications scale poorly for use with multiple cores. Even worse, it is not straightforward to adapt the single-threaded model to multiple cores. Many of the causes are predictable—synchronization issues such as lock and resource contention, race conditions, and starvation. Other causes are not yet well understood. For example, how do you determine the best concurrency level (number of threads) at any given time for a particular type (and size) of workload?
Consider the threading system in the CLR, which was designed to operate on a single-core machine: the tasks (WorkItems) are queued in a single list protected by one lock. Each thread then sequentially consumes the items from the queue. When this is migrated to a multicore architecture, its performance degrades when there's a lot of contention on the lock for higher concurrency levels. Interestingly, in his October 2008 Windows With C++ column, "Exploring High-Performance Algorithms", Kenny Kerr said that "a well-designed algorithm on a single processor can often outperform an inefficient implementation on multiple processors," implying that simply adding more processors does not always improve performance.
From here on, we'll loosely refer to the existing threading system as the ThreadPool and to the concept of WorkItem as an item in the tasks queue (a QueueUserWorkItem, for example). In single-core machines, managing concurrency could be handled with the careful scheduling of tasks by dividing the processor's time among the threads. Now that there's more than one core, you also must consider how to fairly distribute work among the cores, consider the underlying memory hierarchy for correctness and performance, and decide how to control and exploit higher concurrency levels.
Fairness vs. Performance
The discrepancy between task fairness and performance is critical in a concurrent environment: it's nearly impossible to get fair task scheduling and overall high performance at the same time. Consider, for example, a bunch of WorkItems in a queue waiting to be run. To be fair, each WorkItem can be run (consumed) in the order in which it arrived. But this doesn't deliver optimal performance.
From an operating system's point of view, a good way to achieve great performance gains is by keeping "hot" items (recently used) in the cache to avoid long trips to main memory; however, this approach conflicts with the previous idea of consuming items in order. The best way to maintain recent information in the cache would be to dequeue the last items in the queue first.
The ThreadPool environment has focused mainly on fairness, and the target of upcoming versions is extracting better performance. Strategies such as work-stealing algorithms are being incorporated with this purpose. In a work-stealing approach, there are several queues (such as one per processor), and "cold" items in a queue can be "stolen" and run, for instance, in a different processor. This can improve the performance while preserving some fairness, which can be advantageous for many concurrent applications.
Lock Contention
Concurrent environments can experience frequent lock contention for various reasons. For example, in the ThreadPool, locks are acquired every time there is a WorkItem added to the task queue and on every attempt to dequeue. Contention happens when there are many small WorkItems and the lock has to be taken frequently: when work arrives and is queued in large bursts (because the lock is taken often during these bursts) and when there is faulty concurrency control. The ThreadPool is designed to wake up all threads anytime work becomes available, so if there are many threads but no work in the queue, and then a single WorkItem arrives, all the threads might wake up simultaneously and try to acquire the lock.
This problem can become even more complicated since the threads spin while waiting for a lock, which leads to the belief that these are busy threads; during this time, if more WorkItems are enqueued, more new threads will be added, and they will also try to get the lock—so the cycle continues. Some ASP.NET applications exhibit this problem frequently.
A workaround for this last condition was to further throttle the number of threads we released at a time. Unfortunately, this sometimes led to too few threads being released, stalling the whole ThreadPool. Ongoing work on the ThreadPool to alleviate contention consisted of removing certain locks.
Synchronization
You must optimize your design for synchronization, and the use of synchronization primitives is not trivial. You'll have to choose your synchronization primitives and decide whether to use read or write locks (depending on the frequency of each of these operations). Also, sometimes the use of a primitive is more expensive on a multicore system than it is on a single-processor machine.
An example of this is a mutex on a single processor that is performing reasonably well and can facilitate workload distribution fairness but degrades when the application is moved to a manycore environment. In that case, the fairness enforced by the mutex begins to hurt performance because work has to wait where otherwise it wouldn't—in some cases, as in the use of monitors in the Microsoft .NET Framework, you may be better off spinning rather than waiting for the lock. (For more on performance and thread synchronization, see the Concurrent Affairs column "Performance-Conscious Thread Synchronization.")
Scheduling tasks in a multicore environment is a very large topic, and its full discussion is out of the scope of this column. However, there are some questions common to all implementations. For example, how will you choose your work consumption strategy? The answer will depend on the application. You may decide that those WorkItems queued last are those that embody most recent activity and, thus, consuming those before the ones in the head of the queue may result in better performance.
Types and Sizes of Workloads
Performance can vary depending on the type (or size) of an application's workload. You'll likely notice more scheduling and synchronization issues with CPU-bound workloads, while non CPU-bound ones are more likely to affect concurrency-level control. In addition, as mentioned before, it may be difficult to scale the app for use with multiple cores.
The following example illustrates this issue. Using the ThreadPool, a simple experimental application is run on a different number of cores (on the same machine but using different process affinity masks). Figure 1 shows some representative results. The workload is changed to explore whether the problem scales well using more cores.
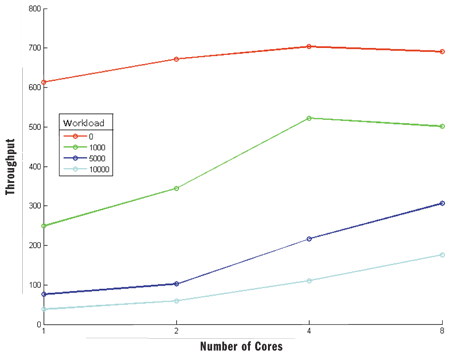
Figure 1 Throughput Results for Different Workloads on Increasing Number of Cores
An "experimental" workload of 0 performs better than bigger (and more realistic) workloads; in this sense, the app is not scaling properly to work better with bigger workloads on more cores. However, the lines at the bottom (light blue and dark blue) corresponding to the bigger workloads indicate that the throughput is actually increasing when more cores are added, while the throughput for the experimental empty workload shows a slight decrease. Additionally, larger workloads can experience more lock contention. As you can imagine, addressing all these pitfalls in a single, general-purpose optimization technique is difficult.
Memory Hierarchy Awareness
Taking into account that memory hierarchy is one of the most important issues for performance tuning—exploiting memory locality, especially for higher numbers of cores, is indispensable. In non-uniform memory access (NUMA) architectures, accessing memory locations in "distant" nodes is expensive and can hurt performance significantly. Understanding the underlying memory hierarchy is important for scheduling purposes. For example, a way of keeping memory accesses more localized in a multiprocessor environment would be to maintain threads working on a particular task in the same processor. The ThreadPool is not NUMA-aware; however, the addition of strategies such as work stealing inherently takes advantage of memory locality. Similar tasks tend to remain in the same node due to local queuing and dequeuing.
In general, remember that the efficient utilization of a cache can result in significant performance improvements. (For more information on memory hierarchy, see "Paradigm Shift: Design Considerations for Parallel Programming" at and "CLR Inside Out: Using Concurrency for Scalability."
Dangerous Tuning
To make things more challenging, there are cases where the introduction of some logic designed to provide some performance improvement can have the opposite effect. A typical example is when such an improvement is designed to deliver general-purpose optimizations; for some applications it just adds a lot of overhead, which in turn results in performance degradation.
Picture a case where various synchronization mechanisms are added to an app to function in multiple cores (to distribute work fairly, for instance), doing the synchronization adds complexity, which may result in unnecessary overhead for simple apps where an easier solution may have worked better. In highly concurrent applications, it is hard to identify significant tuning parameters. For example, maximizing the CPU usage does not necessarily result in throughput improvement; while in single-processor machines it does, in manycore machines it is sometimes better to not maximize the CPU usage and, instead, make threads "waste" some time.
Noise
Noise is yet another factor that makes performance tuning difficult. All the experiments presented in this discussion were run on dedicated machines (no other significantly expensive applications were running at the same time). But although there was not much noise, there were unexpected variations that were quite difficult to understand.
In real-life systems, it will often be the case that more than one application (and hence more threads) is competing for the resources. In the case of our ThreadPool, noise may even be introduced by different application domains executing at the same time.
Concurrency Control
The number of threads in an environment (concurrency level) is very important since it affects the behavior and performance of the environment and its applications. For instance, a low concurrency level with one thread per core is desirable for apps that are CPU-intensive (furthermore, the minimum number of threads in a system is usually set to be the same as the number of cores). On the other hand, high concurrency levels can result in excessive context switching or resource contention.
Figure 2 shows a typical example of how the concurrency level affects the performance of an app. (Note that the blue dots are observations captured at each concurrency level. The black line shows the fitted curve for these experiments to help us visualize the type of function that describes the behavior.) The way we measure performance in this context is with throughput, which is measured as number of completed WorkItems per second.

Figure 2 Throughput as a Function of Concurrency Level
This plot was generated using an experimental app that runs WorkItems for a certain time (each WorkItem has 100ms of execution time with 10ms of CPU usage and 90ms of waiting). The experiment was run several times on a dual-core 2GHz machine to collect the data and evaluate possible noise and variations. The theoretical maximum for the throughput on this machine is 200 completions per second at a concurrency level of 20. However, we can see that, experimentally, the throughput peaks at 150 a little bit before the concurrency level of 20 is reached, and then it degrades. The degradation is mainly due to context switching.
During this experiment, the CPU was maximized (however, after a certain point this does yield optimal throughput). A 100% CPU usage can mean that data is being pulled from memory for threads that aren't really being used; this gives the appearance that the app is being productive when in reality it's wasting CPU time. This also happens in single-processor environments, but it becomes more obvious in manycore.
As we've seen, defective concurrency control can increase the occurrence of certain problems, even more if parallelism is used. Additionally, concurrency management for multiple tasks has become even more challenging when multiple cores are present.
One example is related to the memory hierarchy issue. Trying to follow a simple rationale based on the example in Figure 2, increasing concurrency levels up to some point can be beneficial; however, in a multicore environment it is not trivial to determine where the threads are needed. For instance, if a processor is being overloaded for some reason (due to bad scheduling, for example) while the other processors are being under utilized, the overall throughput can be very low, but when new threads are added they could be assigned erroneously to the wrong processing unit.
Conversely, if the concurrency level is very high but the overall throughput is starting to degrade, we could decide to start removing threads, but the threads removed could be taken away from those processors that actually need them and whose throughput in particular could be improved by adding more threads.
Figure 3 shows how naively trying to change the concurrency levels can result in unexpected behavior. The experiment consists of a series of runs of a test application using different amounts of work to execute (WorkItems) and the execution time of each WorkItem (workload).
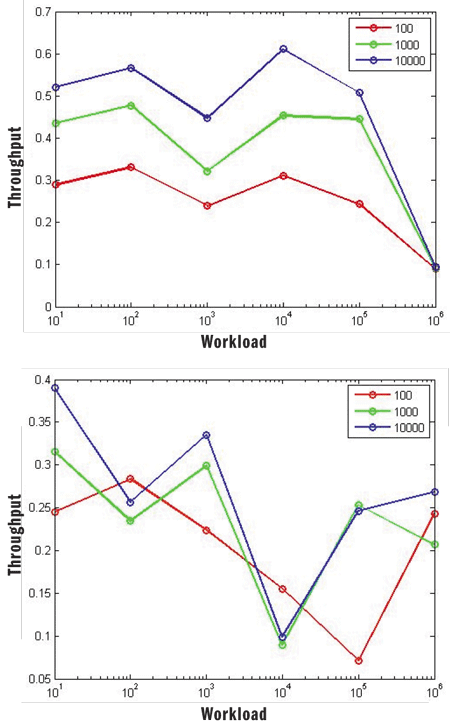
Figure 3 Changing Concurrency Levels Can Result in Unexpected Behavior
In the top section of Figure 3 are the results for this test running on the ThreadPool. The throughput is poor but shows some consistency along all of the trials. The bottom half of Figure 3 shows the results obtained by making some naive adjustments to the concurrency control logic to try to improve the way threads are added and removed. We can see that there are many variations in the throughput, and regardless of the amount of work, the adjustments result in what seems more like noise than better control.
Some points may appear to be improving for specific combinations of values, which suggests that different types of concurrency control adjustments are necessary depending on the type of app.
One possible approach to address this problem is to incorporate some sort of dynamic-tuning logic to adjust concurrency levels based on the application (for example, using statistical methods). Further inspection of concurrency control and tuning approaches is also out of the scope of our present discussion.
Appropriate tuning may lead to improvements in performance. The following is an encouraging example showing a similar experiment, where many factors and parameters in the ThreadPool were manually tuned specifically for this test application.
The performance results are in Figure 4. The improvement (represented by the red line) is mainly a result of adding more threads, which quickly increases the concurrency levels. In the ThreadPool (represented by the blue line), only one thread is added when increasing concurrency levels is deemed necessary—in this experiment the check happens every interval of 250ms. Moreover, after a certain point it concludes adding more threads because there won't be any further improvement.

Figure 4 Improvement Due to Manually Tuning the ThreadPool
In this experiment, WorkItems are queued, each of which does CPU work then blocks for some amount of time. Every 30 seconds the blocking time is changed: in the first 30 seconds it lasts 1ms, then 2ms, then it switches back to 1ms. At the 90 second mark, the work is stopped for 10 seconds. After this, the previous blocking cycle continues. The blue line shows performance results using the existing ThreadPool. The red line shows the improvements obtained with manual tuning of this ThreadPool.
A Final Note on Extracting Parallelism
The introduction of parallelism can improve performance but is not trivial to incorporate parallel concepts and algorithms into existing applications. (For example, there are many pitfalls, as outlined in "Concurrency Hazards: Solving 11 Likely Problems in Your Multithreaded Code.")
The Task Parallel Libraries (TPL) are extensions to the .NET Framework, developed by the Parallel Computing Platform team, that provide a way to expose concurrency and provide support to take advantage of parallelism. The TPL are currently available, together with more information about this development, on MSDN.
Of course, taking advantage of exposed parallelism is still not seamless for the average programmer since there are still many factors that need to be taken into consideration. And as we saw in Figure 1, applications don't always scale properly. The same is true when parallelizing a problem using divide-and-conquer techniques (recursive by nature). This can be tricky because these algorithms are a common source of deadlocks in the ThreadPool (which does not enable reentrant code). Finally, consider the usual case of a serial app that computes results in a certain order. When this application is parallelized, the results may be computed in a different order by the concurrent tasks. Then it is up to the programmer to sort out the results where necessary to ensure correctness and functionality.
Adjusting programs to perform in concurrent and parallel environments is not trivial. General-purpose tuning is even harder, and it cannot guarantee optimal behavior for all apps. Understanding the underlying structure of the concurrent environment can help you determine which parameters to tune for and the best programming strategies to employ. Ongoing work for future ThreadPool versions includes trying to reduce the need to do manual tuning.
Send your questions and comments to clrinout@microsoft.com.
Erika Fuentes, PhD, is a Program Manager on the CLR team where she works on the Core Operating System in concurrency. She has several academic publications in the area of statistics, adaptive systems, and scientific computing.
Eric Eilebrecht is a Senior Software Development Engineer in the CLR team, where he works on the Core Operating System. He has been at Microsoft for 11 years and had worked on back-end storage systems for Hotmail prior to joining the CLR team.