April 2009
Volume 24 Number 04
.NET Matters - Parallelizing Operations With Dependencies
By Stephen Toub | April 2009
.imgright1 { float: right; margin: 5px 0px 10px 10px; width:353px; font-weight: normal; font-size: 14px; color: #003399; font-family: "Segoe UI", Arial; }
QI have a system where multiple components need to be executed, but those components may have dependencies on each other. I'd like to be able to run these components in parallel where possible. How can I go about doing this?
AThis is a fairly common problem in the development of software, whether serial or parallel. In a sequential implementation, a common approach is to model the dependencies as a graph. Each component is represented by a node in the graph, and each dependency is represented by a directed edge between the two nodes sharing the dependency. This creates what's known as a Directed Acyclic Graph (DAG), assuming that there are no cycles (for example, component 1 depends on component 2, which depends on component 3, which depends back on component 1). A topological sort can then be used to create a partial ordering among these components so that, if you execute the components sequentially in that order, all of a component's dependencies will have completed by the time that component is run.
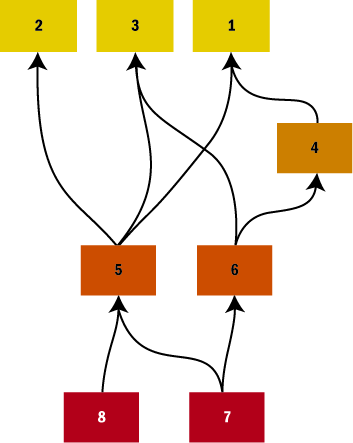
Figure 1 A Directed Acyclic Graph
Let's say you have 8 components, with the following dependencies (I'll refer back to this example throughout this column):
- Components 1, 2, and 3 depend on nothing else
- Component 4 depends on component 1
- Component 5 depends on components 1, 2, and 3
- Component 6 depends on components 3 and 4
- Component 7 depends on components 5 and 6
- Component 8 depends on component 5
A DAG for this set of dependencies is shown in Figure 1. In a sequential application, by running a topological sort over this graph, you might come up with one of several partial orderings, including just running them in ascending order (1,2,3,4,5,6,7,8), which happens to satisfy the dependencies outlined here. Other orderings are of course possible, such as 3,2,1,5,8,4,6,7.
The ability to execute in parallel some of the components in a graph like this one could yield valuable increases in speed. Imagine, just for the sake of illustration, that every component takes one second to execute, that each component is itself sequential in nature, that the application is running on a machine with an infinite number of processing cores, and that there is zero processing required for anything other than executing the components (no overhead). If you were to run all of the components sequentially, it would take eight seconds. But you can do better in parallel. You can run components 1, 2, and 3 concurrently, taking a total of one second. You can then run 4 and 5 concurrently, taking another second. When those are complete, you can run 6 and 8 concurrently, taking another second. And finally you can run 7, for a grand total of four seconds. Using parallelism, you've thus cut the example problem's running time in half.
As mentioned, this kind of problem pops up in a lot of different software problem domains. Consider, for example, MSBuild. Microsoft .NET Framework–based projects frequently reference other .NET projects in the same solution, thus setting up a dependency between those two projects. For the .NET Framework 3.5, MSBuild started offering the /m switch, which uses the available processors in the machine to parallelize the build process, utilizing dependency information like the project references just mentioned.
In the rest of this column, I'll build a small DependencyManagement class to help solve such problems. Here's an outline of the public API:
public class DependencyManager { public void AddOperation( int id, Action operation, params int [] dependencies); public event EventHandler<OperationCompletedEventArgs> OperationCompleted; public void Execute(); }
The main entry point into the type is the AddOperation method, which accepts a unique ID you provide to represent an operation, the delegate to be executed for that operation, and a set of dependencies upon whose completion this operation relies. If an operation has no dependencies, the parameter array will be empty.
The OperationCompleted event is raised any time one of the constituent operations completes, providing the ID of the operation as well as the starting and ending times of its execution.
And finally, the Execute method kicks off the process and waits for all of the operations to complete. While the DependencyManager class will be running operations in parallel, the API itself is not meant to be thread-safe, meaning that only one thread should be used to access AddOperation and Execute at a time.
This class allows me to express the previous example problem in the following fashion:
Action oneSecond = () => { ComputeForOneSecond(); }; DependencyManager dm = new DependencyManager(); dm.AddOperation(1, oneSecond); dm.AddOperation(2, oneSecond); dm.AddOperation(3, oneSecond); dm.AddOperation(4, oneSecond, 1); dm.AddOperation(5, oneSecond, 1, 2, 3); dm.AddOperation(6, oneSecond, 3, 4); dm.AddOperation(7, oneSecond, 5, 6); dm.AddOperation(8, oneSecond, 5); dm.Execute();
Internally, information about each registered operation is stored in an OperationData class:
private class OperationData { internal int Id; internal Action Operation; internal int [] Dependencies; internal ExecutionContext Context; internal int NumRemainingDependencies; internal DateTimeOffset Start, End; }
The Id, Operation, and Dependencies fields store the corresponding data passed into the AddOperation method as parameters, and the Context field stores the ExecutionContext captured at the time AddOperation was called (for more information on why this is important, see my last few .NET Matters columns). Additionally, OperationData stores the number of remaining dependencies that need to be completed before it can run. Finally, it keeps track of the start and end time for this operation, and these will be reported to a consumer of DependencyManager when the OperationCompleted event is raised for this particular operation.
Two collections are used to maintain the set of operations added to the DependencyManager instance:
private Dictionary<int, OperationData> _operations = new Dictionary<int, OperationData>();private Dictionary<int, List<int>> _dependenciesFromTo;
The former dictionary contains one entry for each added operation, and maps an operation's ID to its OperationData instance; this makes it fast and easy to look up the data for an operation given its ID. While that first dictionary does contain all of the information you need to do your work, it doesn't contain that information in a format that makes the work easy or efficient. The latter dictionary fixes this by providing a mapping from an operation's ID to all of the IDs of operations that directly depend on it. For instance, in the example problem shown earlier, the entry for ID 1 in this dictionary would map to a list containing IDs 4 and 5, since those two operations directly depend on ID 1 completing. This dictionary makes it quick and easy for a completing operation to send a completion notification to all of the other operations that depend on it.
The DependencyManager class contains three more private fields, in addition to the dictionaries:
private object _stateLock = new object(); private ManualResetEvent _doneEvent; private int _remainingCount;
The _stateLock field is used during the asynchronous execution of the registered operations in order to protect shared state accessed by the processing of these operations, namely the dictionaries and the data they contain. The ManualResetEvent is simply used as a mechanism for the Execute method to wait for all operations to complete. The last operation to complete will set the event, allowing the Execute method to exit. An operation knows that it's the last to complete because all of the operations decrement the _remainingCount field when they complete. As such, if an operation decrements the value and finds that it's now zero, the operation knows it's the last one and can set the _doneEvent. (As an aside, this kind of countdown logic is commonly found in fork/join parallelism problems, and the new CountdownEvent in the .NET Framework 4.0 makes such problems easier to implement.)
The code for the AddOperation method is simple.
public void AddOperation( int id, Action operation, params int[] dependencies) { if (operation == null) throw new ArgumentNullException("operation"); if (dependencies == null) throw new ArgumentNullException("dependencies"); var data = new OperationData { Context = ExecutionContext.Capture(), Id = id, Operation = operation, Dependencies = dependencies }; _operations.Add(id, data); }
After verifying that the arguments are valid, the method captures all of the data into an instance of the OperationData class, and that instance gets stored into the dictionary tracking all operations.
After all of the operations have been added, you can run the Execute method, shown in Figure 2, to get the process going. At the beginning of the method, it sets up dependency information for the run, namely transposing the dependency information stored in each OperationData such that you can easily look up operations that have dependencies on a target operation given that target's ID.
Figure 2 Starting the Process
public void Execute() { // TODO: verification will go here later // Fill dependency data structures _dependenciesFromTo = new Dictionary<int, List<int>>(); foreach (var op in _operations.Values) { op.NumRemainingDependencies = op.Dependencies.Length; foreach (var from in op.Dependencies) { List<int> toList; if (!_dependenciesFromTo.TryGetValue(from, out toList)) { toList = new List<int>(); _dependenciesFromTo.Add(from, toList); } toList.Add(op.Id); } } // Launch and wait _remainingCount = _operations.Count; using (_doneEvent = new ManualResetEvent(false)) { lock (_stateLock) { foreach (var op in _operations.Values) { if (op.NumRemainingDependencies == 0) QueueOperation(op); } } _doneEvent.WaitOne(); } } private void QueueOperation(OperationData data) { ThreadPool.UnsafeQueueUserWorkItem(state => ProcessOperation((OperationData)state), data); }
The rest of the method then works by finding all of the operations that have zero dependencies and queuing them up for execution to the .NET ThreadPool.
Previously, I noted that the Execute method and the AddOperation are not thread-safe with respect to each other, meaning that these methods are expected to be called sequentially, first using AddOperation to add all of the operations to execute, and then calling Execute. As a result, notice that AddOperation accesses the dictionaries without any locks or other mechanism for shared state synchronization. However, Execute does wrap part of its body in a lock. This is because once it's queued up the first work item to run, that work item may access and modify the dictionaries concurrently with the rest of the Execute body. To prevent such races from happening, the rest of the body of Execute is protected. When all relevant work has been queued, the Execute method blocks waiting for all of the work to complete.
QueueOperation simply queues the ProcessOperation method to the ThreadPool, and ProcessOperation runs the specified operation. This method is shown in Figure 3. The first portion of the method simply executes the delegate stored in the provided OperationData, doing so under the provided ExecutionContext (if one could be captured) and timing the run, storing the results back into the data structure for later reporting. (For more detailed timing information, System.Diagnostics.Stopwatch could be used instead of DateTimeOffset.)
Figure 3 Processing an Operation
private void ProcessOperation(OperationData data) { // Time and run the operation's delegate data.Start = DateTimeOffset.Now; if (data.Context != null) { ExecutionContext.Run(data.Context.CreateCopy(), op => ((OperationData)op).Operation(), data); } else data.Operation(); data.End = DateTimeOffset.Now; // Raise the operation completed event OnOperationCompleted(data); // Signal to all that depend on this operation of its // completion, and potentially launch newly available lock (_stateLock) { List<int> toList; if (_dependenciesFromTo.TryGetValue(data.Id, out toList)) { foreach (var targetId in toList) { OperationData targetData = _operations[targetId]; if (--targetData.NumRemainingDependencies == 0) QueueOperation(targetData); } } _dependenciesFromTo.Remove(data.Id); if (--_remainingCount == 0) _doneEvent.Set(); } } private void OnOperationCompleted(OperationData data) { var handler = OperationCompleted; if (handler != null) handler(this, new OperationCompletedEventArgs( data.Id, data.Start, data.End)); } public class OperationCompletedEventArgs : EventArgs { internal OperationCompletedEventArgs( int id, DateTimeOffset start, DateTimeOffset end) { Id = id; Start = start; End = end; } public int Id { get; private set; } public DateTimeOffset Start { get; private set; } public DateTimeOffset End { get; private set; } }
Once the operation has completed, you need to notify any dependent operations. Here's where the handy_dependenciesFromTo dictionary comes into play. You simply enumerate all of the operations that depend on this particular one, look up their OperationData instances, and decrement their NumRemainingDependencies by one. If their number of remaining dependences becomes zero, they're now eligible for execution, and QueueOperation is used to launch each eligible operation.
You can also do a little housecleaning: Now that the operation has completed, you won't need its entry in_dependenciesToFrom again, so you can remove it.
Finally, you notify the DependencyManager that one more operation has completed, potentially setting the_doneEvent (to wake up the Execute method) if it's the last operation.
No exception handling is shown in this implementation, but adding some could be important depending on how the class is used. As an example, if one of the OperationCompleted event handlers throws an exception, that exception will propagate out of OnOperationCompleted (which just raises the event), preventing any dependencies on this operation from being notified and likely hanging the system. To obtain a robust implementation, that would need to be addressed.
What you've seen until now represents the bulk of the implementation. However, there are still some interesting things that can be done. For example, the implementation assumes that all operations that are dependencies of other operations have been registered by the time Execute is called. If they're not, the relevant notifications of completion will never be raised and Execute will never return because some dependencies won't have been met and thus some operations won't ever run. To address this, you can implement a VerifyThatAllOperationsHaveBeenRegistered method that will catch such misuse and place a call to it at the beginning of the Execute method:
private void VerifyThatAllOperationsHaveBeenRegistered() { foreach (var op in _operations.Values) { foreach (var dependency in op.Dependencies) { if (!_operations.ContainsKey(dependency)) { throw new InvalidOperationException( "Missing operation: " + dependency); } } } }
Similarly, you can verify that there are in fact no cycles in the graph. If there were cycles, the Execute method would never complete because some dependencies would remain unsatisfied. For example, imagine that you erroneously input that component 2 depended on component 8. This would cause a cycle (2 => 5 => 8 => 2) that would prevent components 2, 5, 7, and 8 from executing. You can detect such cycles with a method VerifyThereAreNoCycles, again placing a call to this method at the beginning of Execute (after VerifyThatAllOperationsHaveBeenRegistered).
There are several appropriate algorithms for finding cycles in a graph. One is to do a depth-first search on the graph from every entry node in the graph (in the case of this article, that's an operation that has no dependencies, such as components 1, 2, and 3 in my example). As you do a depth-first search, you mark a node when you visit it. If you visit a node that's already been marked, you've found a cycle.
Another solution is based on the topological sort mentioned at the beginning of this column. If the topological sort fails, the graph has a cycle. Since having a topological sort is also useful in general (for example, if you wanted to optionally use DependencyManager to execute sequentially), I've chosen that approach.
Figure 4 shows the implementation of a CreateTopologicalSort method, which returns a partially ordered list of operation IDs. (The code also shows the VerifyThereAreNoCycles method, which simply calls CreateTopologicalSort and throws an exception if the method returned null, indicating that the sort failed.) The first thing to do is convert the operations dictionary into temporary dictionary data structures for the sort operation. These temporary dictionaries map in concept to the dictionaries you saw earlier. In fact, dependenciesToFrom maps an operation ID to the IDs of all of the operations it depends on (inbound edges). In contrast, dependenciesFromTo maps an operation ID to the IDs of all of the operations that depend on it (outbound edges). As the algorithm runs, you'll slowly pare down the contents of these dictionaries until, hopefully, there's nothing left.
Figure 4 Topological Sorting and Cycle Detection
private void VerifyThereAreNoCycles() { if (CreateTopologicalSort() == null) throw new InvalidOperationException("Cycle detected"); } private List<int> CreateTopologicalSort() { // Build up the dependencies graph var dependenciesToFrom = new Dictionary<int, List<int>>(); var dependenciesFromTo = new Dictionary<int, List<int>>(); foreach (var op in _operations.Values) { // Note that op.Id depends on each of op.Dependencies dependenciesToFrom.Add(op.Id, new List<int>(op.Dependencies)); // Note that each of op.Dependencies is relied on by op.Id foreach (var depId in op.Dependencies) { List<int> ids; if (!dependenciesFromTo.TryGetValue(depId, out ids)) { ids = new List<int>(); dependenciesFromTo.Add(depId, ids); } ids.Add(op.Id); } } // Create the sorted list var overallPartialOrderingIds = new List<int>(dependenciesToFrom.Count); var thisIterationIds = new List<int>(dependenciesToFrom.Count); while (dependenciesToFrom.Count > 0) { thisIterationIds.Clear(); foreach (var item in dependenciesToFrom) { // If an item has zero input operations, remove it. if (item.Value.Count == 0) { thisIterationIds.Add(item.Key); // Remove all outbound edges List<int> depIds; if (dependenciesFromTo.TryGetValue(item.Key, out depIds)) { foreach (var depId in depIds) { dependenciesToFrom[depId].Remove(item.Key); } } } } // If nothing was found to remove, there's no valid sort. if (thisIterationIds.Count == 0) return null; // Remove the found items from the dictionary and // add them to the overall ordering foreach (var id in thisIterationIds) dependenciesToFrom.Remove(id); overallPartialOrderingIds.AddRange(thisIterationIds); } return overallPartialOrderingIds; }
Once those dictionaries are filled, you start running the algorithm. The idea is that you cull from the graph all nodes that have zero inbound edges—in the context of this article, that means operations that have no dependencies on other operations. When you find such operations, you add them to the end of the sorted results (the order in which you add them to the end doesn't matter, hence the "partial ordering" nomenclature), and you remove them from the graph. You also need to remove all outbound edges from these operations, which you can easily find using the dependenciesFromTo dictionary. You do this process over and over until the graph contains zero nodes, at which point the algorithm is complete and you return the ordering you built up. If, however, you get to a point where all of the nodes in the graph have inbound edges, the graph contained a cycle, and there's nothing more you can do.
With that, the implementation is complete. Toward the beginning of this column, I showed the code that could be used with the DependencyManager class to run the sample problem I've been referring to throughout. If you'll remember, I suggested you could get the running time down to four seconds. Indeed, when I run that sample code on my laptop, I get timings that hover within a few milliseconds of four seconds.
This is partially luck, however. The hypothetical environment I postulated included a machine with an infinite number of cores. My laptop, unfortunately, is not configured as such, and is instead limited to just two cores. However, given the right ordering, the problem can still execute in four seconds with just two processing units. If operations 1 and 2 start running, then a second later 3 and 4 can start running, then a second later 5 and 6 can start running, and a second later 7 and 8 can start running.
But what happens if operations 2 and 3 happen to run first instead of operations 1 and 2? This is certainly possible, given that all of operations 1, 2, and 3 have no dependencies. If operations 2 and 3 run first, then in the next iteration operations 1 and 5 will be available to run. After they go, operations 4 and 8 will be able to go. But on the next iteration, only operation 6 will be available, since operation 7 depends on the completion of operation 6, and thus the entire computation will take approximately five seconds rather than four.
In my sample application, when I changed the order in which I called AddOperation to first register operations 3 and 2, the output time confirmed this issue, with a running time of just over five seconds. If as a developer you have a priori knowledge about how long each operation will take, you can use that to construct a better ordering for how operations are launched. That's left as an exercise for you.
There are of course many other interesting things you could build off of this implementation, using it as a starting point. For operations with no dependencies, you may want those to be able to start running as soon as they're added to the DependencyManager, rather than having to wait until Execute is called. You might want to be able to execute the DependencyManager asynchronously and later wait on its results, or alternatively do something else when it completes. You may want to be able to build up graphs of DependencyManagers. You may want operations to be able to return data that is passed along to dependencies, hence building up large dataflow networks. And so on. There are many interesting and useful possibilities. Enjoy!
Send your questions and comments for .NET Matters to netqa@microsoft.com.
Stephen Toub is a Senior Program Manager Lead on the Parallel Computing Platform team at Microsoft. He is also a Contributing Editor for MSDN Magazine.