Replace a hardware component on an Azure Stack Hub scale unit node
This article describes the general process to replace hardware components that are non hot-swappable. Actual replacement steps vary based on your original equipment manufacturer (OEM) hardware vendor. See your vendor's field replaceable unit (FRU) documentation for detailed steps that are specific to your Azure Stack Hub integrated system.
Caution
Firmware leveling is critical for the success of the operation described in this article. Missing this step can lead to system instability, performance decrease, security threats, or prevent Azure Stack Hub automation from deploying the operating system. Always consult your hardware partner's documentation when replacing hardware to ensure the applied firmware matches the OEM Version displayed in the Azure Stack Hub administrator portal.
Warning
Azure Stack Hub requires that the configuration of all servers in the solution have the same configuration, including for example CPU (model, cores), memory quantity, NIC and link speeds, and storage devices. Azure Stack Hub does not support a change in CPU models during hardware replacement or when adding a scale unit node. A change in CPU, such as an upgrade, will require uniform CPUs in each scale unit node and a redeployment of Azure Stack Hub.
Non hot-swappable components include the following items:
- CPU (must be of the same type (model, cores)*
- Memory*
- Motherboard/baseboard management controller (BMC)/video card
- Disk controller/host bus adapter (HBA)/backplane
- Network adapter (NIC)
- Graphics processing unit (GPU)
- Operating system disk*
- Data drives (drives that don't support hot swap, for example PCI-e add-in cards)*
*These components may support hot swap, but can vary based on vendor implementation. See your OEM vendor's FRU documentation for detailed steps.
The following flow diagram shows the general FRU process to replace a non hot-swappable hardware component.
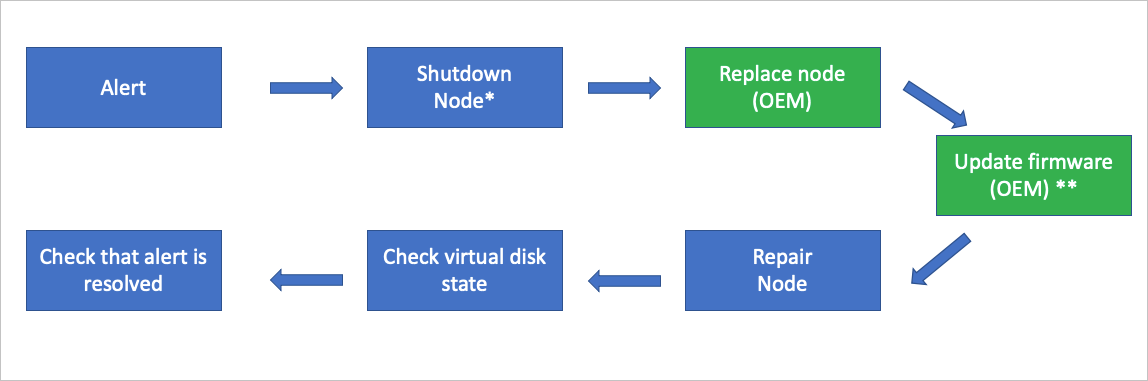
- This action may not be required based on the physical condition of the hardware.
** Whether your OEM hardware vendor does the component replacement and updates the firmware could vary based on your support contract.
Review alert information
The Azure Stack Hub health and monitoring system tracks the health of network adapters and data drives controlled by Storage Spaces Direct. It doesn't track other hardware components. For all other hardware components, alerts are raised in the vendor-specific hardware monitoring solution that runs on the hardware lifecycle host.
Component replacement process
The following steps provide a high-level overview of the component replacement process. Don't follow these steps without referring to your OEM-provided FRU documentation.
Use the Shutdown action to gracefully shut down the scale unit node. This action may not be required based on the physical condition of the hardware.
In an unlikely case the shutdown action does fail, use the Drain action to put the scale unit node into maintenance mode. This action may not be required based on the physical condition of the hardware.
Note
In any case, only one node can be disabled and powered off at the same time without breaking the S2D (Storage Spaces Direct).
After the scale unit node is in maintenance mode, use the Power off action. This action may not be required based on the physical condition of the hardware.
Note
In the unlikely case that the power off action doesn't work, use the baseboard management controller (BMC) web interface instead.
Replace the damaged hardware component. Whether your OEM hardware vendor does the component replacement could vary based on your support contract.
Update the firmware. Follow your vendor-specific firmware update process using the hardware lifecycle host to make sure the replaced hardware component has the approved firmware level applied. Whether your OEM hardware vendor does this step could vary based on your support contract.
Use the Repair action to bring the scale unit node back into the scale unit.
Use the privileged endpoint to check the status of virtual disk repair. With new data drives, a full storage repair job can take multiple hours depending on system load and consumed space.
After the repair action has finished, validate that all active alerts have been automatically closed.
Next steps
- For information about replacing a hot-swappable physical disk, see Replace a disk.
- For information about replacing a physical node, see Replace a scale unit node.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for