Application Gateway health probes overview
Azure Application Gateway monitors the health of all the servers in its backend pool and automatically stops sending traffic to any server it considers unhealthy. The probes continue to monitor such an unhealthy server, and the gateway starts routing the traffic to it once again as soon as the probes detect it as healthy.
The default probe uses the port number from the associated Backend Setting and other preset configurations. You can use Custom Probes to configure them your way.
Probes behavior
Source IP address
The source IP address of the probes depends on the backend server type:
- If the server in the backend pool is a public endpoint, the source address will be your application gateway's frontend public IP address.
- If the server in the backend pool is a private endpoint, the source IP address will be from your application gateway subnet's address space.
Probe operations
A gateway starts firing probes immediately after you configure a Rule by associating it with a Backend Setting and Backend Pool (and the Listener, of course). The illustration shows that the gateway independently probes all the backend pool servers. The incoming requests that start arriving are sent only to the healthy servers. A backend server is marked as unhealthy by default until a successful probe response is received.
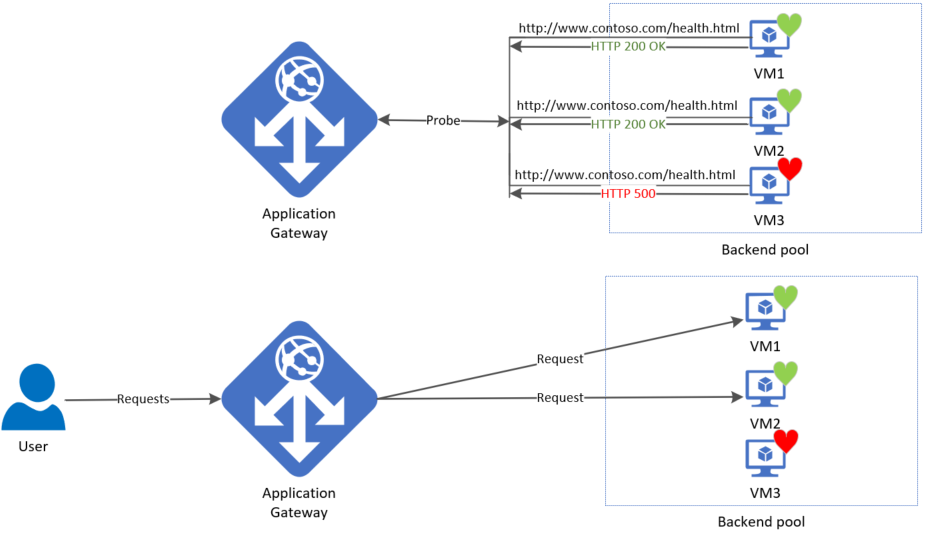
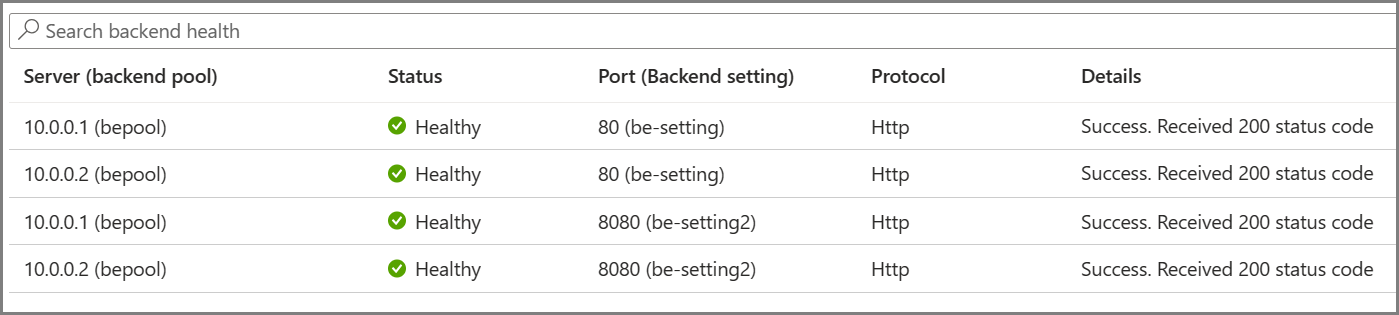
The required probes are determined based on the unique combination of the Backend Server and Backend Setting. For example, consider a gateway with a single backend pool with two servers and two backend settings, each having different port numbers. When these distinct backend settings are associated with the same backend pool using their respective rules, the gateway creates probes for each server and the combination of the backend setting. You can view this on the Backend health page.
Moreover, all instances of the application gateway probe the backend servers independently of each other.
Probe intervals
The same probe configuration applies to each instance of your Application Gateway. For example, if an application gateway has two instances and the probe interval is set to 20 seconds, both instances will send the health probe every 20 seconds.
Once the probe detects a failed response, the counter for "Unhealthy threshold" sets off and marks the server as unhealthy if the consecutive failed count matches the configured threshold. Accordingly, if you set this Unhealthy Threshold as 2, the subsequent probe will first detect this failure. The application gateway will then mark the server as unhealthy after 2 consecutive failed probes [First detection 20 secs + (2 consecutive failed probes * 20 secs)].
Note
The Backend health report is updated based on the respective probe's refresh interval and doesn't depend on the user's request.
Default health probe
An application gateway automatically configures a default health probe when you don't set up any custom probe configuration. The monitoring behavior works by making an HTTP GET request to the IP addresses or FQDN configured in the backend pool. For default probes if the backend http settings are configured for HTTPS, the probe uses HTTPS to test health of the backend servers.
For example: You configure your application gateway to use backend servers A, B, and C to receive HTTP network traffic on port 80. The default health monitoring tests the three servers every 30 seconds for a healthy HTTP response with a 30-second-timeout for each request. A healthy HTTP response has a status code between 200 and 399. In this case, the HTTP GET request for the health probe looks like http://127.0.0.1/. Also see HTTP response codes in Application Gateway.
If the default probe check fails for server A, the application gateway stops forwarding requests to this server. The default probe still continues to check for server A every 30 seconds. When server A responds successfully to one request from a default health probe, application gateway starts forwarding the requests to the server again.
Default health probe settings
| Probe property | Value | Description |
|---|---|---|
| Probe URL | <protocol>://127.0.0.1:<port>/ | The protocol and port are inherited from the backend HTTP settings to which the probe is associated |
| Interval | 30 | The amount of time in seconds to wait before the next health probe is sent. |
| Time-out | 30 | The amount of time in seconds the application gateway waits for a probe response before marking the probe as unhealthy. If a probe returns as healthy, the corresponding backend is immediately marked as healthy. |
| Unhealthy threshold | 3 | Governs how many probes to send in case there's a failure of the regular health probe. In v1 SKU, these additional health probes are sent in quick succession to determine the health of the backend quickly and don't wait for the probe interval. For v2 SKU, the health probes wait the interval. The backend server is marked down after the consecutive probe failure count reaches the unhealthy threshold. |
The default probe looks only at <protocol>://127.0.0.1:<port> to determine health status. If you need to configure the health probe to go to a custom URL or modify any other settings, you must use custom probes. For more information about HTTPS probes, see Overview of TLS termination and end to end TLS with Application Gateway.
Custom health probe
Custom probes allow you to have more granular control over the health monitoring. When using custom probes, you can configure a custom hostname, URL path, probe interval, and how many failed responses to accept before marking the backend pool instance as unhealthy, etc.
Custom health probe settings
The following table provides definitions for the properties of a custom health probe.
| Probe property | Description |
|---|---|
| Name | Name of the probe. This name is used to identify and refer to the probe in backend HTTP settings. |
| Protocol | Protocol used to send the probe. This has to match with the protocol defined in the backend HTTP settings it's associated to |
| Host | Host name to send the probe with. In v1 SKU, this value is used only for the host header of the probe request. In v2 SKU, it is used both as host header and SNI |
| Path | Relative path of the probe. A valid path starts with '/' |
| Port | If defined, this is used as the destination port. Otherwise, it uses the same port as the HTTP settings that it's associated to. This property is only available in the v2 SKU |
| Interval | Probe interval in seconds. This value is the time interval between two consecutive probes |
| Time-out | Probe time-out in seconds. If a valid response isn't received within this time-out period, the probe is marked as failed |
| Unhealthy threshold | Probe retry count. The backend server is marked down after the consecutive probe failure count reaches the unhealthy threshold |
Probe matching
By default, an HTTP(S) response with status code between 200 and 399 is considered healthy. Custom health probes additionally support two matching criteria. Matching criteria can be used to optionally modify the default interpretation of what makes a healthy response.
The following are matching criteria:
- HTTP response status code match - Probe matching criterion for accepting user specified http response code or response code ranges. Individual comma-separated response status codes or a range of status code is supported.
- HTTP response body match - Probe matching criterion that looks at HTTP response body and matches with a user specified string. The match only looks for presence of user specified string in response body and isn't a full regular expression match. The specified match must be 4090 characters or less.
Match criteria can be specified using the New-AzApplicationGatewayProbeHealthResponseMatch cmdlet.
For example:
$match = New-AzApplicationGatewayProbeHealthResponseMatch -StatusCode 200-399
$match = New-AzApplicationGatewayProbeHealthResponseMatch -Body "Healthy"
Match criteria can be attached to probe configuration using a -Match operator in PowerShell.
Some use cases for Custom probes
- If a backend server allows access to only authenticated users, the application gateway probes will receive a 403 response code instead of 200. As the clients (users) are bound to authenticate themselves for the live traffic, you can configure the probe traffic to accept 403 as an expected response.
- When a backend server has a wildcard certificate (*.contoso.com) installed to serve different sub-domains, you can use a Custom probe with a specific hostname (required for SNI) that is accepted to establish a successful TLS probe and report that server as healthy. With "override hostname" in the Backend Setting set to NO, the different incoming hostnames (subdomains) will be passed as is to the backend.
NSG considerations
Fine grain control over the Application Gateway subnet via NSG rules is possible in public preview. More details can be found here.
With current functionality there are some restrictions:
You must allow incoming Internet traffic on TCP ports 65503-65534 for the Application Gateway v1 SKU, and TCP ports 65200-65535 for the v2 SKU with the destination subnet as Any and source as GatewayManager service tag. This port range is required for Azure infrastructure communication.
Additionally, outbound Internet connectivity can't be blocked, and inbound traffic coming from the AzureLoadBalancer tag must be allowed.
For more information, see Application Gateway configuration overview.
Next steps
After learning about Application Gateway health monitoring, you can configure a custom health probe in the Azure portal or a custom health probe using PowerShell and the Azure Resource Manager deployment model.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for