Customer activities required
Pre-incident
For Azure services
- Be familiar with Azure Service Health in the Azure portal. This page will act as the “one-stop shop” during an incident
- Consider the use of Service Health alerts, which can be configured to automatically produce notifications when Azure incidents occur
For Power BI
- Be familiar with Service Health in the Microsoft 365 admin center. This page will act as the “one-stop shop” during an incident
- Consider the use of Microsoft 365 Admin mobile app to get automatic service incident alert notifications
During the incident
For Azure services
- Azure Service Health within their Azure management portal will provide the latest updates
- If there are issues accessing Service Health, refer to the Azure Status page
- If there are ever issues accessing the Status page, go to @AzureSupport on X (formerly Twitter)
- If impact/issues don’t match the incident (or persist after mitigation), then contact support to raise a service support ticket
For Power BI
- The Service Health page within their Microsoft 365 admin center will provide the latest updates
- If there are issues accessing Service Health, refer to the Microsoft 365 status page
- If impact/issues don't match the incident (or if issues persist after mitigation), you should raise a service support ticket.
Post Microsoft recovery
See the sections below for this detail.
Post incident
For Azure Services
- Microsoft will publish a PIR to the Azure portal - Service Health for review
For Power BI
- Microsoft will publish a PIR to the Microsoft 365 Admin - Service Health for review
Wait for Microsoft process
The “Wait for Microsoft” process is simply waiting for Microsoft to recover all components and services in the impacted, primary region. Once recovered, validate the binding of the data platform to enterprise shared or other services, the date of the dataset, and then execute the processes of bringing the system up to the current date.
Once this process has been completed, technical and business SME validation can be completed enabling the stakeholder approval for the service recovery.
Redeploy on disaster
For a “Redeploy on Disaster” strategy, the following high-level process flow can be described.
Recover Contoso – Enterprise Shared Services and source systems

- This step is a prerequisite to the recovery of the data platform
- This step would be completed by the various Contoso operational support groups responsible for the enterprise shared services and operational source systems
Recover Azure services Azure Services refers to the applications and services that make the Azure Cloud offering, are available within the secondary region for deployment.

Azure Services refers to the applications and services that make the Azure Cloud offering, are available within the secondary region for deployment.
- This step is a prerequisite to the recovery of data platform
- This step would be completed by Microsoft and other PaaS/SaaS partners
Recover the data platform foundation
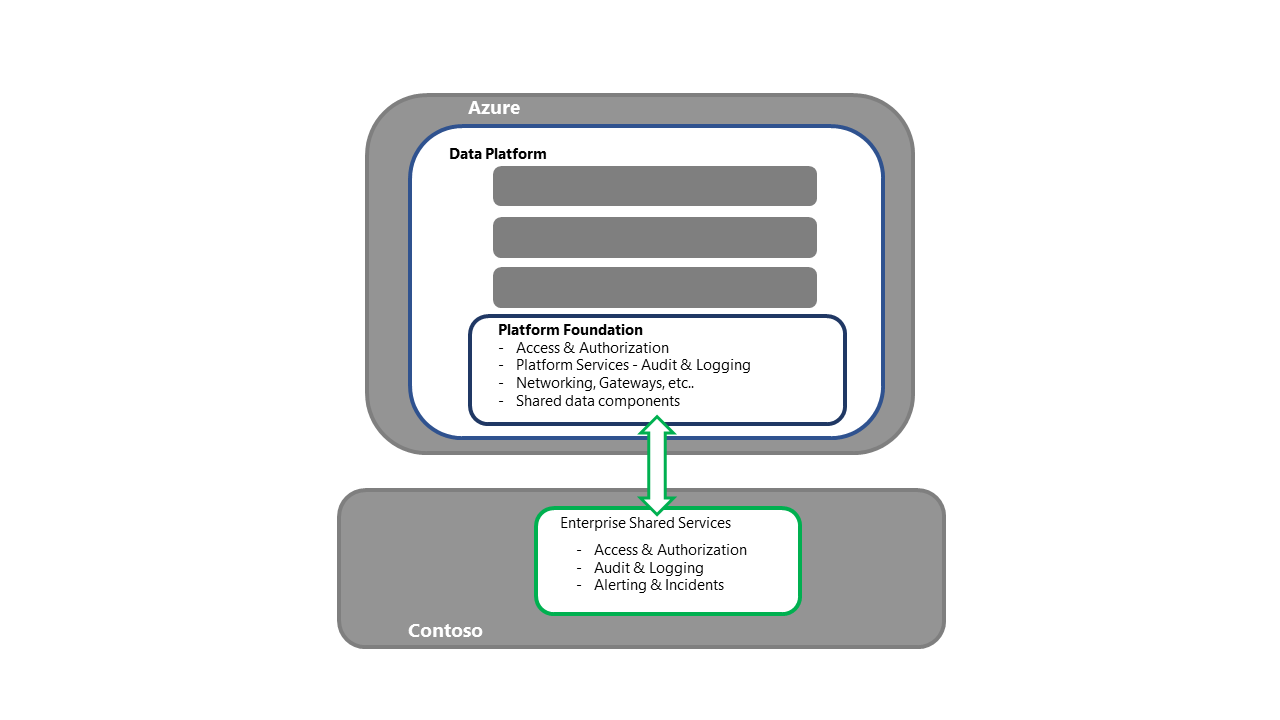
- This step is the entry point for the Platform recovery activities
- For the Redeployment strategy, each required component/service would be procured and deployed into the secondary region
- See the Azure Service and Component Section in this series for a detailed breakdown of the components and deployment strategies
- This process should also include activities like the binding to the enterprise shared services, ensuring connectivity to access/authentication, and validating that the log offloading is working, while also ensuring connectivity to both upstream and downstream processes
- Data/Processing should be confirmed. For example, validation of the timestamp of the recovered platform
- If there are questions about data integrity, the decision could be made to roll back further in time before executing the new processing to bring the platform up to date
- Having a priority order for processes (based upon business impact) will help in orchestrating the recovery
- This step should be closed out by technical validation unless business users directly interact with the services. If there is direct access, there will need to be a business validation step
- Once validation has been completed, a handover to the individual solution teams to start their own DR recovery process happens
- This handover should include confirmation of the current timestamp of the data/processes
- If core enterprise data processes are going to be executed, the individual solutions should be made aware of this - inbound/outbound flows, for example
Recover the individual solutions hosted by the platform
- Each individual solution should have its own DR runbook. The runbooks should at least contain the nominated business stakeholders who will test and confirm that service recovery has been completed
- Depending on resource contention or priority, key solutions/workloads may be prioritized over others - core enterprise processes over ad hoc labs, for example
- Once the validation steps have been completed, a handover to the downstream solutions to start their DR recovery process happens
Handover to downstream, dependent systems
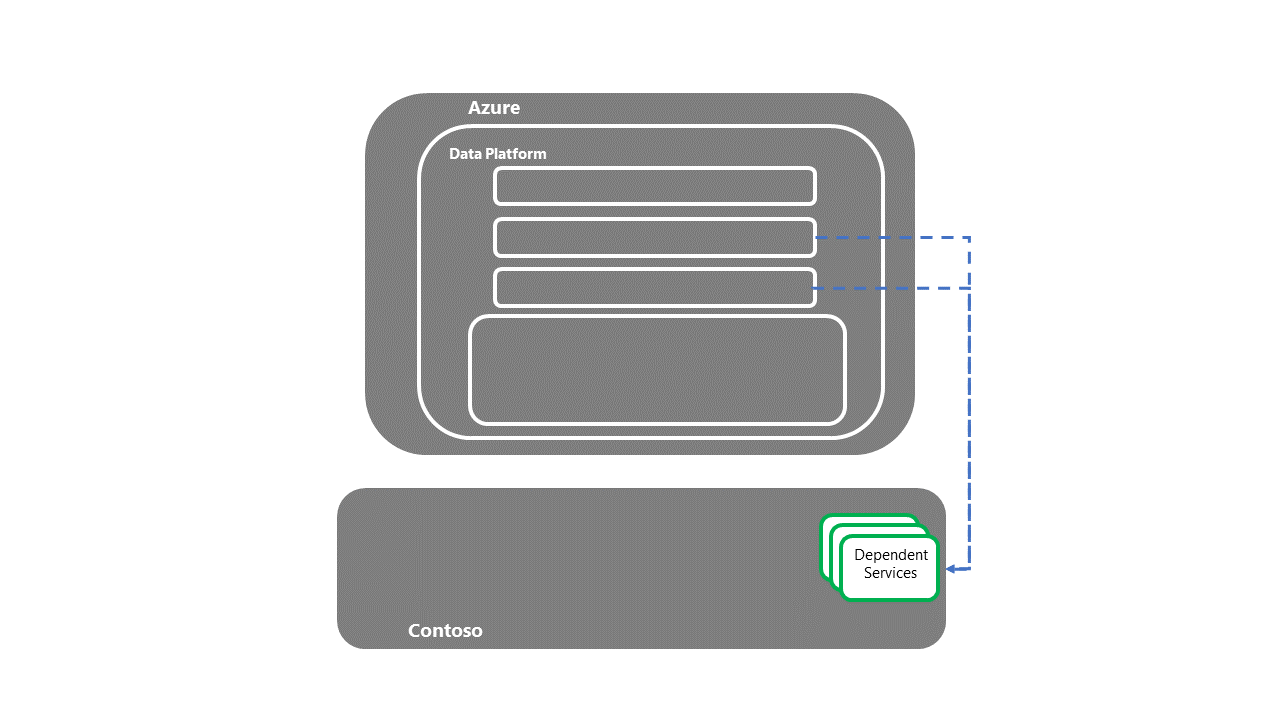
- Once the dependent services have been recovered, the E2E DR recovery process is complete
Note
While it's theoretically possible to completely automate an E2E DR process, it’s unlikely given the risk of the event vs. the cost of the SDLC activities required to cover the E2E process
Fallback to the primary region Fallback is the process of moving the data platform service and its data back to the primary region, once it's available for BAU.
Depending on the nature of the source systems and various data processes, fallback of the data platform could be done independently of other parts of the data eco-system.
Customers are advised to review their own data platform’s dependencies (both upstream and downstream) to make the appropriate decision. The following section assumes an independent recovery of the data platform.
- Once all required components/services have become available in the primary region, customers would complete a smoke-test to validate the Microsoft recovery
- Component/Service configuration would be validated. Deltas would be addressed via redeployment from source control
- The system date in the primary region would be established across stateful components. The delta between the established date and the date/timestamp in the secondary region should be addressed by re-executing or replaying the data ingestion processes from that point forward
- With approval from both business and technical stakeholders, a fallback window would be selected. Ideally, during a lull in system activity and processing
- During the fallback, the primary region would be brought into sync with the secondary region, before the system was switched over
- After a period of a parallel run, the secondary region would be taken offline from the system
- The components in the secondary region would either be dropped or stripped back, depending on the DR strategy selected
Warm spare process
For a “Warm Spare” strategy, the high-level process flow is closely aligned to that of the “Redeploy on Disaster”, the key difference being that components have already been procured in the secondary region. This strategy eliminates the risk of resource contention from other organizations looking to complete their own DR in that region.
Hot spare process
The "Hot Spare" strategy means that the Platform services including PaaS and IaaS systems will persist despite the disaster event as the secondary systems run in tandem with the primary systems. As with the "Warm Spare" strategy, this strategy eliminates the risk of resource contention from other organizations looking to complete their own DR in that region.
Hot Spare customers would monitor the Microsoft recovery of components/services in the primary region. Once completed, customers would validate the primary region systems and complete the fallback to the primary region. This process would be similar to the DR Failover process that is, check the available codebase and data, redeploying as required.
Note
A special note here should be made to ensure that any system metadata is consistent between the two regions.
- Once Fallback to the primary has been completed, the system load balancers can be updated to bring the primary region back into system topology. If available, a canary release approach can be used to incrementally switch the primary region on for the system.
DR plan structure
An effective DR plan presents a step-by-step guide for service recovery that can be executed by an Azure technical resource. As such, the following lists a proposed MVP structure for a DR Plan.
- Process Requirements
- Any customer DR process-specific detail, such as the correct authorization required to start DR, and make key decisions about the recovery as necessary (including “definition of done”), service support DR ticketing reference, and war room details
- Resource confirmation, including the DR lead and executor backup. All resources should be documented with primary and secondary contacts, escalation paths, and leave calendars. In critical DR situations, roster systems may need to be considered
- Laptop, power packs and/or backup power, network connectivity and mobile phone details for the DR executor, DR backup and any escalation points
- The process to be followed if any of the process requirements aren’t met
- Contact Listing
- DR leadership and support groups
- Business SMEs who will complete the test/review cycle for the technical recovery
- Impacted Business Owners, including the service recovery approvers
- Impacted Technical Owners, including the technical recovery approvers
- SME support across all impacted areas, including key solutions hosted by the platform
- Impact Downstream systems – operational support
- Upstream Source systems – operational support
- Enterprise shared services contacts. For example, access/authentication support, security monitoring and gateway support
- Any external or third party vendors, including support contacts for cloud providers
- Architecture design
- Describe the end-end to E2E scenario detail, and attach all associated support documentation
- Dependencies
- List out all the component’s relationships and dependencies
- DR Prerequisites
- Confirmation that upstream source systems are available as required
- Elevated access across the stack has been granted to the DR executor resources
- Azure services are available as required
- The process to be followed if any of the prerequisites haven’t been met
- Technical Recovery - Step-by-Step instructions
- Run order
- Step description
- Step prerequisite
- Detailed process steps for each discrete action, including URL’s
- Validation instructions, including the evidence required
- Expected time to complete each step, including contingency
- The process to be followed if the step fails
- The escalation points in the case of failure or SME support
- Technical Recovery - Post requisites
- Confirm the current date timestamp of the system across key components
- Confirm the DR system URLs & IPs
- Prepare for the Business Stakeholder review process, including confirmation of systems access and the business SMEs completing the validation and approval
- Business Stakeholder Review and Approval
- Business resource contact details
- The Business validation steps as per the technical recovery above
- The Evidence trail required from the Business approver signing off the recovery
- Recovery Post requisites
- Handover to operational support to execute the data processes to bring the system up to date
- Handover the downstream processes and solutions – confirming the date and connection details of the DR system
- Confirm recovery process complete with the DR lead – confirming the evidence trail and completed runbook
- Notify Security administration that elevated access privileges can be removed from the DR team
Callouts
- It's recommended to include system screenshots of each step process. These screenshots will help address the dependency on system SMEs to complete the tasks
- To mitigate the risk from quickly evolving Cloud services, the DR plan should be regularly revisited, tested, and executed by resources with current knowledge of Azure and its services
- The technical recovery steps should reflect the priority of the component and solution to the organization. For example, core enterprise data flows are recovered before ad hoc data analysis labs
- The Technical recovery steps should follow the order of the workflows (typically left to right), once the foundation components/service like Key Vault have been recovered. This strategy will ensure upstream dependencies are available and components can be appropriately tested
- Once the step-by-step plan has been completed, a total time for activities with contingency should be obtained. If this total is over the agreed RTO, there are several options available:
- Automate selected recovery processes (where possible)
- Look for opportunities to run selected recovery steps in parallel (where possible). However, noting that this strategy may require additional DR executor resources.
- Uplift key components to higher levels of service tiers such as PaaS, where Microsoft takes greater responsibility for service recovery activities
- Extend the RTO with stakeholders
DR testing
The nature of the Azure Cloud service offering results in constraints for any DR testing scenarios. Therefore, the guidance is to stand up a DR subscription with the data platform components as they would be available in the secondary region.
From this baseline, the DR plan runbook can be selectively executed, paying specific attention to the services and components that can be deployed and validated. This process will require a curated test dataset, enabling the confirmation of the technical and business validation checks as per the plan.
A DR plan should be tested regularly to not only ensure that it's up to date, but also to build "muscle memory" for the teams performing failover and recovery activities.
- Data and configuration backups should also be regularly tested to ensure they are “fit for purpose” to support any recovery activities.
The key area to focus on during a DR test is to ensure the prescriptive steps are still correct and the estimated timings are still relevant.
- If the instructions reflect the portal screens rather than code – the instructions should be validated at least every 12 months due to the cadence of change in cloud.
While the aspiration is to have a fully automated DR process, full automation may be unlikely due to the rarity of the event. Therefore, it's recommended to establish the recovery baseline with DSC IaC used to deliver the platform and then uplift as new projects build upon the baseline.
- Over time as components and services are extended, an NFR should be enforced, requiring the production deployment pipeline to be refactored to provide coverage for DR.
If your runbook timings exceed your RTO, there are several options:
- Extend the RTO with stakeholders
- Lower the time required for the recovery activities, via automation, running tasks in parallel or migration to higher cloud server tiers
Azure Chaos Studio
Azure Chaos Studio is a managed service for improving resilience by injecting faults into your Azure applications. Chaos Studio enables you to orchestrate fault injection on your Azure resources in a safe and controlled way, using experiments. See the product documentation for a description of the types of faults currently supported.
The current iteration of Chaos Studio only covers a subset of Azure components and services. Until more fault libraries are added, Chaos Studio is a recommended approach for isolated resiliency testing rather than full system DR testing.
More information on Chaos studio can be found here
Azure Site Recovery
For IaaS components, Azure Site Recovery will protect most workloads running on a supported VM or physical server
There is strong guidance for:
- Executing an Azure VM Disaster Recovery Drill
- Executing a DR failover to a Secondary Region
- Executing a DR fallback to the Primary Region
- Enabling automation of a DR Plan
Related resources
- Architecting for resiliency and availability
- Business continuity and disaster recovery
- Backup and disaster recovery for Azure applications
- Resiliency in Azure
- Service Level Agreements Summary
- Five Best Practices to Anticipate Failure
Next steps
Now that you've learned how to deploy the scenario, you can read a summary of the DR for Azure data platform series.