High availability and disaster recovery
As with any cloud systems, unplanned outages can occur that result in a virtual machines (VM) instance, an Availability Zone, or a complete Azure region going down. We recommend customers have a plan in place to handle zone or regional outages.
This article presents the information for customers to create a business continuity and disaster recovery plan for their Azure Cache for Redis, or Azure Cache for Redis Enterprise implementation.
Various high availability options are available in the Standard, Premium, and Enterprise tiers:
| Option | Description | Availability | Standard | Premium | Enterprise |
|---|---|---|---|---|---|
| Standard replication | Dual-node replicated configuration in a single data center with automatic failover | 99.9% (see details) | ✔ | ✔ | ✔ |
| Zone redundancy | Multi-node replicated configuration across Availability Zones, with automatic failover | 99.9% in Premium; 99.99% in Enterprise (see details) | - | ✔ | ✔ |
| Geo-replication | Linked cache instances in two regions, with user-controlled failover | Premium; Enterprise (see details) | - | Passive | Active |
| Import/Export | Point-in-time snapshot of data in cache. | 99.9% (see details) | - | ✔ | ✔ |
| Persistence | Periodic data saving to storage account. | 99.9% (see details) | - | ✔ | Preview |
Standard replication for high availability
Applicable tiers: Standard, Premium, Enterprise, Enterprise Flash
Recommended for: High availability
Azure Cache for Redis has a high availability architecture that ensures your managed instance is functioning, even when outages affect the underlying virtual machines (VMs). Whether the outage is planned or unplanned outages, Azure Cache for Redis delivers greater percentage availability rates than what's attainable by hosting Redis on a single VM.
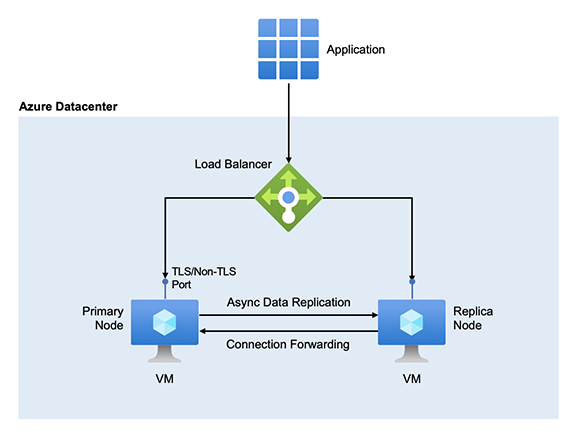
An Azure Cache for Redis in the applicable tiers runs on a pair of Redis servers by default. The two servers are hosted on dedicated VMs. Open-source Redis allows only one server to handle data write requests.
With Azure Cache for Redis, one server is the primary node, while the other is the replica. After it provisions the server nodes, Azure Cache for Redis assigns primary and replica roles to them. The primary node usually is responsible for servicing write and read requests from clients. On a write operation, it commits a new key and a key update to its internal memory and replies immediately to the client. It forwards the operation to the replica asynchronously.
Note
Normally, an Azure Cache for Redis client application communicates with the primary node in a cache for all read and write requests. Certain clients can be configured to read from the replica node.
If the primary node in a cache is unavailable, the replica automatically promotes itself to become the new primary. This process is called a failover. A failover is just two nodes, primary/replica, trading roles, replica/primary, with one of the nodes possibly going offline for a few minutes. In most failovers, the primary and replica nodes coordinate the handover so you have near zero time without a primary.
The former primary goes offline briefly to receive updates from the new primary. Then, the now replica comes back online and rejoins the cache fully synchronized. The key is that when a node is unavailable, it's a temporary condition and it comes back online.
A typical failover sequence looks like this, when a primary needs to go down for maintenance:
- Primary and replica nodes negotiate a coordinated failover and trade roles.
- Replica (formerly primary) goes offline for a reboot.
- A few seconds or minutes later, the replica comes back online.
- Replica syncs the data from the primary.
A primary node can go out of service as part of a planned maintenance activity, such as an update to Redis software or the operating system. It also can stop working because of unplanned events such as failures in underlying hardware, software, or network. Failover and patching for Azure Cache for Redis provides a detailed explanation on types of failovers. An Azure Cache for Redis goes through many failovers during its lifetime. The design of the high availability architecture makes these changes inside a cache as transparent to its clients as possible.
Also, Azure Cache for Redis provides more replica nodes in the Premium tier. A multi-replica cache can be configured with up to three replica nodes. Having more replicas generally improves resiliency because you have nodes backing up the primary. Even with more replicas, an Azure Cache for Redis instance still can be severely affected by a data center or Availability Zone outage. You can increase cache availability by using multiple replicas with zone redundancy.
Zone redundancy
Applicable tiers: Premium, Enterprise, Enterprise Flash
Recommended for: High availability, Disaster recovery - intra region
Azure Cache for Redis supports zone redundant configurations in the Premium and Enterprise tiers. A zone redundant cache can place its nodes across different Azure Availability Zones in the same region. It eliminates data center or AZ outage as a single point of failure and increases the overall availability of your cache. See this article for information on how to set it up.
If a cache is configured to use two or more zones as described earlier in the article, the cache nodes are created in different zones. When a zone goes down, cache nodes in other zones are available to keep the cache functioning as usual.
Azure Cache for Redis supports zone redundant configurations in the Premium and Enterprise tiers. A zone redundant cache can place its nodes across different Azure Availability Zones in the same region. It eliminates data center or Availability Zone outage as a single point of failure and increases the overall availability of your cache.
Premium tier
The following diagram illustrates the zone redundant configuration for the Premium tier:
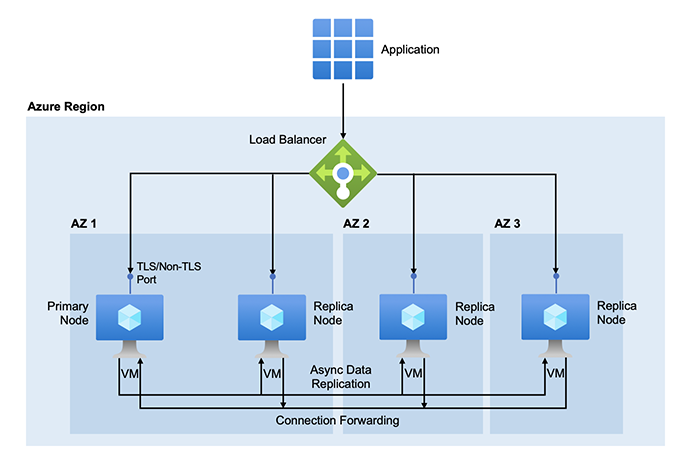
Azure Cache for Redis distributes nodes in a zone redundant cache in a round-robin manner over the selected Availability Zones. It also determines the node that serves as the primary initially.
Zone Down Experience for Premium tier
A zone redundant cache provides automatic failover. When the current primary node is unavailable, one of the replicas takes over. Your application may experience higher cache response time if the new primary node is located in a different AZ. Availability Zones are geographically separated. Switching from one AZ to another alters the physical distance between where your application and cache are hosted. This change impacts round-trip network latencies from your application to the cache. The extra latency is expected to fall within an acceptable range for most applications. We recommend you test your application to ensure it does well with a zone-redundant cache.
Enterprise and Enterprise Flash tiers
A cache in either Enterprise tier runs on a Redis Enterprise cluster. It always requires an odd number of server nodes to form a quorum. By default, it has three nodes, each hosted on a dedicated VM.
- An Enterprise cache has two same-sized data nodes and one smaller quorum node.
- An Enterprise Flash cache has three same-sized data nodes.
The Enterprise cluster divides Azure Cache for Redis data into partitions internally. Each partition has a primary and at least one replica. Each data node holds one or more partitions. The Enterprise cluster ensures that the primary and replica(s) of any partition are never collocated on the same data node. Partitions replicate data asynchronously from primaries to their corresponding replicas.
Zone Down Experience for Enterprise tiers
When a data node becomes unavailable or a network split happens, a failover similar to the one described in Standard replication takes place. The Enterprise cluster uses a quorum-based model to determine which surviving nodes participate in a new quorum. It also promotes replica partitions within these nodes to primaries as needed.
Regional availability
Zone-redundant Premium tier caches are available in the following regions:
| Americas | Europe | Middle East | Africa | Asia Pacific |
|---|---|---|---|---|
| Brazil South | France Central | Qatar Central | South Africa North | Australia East |
| Canada Central | Germany West Central | Central India | ||
| Central US | North Europe | Japan East | ||
| East US | Norway East | Korea Central | ||
| East US 2 | UK South | Southeast Asia | ||
| South Central US | West Europe | East Asia | ||
| US Gov Virginia | Sweden Central | China North 3 | ||
| West US 2 | Switzerland North | |||
| West US 3 |
Zone-redundant Enterprise and Enterprise Flash tier caches are available in the following regions:
| Americas | Europe | Middle East | Africa | Asia Pacific |
|---|---|---|---|---|
| Canada Central* | North Europe | Australia East | ||
| Central US* | UK South | Central India | ||
| East US | West Europe | Southeast Asia | ||
| East US 2 | Japan East* | |||
| South Central US | East Asia* | |||
| West US 2 | ||||
| West US 3 | ||||
| Brazil South |
* Enterprise Flash tier not available in this region.
Availability zone redeployment and migration
Currently, the only way to convert your cache from a non-AZ configuration to an AZ configuration is to redeploy the cache. To learn how to redeploy your current cache, see Migrate an Azure Cache for Redis instance to availability zone support.
Persistence
Applicable tiers: Premium, Enterprise (preview), Enterprise Flash (preview)
Recommended for: Data durability
Because your cache data is stored in memory, a rare and unplanned failure of multiple nodes can cause all the data to be dropped. To avoid losing data completely, Redis persistence allows you to take periodic snapshots of in-memory data, and store it to your storage account. If you experience a failure across multiple nodes causing data loss, your cache loads the snapshot from storage account. For more information, see Configure data persistence for a Premium Azure Cache for Redis instance.
Storage account for persistence
Consider choosing a geo-redundant storage account to ensure high availability of persisted data. For more information, see Azure Storage redundancy.
Import/Export
Applicable tiers: Premium, Enterprise, Enterprise Flash
Recommended for: Disaster recovery
Azure cache for Redis supports the option to import and export Redis Database (RDB) files to provide data portability. It allows you to import data into Azure Cache for Redis or export data from Azure Cache for Redis by using an RDB snapshot. The RDB snapshot from a premium cache is exported to a blob in an Azure Storage Account. You can create a script to trigger export periodically to your storage account. For more information, see Import and Export data in Azure Cache for Redis.
Storage account for export
Consider choosing a geo-redundant storage account to ensure high availability of your exported data. For more information, see Azure Storage redundancy.
Passive Geo-replication
Applicable tiers: Premium
Recommended for: Disaster recovery - single region
Geo-replication is a mechanism for linking two or more Azure Cache for Redis instances, typically spanning two Azure regions. Geo-replication is designed mainly for cross-region disaster recovery. Two Premium tier cache instances are connected through geo-replication in a way that provides reads and writes to your primary cache, and that data is replicated to the secondary cache.
For more information on how to set it up, see Configure geo-replication for Premium Azure Cache for Redis instances.
If the region hosting the primary cache goes down, you’ll need to start the failover by: first, unlinking the secondary cache, and then, updating your application to point to the secondary cache for reads and writes.
Active geo-replication
Applicable tiers: Enterprise, Enterprise Flash
Recommended for: High Availability, Disaster recovery - multi-region
The Enterprise tiers support a more advanced form of geo-replication called active geo-replication that offers both higher availability and cross-region disaster recovery across multiple regions. The Azure Cache for Redis Enterprise software uses conflict-free replicated data types to support writes to multiple cache instances, merges changes, and resolves conflicts. You can join up to five Enterprise tier cache instances in different Azure regions to form a geo-replication group.
An application using such a cache can read and write to any of the geo-distributed cache instances through their corresponding endpoints. The application should use what is the closest to each application instance, giving you the lowest latency. For more information, see Configure active geo-replication for Enterprise Azure Cache for Redis instances.
If a region of one of the caches in your replication group goes down, your application needs to switch to another region that is available.
When a cache in your replication group is unavailable, we recommend monitoring memory usage for other caches in the same replication group. While one of the caches is down, all other caches in the replication group start saving metadata that they couldn't share with the cache that is down. If the memory usage for the available caches starts growing at a high rate after one of the caches goes down, consider unlinking the cache that is unavailable from the replication group.
For more information on force-unlinking, see Force-Unlink if there's region outage.
Delete and recreate cache
Applicable tiers: Standard, Premium, Enterprise, Enterprise Flash
If you experience a regional outage, consider recreating your cache in a different region, and updating your application to connect to the new cache instead. It's important to understand that data is lost during a regional outage. Your application code should be resilient to data loss.
Once the affected region is restored, your unavailable Azure Cache for Redis is automatically restored, and available for use again. For more strategies for moving your cache to a different region, see Move Azure Cache for Redis instances to different regions.
Next steps
Learn more about how to configure Azure Cache for Redis high-availability options.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for