Clustering point data in the Web SDK
When there are many data points on the map, some may overlap over each other. The overlap may cause the map may become unreadable and difficult to use. Clustering point data is the process of combining point data that are near each other and representing them on the map as a single clustered data point. As the user zooms into the map, the clusters break apart into their individual data points. When you work with a large number of data points, the clustering processes can improve the user experience.
Enabling clustering on a data source
Enable clustering in the DataSource class by setting the cluster option to true. Set clusterRadius to select nearby points and combines them into a cluster. The value of clusterRadius is in pixels. Use clusterMaxZoom to specify a zoom level at which to disable the clustering logic. Here's an example of how to enable clustering in a data source.
//Create a data source and enable clustering.
var datasource = new atlas.source.DataSource(null, {
//Tell the data source to cluster point data.
cluster: true,
//The radius in pixels to cluster points together.
clusterRadius: 45,
//The maximum zoom level in which clustering occurs.
//If you zoom in more than this, all points are rendered as symbols.
clusterMaxZoom: 15
});
Tip
If two data points are close together on the ground, it's possible the cluster will never break apart, no matter how close the user zooms in. To address this, you can set the clusterMaxZoom option to disable the clustering logic and simply display everything.
The DataSource class provides the following methods related to clustering as well.
| Method | Return type | Description |
|---|---|---|
| getClusterChildren(clusterId: number) | Promise<Array<Feature<Geometry, any> | Shape>> | Retrieves the children of the given cluster on the next zoom level. These children may be a combination of shapes and subclusters. The subclusters are features with properties matching ClusteredProperties. |
| getClusterExpansionZoom(clusterId: number) | Promise<number> | Calculates a zoom level at which the cluster starts expanding or break apart. |
| getClusterLeaves(clusterId: number, limit: number, offset: number) | Promise<Array<Feature<Geometry, any> | Shape>> | Retrieves the points in a cluster. By default the first 10 points are returned. To page through the points, use limit to specify the number of points to return, and offset to step through the index of points. To return all points, set limit to Infinity and don't set offset. |
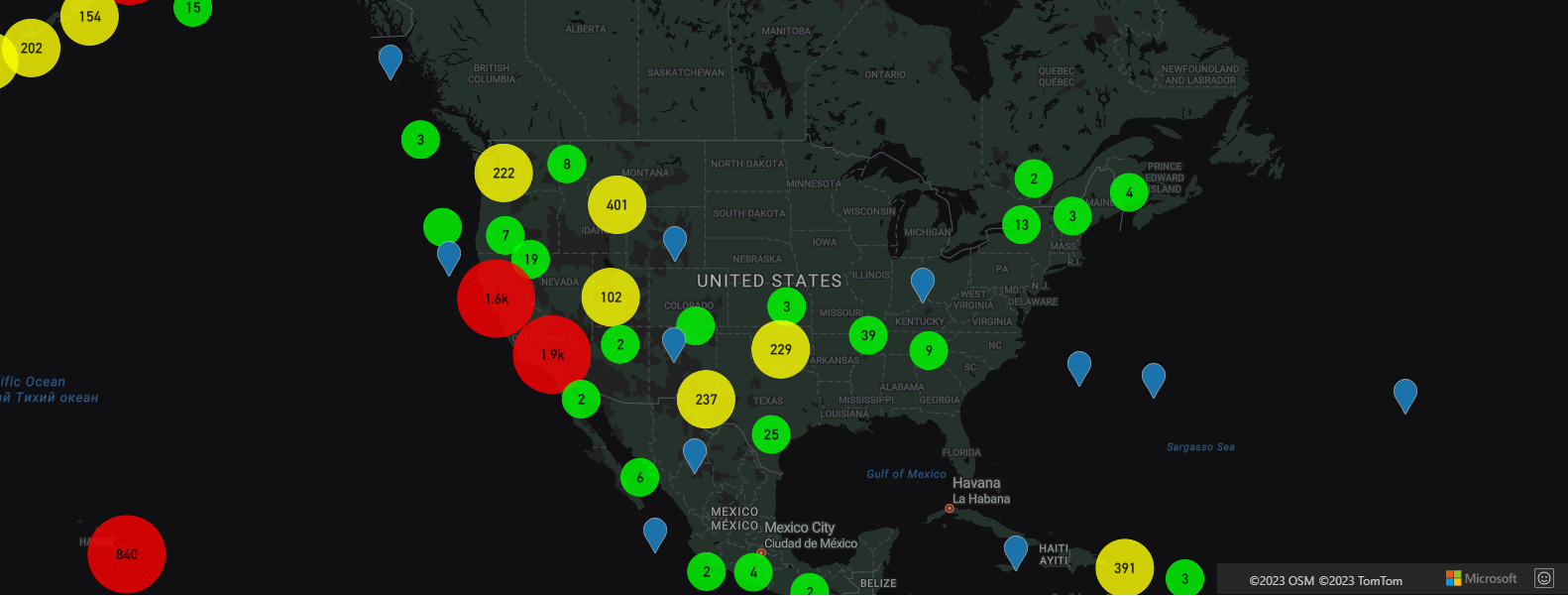
Display clusters using a bubble layer
A bubble layer is a great way to render clustered points. Use expressions to scale the radius and change the color based on the number of points in the cluster. If you display clusters using a bubble layer, then you should use a separate layer to render unclustered data points.
To display the size of the cluster on top of the bubble, use a symbol layer with text, and don't use an icon.
For a complete working sample of how to implement displaying clusters using a bubble layer, see Point Clusters in Bubble Layer in the Azure Maps Samples. For the source code for this sample, see Point Clusters in Bubble Layer source code.
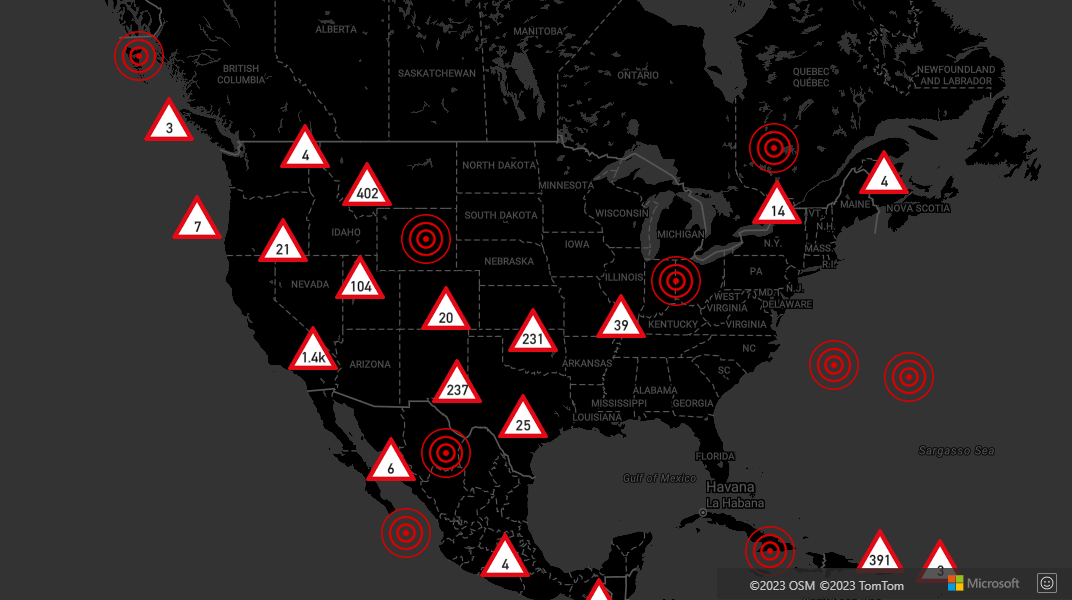
Display clusters using a symbol layer
When visualizing data points, the symbol layer automatically hides symbols that overlap each other to ensure a cleaner user interface. This default behavior might be undesirable if you want to show the data points density on the map. However, these settings can be changed. To display all symbols, set the allowOverlap option of the Symbol layers iconOptions property to true.
Use clustering to show the data points density while keeping a clean user interface. The following sample shows you how to add custom symbols and represent clusters and individual data points using the symbol layer.
For a complete working sample of how to implement displaying clusters using a symbol layer, see Display clusters with a Symbol Layer in the Azure Maps Samples. For the source code for this sample, see Display clusters with a Symbol Layer source code.
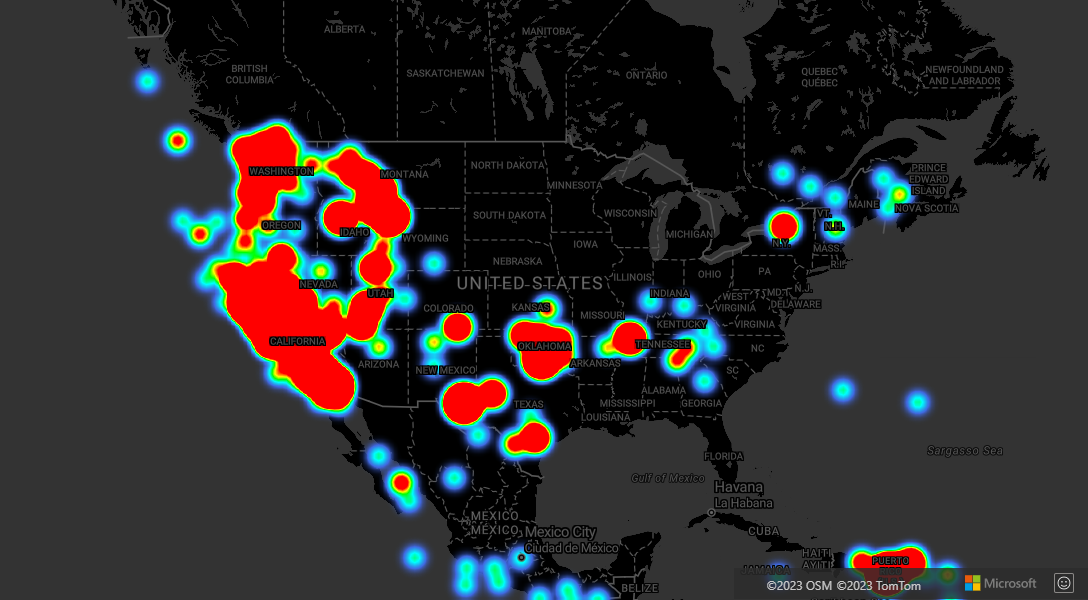
Clustering and the heat maps layer
Heat maps are a great way to display the density of data on the map. This visualization method can handle a large number of data points on its own. If the data points are clustered and the cluster size is used as the weight of the heat map, then the heat map can handle even more data. To achieve this option, set the weight option of the heat map layer to ['get', 'point_count']. When the cluster radius is small, the heat map looks nearly identical to a heat map using the unclustered data points, but it performs better. However, the smaller the cluster radius, the more accurate the heat map is, but with fewer performance benefits.
For a complete working sample that demonstrates how to create a heat map that uses clustering on the data source, see Cluster weighted Heat Map in the Azure Maps Samples. For the source code for this sample, see Cluster weighted Heat Map source code.
Mouse events on clustered data points
When mouse events occur on a layer that contains clustered data points, the clustered data point return to the event as a GeoJSON point feature object. This point feature has the following properties:
| Property name | Type | Description |
|---|---|---|
cluster |
boolean | Indicates if feature represents a cluster. |
cluster_id |
string | A unique ID for the cluster that can be used with the DataSource getClusterExpansionZoom, getClusterChildren, and getClusterLeaves methods. |
point_count |
number | The number of points the cluster contains. |
point_count_abbreviated |
string | A string that abbreviates the point_count value if it's long. (for example, 4,000 becomes 4K) |
The Point Clusters in Bubble Layer example takes a bubble layer that renders cluster points and adds a click event. When the click event triggers, the code calculates and zooms the map to the next zoom level, at which the cluster breaks apart. This functionality is implemented using the getClusterExpansionZoom method of the DataSource class and the cluster_id property of the clicked clustered data point.
The following code snippet shows the code in the Point Clusters in Bubble Layer example that adds the click event functionality to the clustered data points:
//Add a click event to the layer so we can zoom in when a user clicks a cluster.
map.events.add('click', clusterBubbleLayer, clusterClicked);
//Add mouse events to change the mouse cursor when hovering over a cluster.
map.events.add('mouseenter', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'pointer';
});
map.events.add('mouseleave', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'grab';
});
function clusterClicked(e) {
if (e && e.shapes && e.shapes.length > 0 && e.shapes[0].properties.cluster) {
//Get the clustered point from the event.
var cluster = e.shapes[0];
//Get the cluster expansion zoom level. This is the zoom level at which the cluster starts to break apart.
datasource.getClusterExpansionZoom(cluster.properties.cluster_id).then(function (zoom) {
//Update the map camera to be centered over the cluster.
map.setCamera({
center: cluster.geometry.coordinates,
zoom: zoom,
type: 'ease',
duration: 200
});
});
}
}
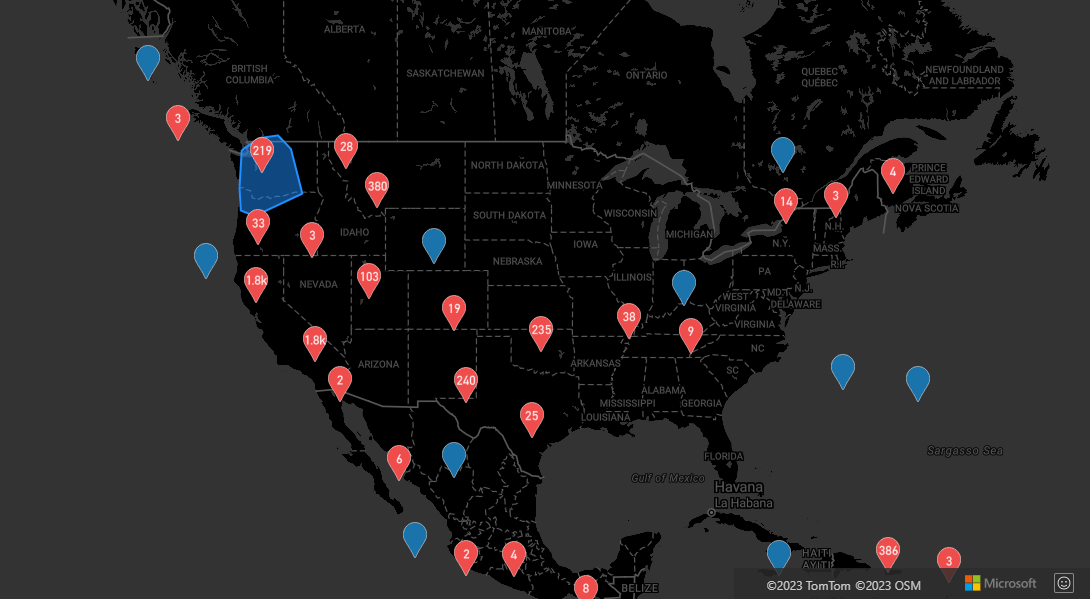
Display cluster area
The point data that a cluster represents is spread over an area. In this sample when the mouse is hovered over a cluster, two main behaviors occur. First, the individual data points contained in the cluster are used to calculate a convex hull. Then, the convex hull is displayed on the map to show an area. A convex hull is a polygon that wraps a set of points like an elastic band and can be calculated using the atlas.math.getConvexHull method. All points contained in a cluster can be retrieved from the data source using the getClusterLeaves method.
For a complete working sample that demonstrates how to do this, see Display cluster area with Convex Hull in the Azure Maps Samples. For the source code for this sample, see Display cluster area with Convex Hull source code.
Aggregating data in clusters
Often clusters are represented using a symbol with the number of points that are within the cluster. But, sometimes it's desirable to customize the style of clusters with more metrics. With cluster aggregates, custom properties can be created and populated using an aggregate expression calculation. Cluster aggregates can be defined in clusterProperties option of the DataSource.
The Cluster aggregates sample uses an aggregate expression. The code calculates a count based on the entity type property of each data point in a cluster. When a user selects a cluster, a popup shows with additional information about the cluster. For the source code for this sample, see Cluster aggregates source code.

Next steps
Learn more about the classes and methods used in this article:
See code examples to add functionality to your app:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for