What is Azure Synapse Link for Azure Cosmos DB?
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Azure Synapse Link for Azure Cosmos DB is a cloud-native hybrid transactional and analytical processing (HTAP) capability that enables near real time analytics over operational data in Azure Cosmos DB. Azure Synapse Link creates a tight seamless integration between Azure Cosmos DB and Azure Synapse Analytics.
Azure Cosmos DB analytical store, a fully isolated column store, can be used with Azure Synapse Link to enable Extract-Transform-Load (ETL) analytics in Azure Synapse Analytics against your operational data at scale. Business analysts, data engineers, and data scientists can now use Synapse Spark or Synapse SQL interchangeably to run near real time business intelligence, analytics, and machine learning pipelines. You can analyze real time data without affecting the performance of your transactional workloads on Azure Cosmos DB.
The following image shows the Azure Synapse Link integration with Azure Cosmos DB and Azure Synapse Analytics:
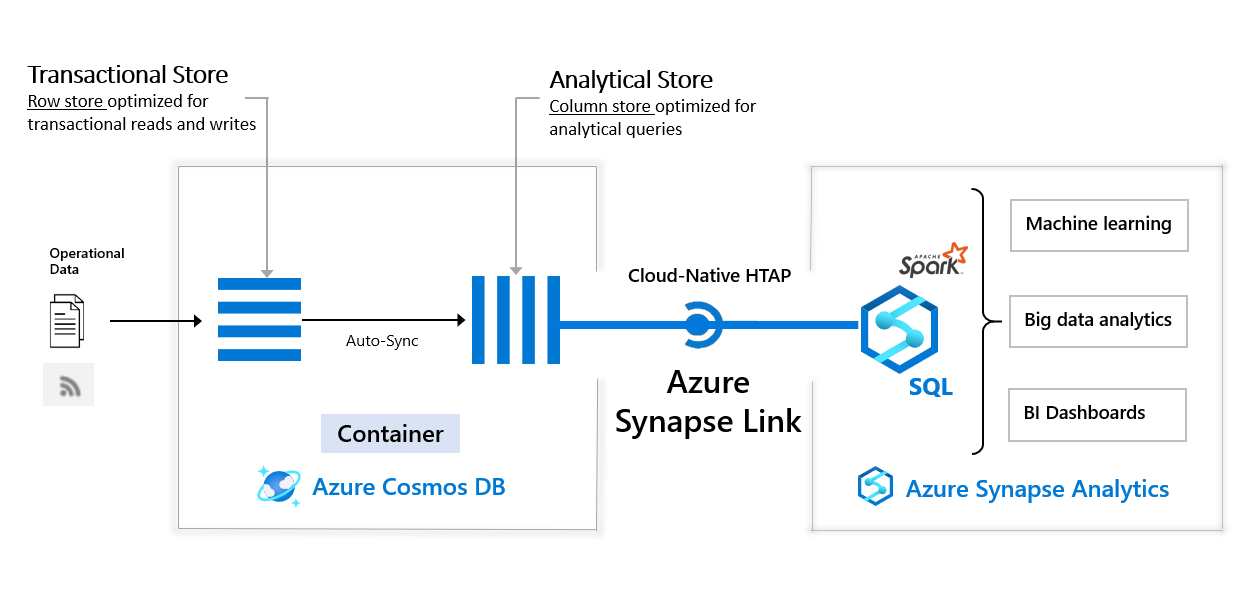
Benefits
To analyze large operational datasets while minimizing any effects on the performance of mission-critical transactional workloads, Azure Cosmos DB customers traditionally export the operational data. These operations are performed by Extract-Transform-Load (ETL) pipelines, which require many layers of data and jobs management, resulting in operational complexity and performance effects on your transactional workloads. It also increases the latency to analyze the operational data from the time of origin.
When compared to traditional ETL-based solutions, Azure Synapse Link for Azure Cosmos DB offers several advantages such as:
Reduced complexity with no ETL jobs to manage
Azure Synapse Link allows you to directly access Azure Cosmos DB analytical store using Azure Synapse Analytics without complex data movement. Any updates made to the operational data are visible in the analytical store in near real-time with no ETL or change feed jobs. You can run large-scale analytics against analytical store, from Azure Synapse Analytics, without extra data transformation.
Near real-time insights into your operational data
You can now get rich insights on your operational data in near real-time, using Azure Synapse Link. ETL-based systems tend to have higher latency for analyzing your operational data, due to many layers needed to extract, transform, and load the operational data. With native integration of Azure Cosmos DB analytical store with Azure Synapse Analytics, you can analyze operational data in near real-time enabling new business scenarios.
No performance compromise on operational workloads
With Azure Synapse Link, you can run analytical queries against an Azure Cosmos DB analytical store, a column store representation of your data. You can run the queries while the transactional operations are processed using provisioned throughput for the transactional workload, over the Azure Cosmos DB row-based transactional store. The analytical workload is independent of the transactional workload traffic, not consuming the throughput you allocated for your operational data.
Optimized for large-scale analytics workloads
Azure Cosmos DB analytical store is optimized to provide scalability, elasticity, and performance for analytical workloads without any dependency on the compute run-times. The storage technology is self-managed to optimize your analytics workloads. With built-in support into Azure Synapse Analytics, accessing this storage layer provides simplicity and high performance.
Cost-effective
With Azure Synapse Link, you can get a cost-optimized, fully managed solution for operational analytics. It eliminates extra storage and compute layers required in traditional ETL pipelines for analyzing operational data.
Azure Cosmos DB analytical store follows a consumption-based pricing model, which is based on data storage and analytical read/write operations and queries executed. It doesn’t require you to allocate any throughput, as you do today for the transactional workloads. Accessing your data with highly elastic compute engines from Azure Synapse Analytics makes the overall cost of running storage and compute efficient.
Analytics for locally available, globally distributed, multi-region writes
You can run analytical queries effectively against the nearest regional copy of the data in Azure Cosmos DB. Azure Cosmos DB provides the state-of-the-art capability to run the globally distributed analytical workloads along with transactional workloads in an active-active manner.
Enable HTAP scenarios for your operational data
Azure Synapse Link brings together Azure Cosmos DB analytical store with Azure Synapse Analytics runtime support. This integration enables you to build cloud native HTAP solutions that generate insights based on real-time updates to your operational data over large datasets. It unlocks new business scenarios to raise alerts based on live trends, build near real-time dashboards, and business experiences based on user behavior.
Azure Cosmos DB analytical store
Azure Cosmos DB analytical store is a column-oriented representation of your operational data in Azure Cosmos DB. This analytical store is suitable for fast, cost-effective queries on large operational data sets. This store can query data without copying data and impacting the performance of your transactional workloads.
Analytical store automatically picks up high frequency inserts, updates, deletes in your transactional workloads in near real-time, as a fully managed capability (“auto-sync”) of Azure Cosmos DB. No change feed or ETL is required.
If you have a globally distributed Azure Cosmos DB account, after you enable analytical store for a container, it will be available in all regions for that account. For more information on the analytical store, see Azure Cosmos DB Analytical store overview article.
Integration with Azure Synapse Analytics
With Azure Synapse Link, you can now directly connect to your Azure Cosmos DB containers from Azure Synapse Analytics and access the analytical store with no separate connectors. Azure Synapse Analytics currently supports Azure Synapse Link with Synapse Apache Spark and serverless SQL pool.
You can query the data from Azure Cosmos DB analytical store simultaneously, with interop across different analytics run times supported by Azure Synapse Analytics. No extra data transformations are required to analyze the operational data. You can query and analyze the analytical store data using:
Synapse Apache Spark with full support for Scala, Python, SparkSQL, and C#. Synapse Spark is central to data engineering and data science scenarios
Serverless SQL pool with T-SQL language and support for familiar BI tools (for example, Power BI Premium, etc.)
Note
From Azure Synapse Analytics, you can access both analytical and transactional stores in your Azure Cosmos DB container. However, if you want to run large-scale analytics or scans on your operational data, we recommend that you use analytical store to avoid performance impact on transactional workloads.
Note
You can run analytics with low latency in an Azure region by connecting your Azure Cosmos DB container to Synapse runtime in that region.
This integration enables the following HTAP scenarios for different users:
A BI Engineer, who wants to model and publish a Power BI report to access the live operational data in Azure Cosmos DB directly through Synapse SQL.
A Data Analyst, who wants to derive insights from the operational data in an Azure Cosmos DB container by querying it with Synapse SQL, read the data at scale and combine those findings with other data sources.
A Data Scientist, who wants to use Synapse Spark to find a feature to improve their model and train that model without doing complex data engineering. They can also write the results of the model post inference into Azure Cosmos DB for real-time scoring on the data through Spark Synapse.
A Data Engineer, who wants to make data accessible for consumers, by creating SQL or Spark tables over Azure Cosmos DB containers, without manual ETL processes.
For more information on Azure Synapse Analytics runtime support for Azure Cosmos DB, see Azure Synapse Analytics for Azure Cosmos DB support.
When to use Azure Synapse Link for Azure Cosmos DB?
Azure Synapse Link is recommended if you're an Azure Cosmos DB customer and you want to run analytics, BI, and machine learning over your operational data. For example:
If you're running analytics or BI on your Azure Cosmos DB operational data directly using separate connectors today, or
If you're running ETL processes to extract operational data into a separate analytics system.
In such cases, Azure Synapse Link provides a more integrated analytics experience without impacting your transactional store’s provisioned throughput.
Azure Synapse Link isn't recommended if you're looking for traditional data warehouse requirements. These requirements may include high concurrency, workload management, and persistence of aggregates across multiple data sources. For more information, see common scenarios that can be powered with Azure Synapse Link for Azure Cosmos DB.
Limitations
Azure Synapse Link for Azure Cosmos DB is supported for NoSQL and MongoDB APIs. It is not supported for Cassandra or Table APIs and remains in preview for Gremlin API.
Accessing the Azure Cosmos DB analytics store with Azure Synapse Dedicated SQL Pool currently isn't supported.
Although analytical store data isn't backed up, and therefore can't be restored, you can rebuild your analytical store by reenabling Azure Synapse Link in the restored container. Check the analytical store documentation for more information.
Synapse Link for database accounts using continuous backup mode is GA. Continuous backup mode for Synapse Link enabled accounts is in public preview. Currently, customers that disabled Synapse Link from containers can't migrate to continuous backup.
Granular role-based access control isn't supported when querying from Synapse. Users that have access to your Synapse workspace and have access to the Azure Cosmos DB account can access all containers within that account. We currently don't support more granular access to the containers.
Currently Azure Synapse Workspaces don't support linked services using
Managed Identity. Always use theMasterKeyoption.Currently Multi-regions write accounts aren't recommended for production environments.
Security
Azure Synapse Link enables you to run near real-time analytics over your mission-critical data in Azure Cosmos DB. It's vital to make sure that critical business data is stored securely across both transactional and analytical stores. Azure Synapse Link for Azure Cosmos DB is designed to help meet these security requirements through the following features:
Network isolation using private endpoints - You can control network access to the data in the transactional and analytical stores independently. Network isolation is done using separate managed private endpoints for each store, within managed virtual networks in Azure Synapse workspaces. To learn more, see how to Configure private endpoints for analytical store article.
Data encryption with customer-managed keys - You can seamlessly encrypt the data across transactional and analytical stores using the same customer-managed keys in an automatic and transparent manner. Azure Synapse Link only supports configuring customer-managed keys using your Azure Cosmos DB account's managed identity. You must configure your account's managed identity in your Azure Key Vault access policy before enabling Azure Synapse Link on your account. To learn more, see how to Configure customer-managed keys using Azure Cosmos DB accounts' managed identities article.
Secure key management - Accessing the data in analytical store from Synapse Spark and Synapse serverless SQL pools requires managing Azure Cosmos DB keys within Synapse Analytics workspaces. Instead of using the Azure Cosmos DB account keys inline in Spark jobs or SQL scripts, Azure Synapse Link provides more secure capabilities:
When using Synapse serverless SQL pools, you can query the Azure Cosmos DB analytical store by pre-creating SQL credentials storing the account keys and referencing these keys in the
OPENROWSETfunction. To learn more, see Query with a serverless SQL pool in Azure Synapse Link article.When using Synapse Spark, you can store the account keys in linked service objects pointing to an Azure Cosmos DB database and reference the keys in the Spark configuration at runtime. To learn more, see Copy data into a dedicated SQL pool using Apache Spark article.
Pricing
The billing model of Azure Synapse Link includes the costs incurred by using the Azure Cosmos DB analytical store and the Synapse runtime. To learn more, see the Azure Cosmos DB analytical store pricing and Azure Synapse Analytics pricing articles.
Next steps
To learn more, see the following docs:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for