Transform data by running a Python activity in Azure Databricks
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
The Azure Databricks Python Activity in a pipeline runs a Python file in your Azure Databricks cluster. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities. Azure Databricks is a managed platform for running Apache Spark.
For an eleven-minute introduction and demonstration of this feature, watch the following video:
Add a Python activity for Azure Databricks to a pipeline with UI
To use a Python activity for Azure Databricks in a pipeline, complete the following steps:
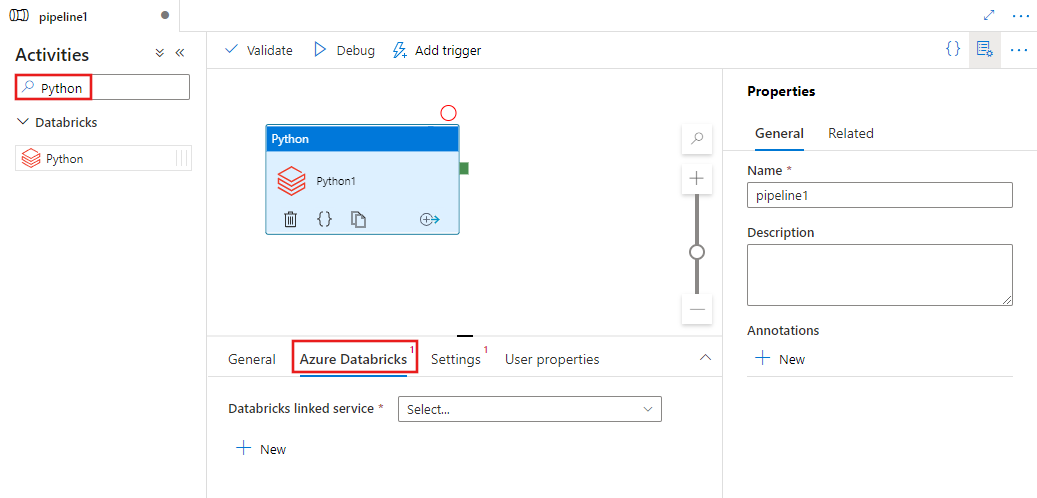
Search for Python in the pipeline Activities pane, and drag a Python activity to the pipeline canvas.
Select the new Python activity on the canvas if it is not already selected.
Select the Azure Databricks tab to select or create a new Azure Databricks linked service that will execute the Python activity.
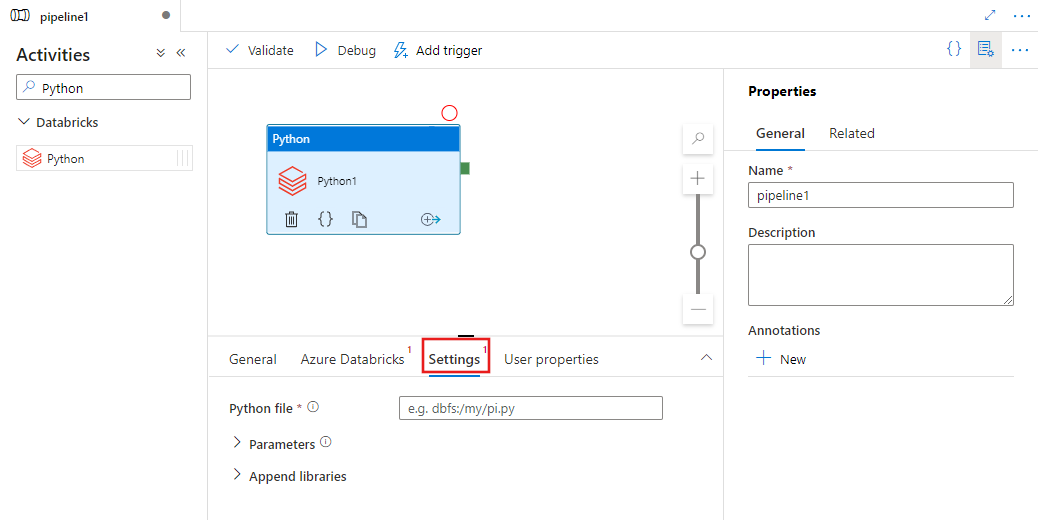
Select the Settings tab and specify the path within Azure Databricks to a Python file to be executed, optional parameters to be passed, and any additional libraries to be installed on the cluster to execute the job.
Databricks Python activity definition
Here is the sample JSON definition of a Databricks Python Activity:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Databricks Python activity properties
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Databricks Python Activity, the activity type is DatabricksSparkPython. | Yes |
| linkedServiceName | Name of the Databricks Linked Service on which the Python activity runs. To learn about this linked service, see Compute linked services article. | Yes |
| pythonFile | The URI of the Python file to be executed. Only DBFS paths are supported. | Yes |
| parameters | Command line parameters that will be passed to the Python file. This is an array of strings. | No |
| libraries | A list of libraries to be installed on the cluster that will execute the job. It can be an array of <string, object> | No |
Supported libraries for databricks activities
In the above Databricks activity definition you specify these library types: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
For more details refer Databricks documentation for library types.
How to upload a library in Databricks
You can use the Workspace UI:
To obtain the dbfs path of the library added using UI, you can use Databricks CLI.
Typically the Jar libraries are stored under dbfs:/FileStore/jars while using the UI. You can list all through the CLI: databricks fs ls dbfs:/FileStore/job-jars
Or you can use the Databricks CLI:
Use Databricks CLI (installation steps)
As an example, to copy a JAR to dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for