AI and Machine Learning on Databricks
This article describes the tools that Azure Databricks provides to help you build and monitor AI and ML workflows. The diagram shows how these components work together to help you implement your model development and deployment process.
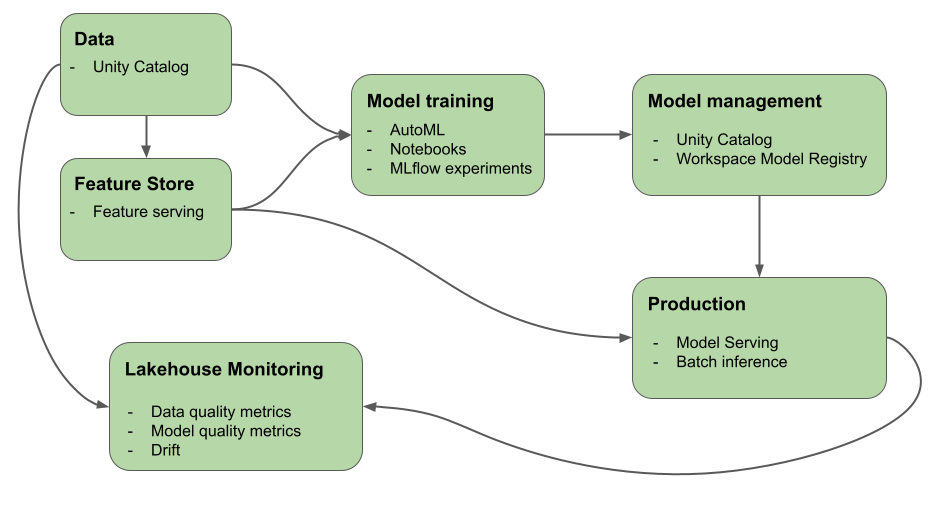
Why use Databricks for machine learning and deep learning?
With Azure Databricks, you can implement the full ML lifecycle on a single platform with end-to-end governance throughout the ML pipeline. Azure Databricks includes the following built-in tools to support ML workflows:
- Unity Catalog for governance, discovery, versioning, and access control for data, features, models, and functions.
- Lakehouse Monitoring for data monitoring.
- Feature engineering and serving.
- Support for the model lifecycle:
- Databricks AutoML for automated model training.
- MLflow for model development tracking.
- Unity Catalog for model management.
- Databricks Model Serving for high-availability, low-latency model serving. This includes deploying LLMs using:
- Foundation Model APIs which allow you to access and query state-of-the-art open models from a serving endpoint.
- External models which allow you to access models hosted outside of Databricks.
- Lakehouse Monitoring to track model prediction quality and drift.
- Databricks Workflows for automated workflows and production-ready ETL pipelines.
- Databricks Git folders for code management and Git integration.
Deep learning on Databricks
Configuring infrastructure for deep learning applications can be difficult.
Databricks Runtime for Machine Learning takes care of that for you, with clusters that have built-in compatible versions of the most common deep learning libraries like TensorFlow, PyTorch, and Keras, and supporting libraries such as Petastorm, Hyperopt, and Horovod. Databricks Runtime ML clusters also include pre-configured GPU support with drivers and supporting libraries. It also supports libraries like Ray to parallelize compute processing for scaling ML workflows and AI applications.
Databricks Runtime ML clusters also include pre-configured GPU support with drivers and supporting libraries. Databricks Model Serving enables creation of scalable GPU endpoints for deep learning models with no extra configuration.
For machine learning applications, Databricks recommends using a cluster running Databricks Runtime for Machine Learning. See Create a cluster using Databricks Runtime ML.
To get started with deep learning on Databricks, see:
- Best practices for deep learning on Azure Databricks
- Deep learning on Databricks
- Reference solutions for deep learning
Large language models (LLMs) and generative AI on Databricks
Databricks Runtime for Machine Learning includes libraries like Hugging Face Transformers and LangChain that allow you to integrate existing pre-trained models or other open-source libraries into your workflow. The Databricks MLflow integration makes it easy to use the MLflow tracking service with transformer pipelines, models, and processing components. In addition, you can integrate OpenAI models or solutions from partners like John Snow Labs in your Azure Databricks workflows.
With Azure Databricks, you can customize a LLM on your data for your specific task. With the support of open source tooling, such as Hugging Face and DeepSpeed, you can efficiently take a foundation LLM and train it with your own data to improve its accuracy for your specific domain and workload. You can then leverage the custom LLM in your generative AI applications.
In addition, Databricks provides Foundation Model APIs and external models which allows you to access and query state-of-the-art open models from a serving endpoint. Using Foundation Model APIs, developers can quickly and easily build applications that leverage a high-quality generative AI model without maintaining their own model deployment.
For SQL users, Databricks provides AI functions that SQL data analysts can use to access LLM models, including from OpenAI, directly within their data pipelines and workflows. See AI Functions on Azure Databricks.
Databricks Runtime for Machine Learning
Databricks Runtime for Machine Learning (Databricks Runtime ML) automates the creation of a cluster with pre-built machine learning and deep learning infrastructure including the most common ML and DL libraries. For the full list of libraries in each version of Databricks Runtime ML, see the release notes.
To access data in Unity Catalog for machine learning workflows, the access mode for the cluster must be single user (assigned). Shared clusters are not compatible with Databricks Runtime for Machine Learning. In addition, Databricks Runtime ML is not supported on TableACLs clusters or clusters with spark.databricks.pyspark.enableProcessIsolation config set to true.
Create a cluster using Databricks Runtime ML
When you create a cluster, select a Databricks Runtime ML version from the Databricks runtime version drop-down menu. Both CPU and GPU-enabled ML runtimes are available.
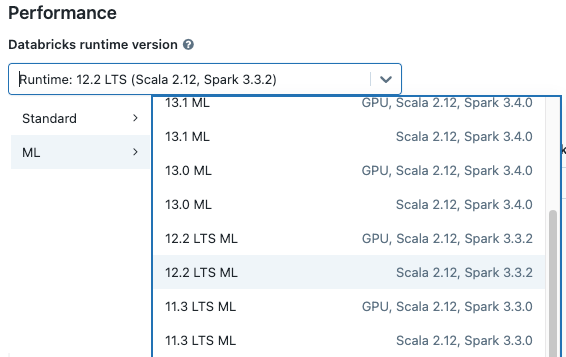
If you select a cluster from the drop-down menu in the notebook, the Databricks Runtime version appears at the right of the cluster name:
If you select a GPU-enabled ML runtime, you are prompted to select a compatible Driver type and Worker type. Incompatible instance types are grayed out in the drop-down menu. GPU-enabled instance types are listed under the GPU accelerated label.
Note
To access data in Unity Catalog for machine learning workflows, the access mode for the cluster must be single user (assigned). Shared clusters are not compatible with Databricks Runtime for Machine Learning.
Libraries included in Databricks Runtime ML
Databricks Runtime ML includes a variety of popular ML libraries. The libraries are updated with each release to include new features and fixes.
Databricks has designated a subset of the supported libraries as top-tier libraries. For these libraries, Databricks provides a faster update cadence, updating to the latest package releases with each runtime release (barring dependency conflicts). Databricks also provides advanced support, testing, and embedded optimizations for top-tier libraries.
For a full list of top-tier and other provided libraries, see the release notes for Databricks Runtime ML.
Next steps
To get started, see:
For a recommended MLOps workflow on Databricks Machine Learning, see:
To learn about key Databricks Machine Learning features, see:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for