Define variables
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
Variables give you a convenient way to get key bits of data into various parts of the pipeline. The most common use of variables is to define a value that you can then use in your pipeline. All variables are strings and are mutable. The value of a variable can change from run to run or job to job of your pipeline.
When you define the same variable in multiple places with the same name, the most locally scoped variable wins. So, a variable defined at the job level can override a variable set at the stage level. A variable defined at the stage level overrides a variable set at the pipeline root level. A variable set in the pipeline root level overrides a variable set in the Pipeline settings UI. To learn more how to work with variables defined at the job, stage, and root level, see Variable scope.
You can use variables with expressions to conditionally assign values and further customize pipelines.
Variables are different from runtime parameters. Runtime parameters are typed and available during template parsing.
User-defined variables
When you define a variable, you can use different syntaxes (macro, template expression, or runtime) and what syntax you use determines where in the pipeline your variable renders.
In YAML pipelines, you can set variables at the root, stage, and job level. You can also specify variables outside of a YAML pipeline in the UI. When you set a variable in the UI, that variable can be encrypted and set as secret.
User-defined variables can be set as read-only. There are naming restrictions for variables (example: you can't use secret at the start of a variable name).
You can use a variable group to make variables available across multiple pipelines.
Use templates to define variables in one file that are used in multiple pipelines.
User-defined multi-line variables
Azure DevOps supports multi-line variables but there are a few limitations.
Downstream components such as pipeline tasks might not handle the variable values correctly.
Azure DevOps won't alter user-defined variable values. Variable values need to be formatted correctly before being passed as multi-line variables. When formatting your variable, avoid special characters, don't use restricted names, and make sure you use a line ending format that works for the operating system of your agent.
Multi-line variables behave differently depending on the operating system. To avoid this, make sure that you format multi-line variables correctly for the target operating system.
Azure DevOps never alters variable values, even if you provide unsupported formatting.
System variables
In addition to user-defined variables, Azure Pipelines has system variables with predefined values. For example, the predefined variable Build.BuildId gives the ID of each build and can be used to identify different pipeline runs. You can use the Build.BuildId variable in scripts or tasks when you need to a unique value.
If you're using YAML or classic build pipelines, see predefined variables for a comprehensive list of system variables.
If you're using classic release pipelines, see release variables.
System variables get set with their current value when you run the pipeline. Some variables are set automatically. As a pipeline author or end user, you change the value of a system variable before the pipeline runs.
System variables are read-only.
Environment variables
Environment variables are specific to the operating system you're using. They're injected into a pipeline in platform-specific ways. The format corresponds to how environment variables get formatted for your specific scripting platform.
On UNIX systems (macOS and Linux), environment variables have the format $NAME. On Windows, the format is %NAME% for batch and $env:NAME in PowerShell.
System and user-defined variables also get injected as environment variables for your platform. When variables convert into environment variables, variable names become uppercase, and periods turn into underscores. For example, the variable name any.variable becomes the variable name $ANY_VARIABLE.
There are variable naming restrictions for environment variables (example: you can't use secret at the start of a variable name).
Variable naming restrictions
User-defined and environment variables can consist of letters, numbers, ., and _ characters. Don't use variable prefixes reserved by the system. These are: endpoint, input, secret, path, and securefile. Any variable that begins with one of these strings (regardless of capitalization) won't be available to your tasks and scripts.
Understand variable syntax
Azure Pipelines supports three different ways to reference variables: macro, template expression, and runtime expression. You can use each syntax for a different purpose and each have some limitations.
In a pipeline, template expression variables (${{ variables.var }}) get processed at compile time, before runtime starts. Macro syntax variables ($(var)) get processed during runtime before a task runs. Runtime expressions ($[variables.var]) also get processed during runtime but are intended to be used with conditions and expressions. When you use a runtime expression, it must take up the entire right side of a definition.
In this example, you can see that the template expression still has the initial value of the variable after the variable is updated. The value of the macro syntax variable updates. The template expression value doesn't change because all template expression variables get processed at compile time before tasks run. In contrast, macro syntax variables evaluate before each task runs.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Macro syntax variables
Most documentation examples use macro syntax ($(var)). Macro syntax is designed to interpolate variable values into task inputs and into other variables.
Variables with macro syntax get processed before a task executes during runtime. Runtime happens after template expansion. When the system encounters a macro expression, it replaces the expression with the contents of the variable. If there's no variable by that name, then the macro expression doesn't change. For example, if $(var) can't be replaced, $(var) won't be replaced by anything.
Macro syntax variables remain unchanged with no value because an empty value like $() might mean something to the task you're running and the agent shouldn't assume you want that value replaced. For example, if you use $(foo) to reference variable foo in a Bash task, replacing all $() expressions in the input to the task could break your Bash scripts.
Macro variables are only expanded when they're used for a value, not as a keyword. Values appear on the right side of a pipeline definition. The following is valid: key: $(value). The following isn't valid: $(key): value. Macro variables aren't expanded when used to display a job name inline. Instead, you must use the displayName property.
Note
Macro syntax variables are only expanded for stages, jobs, and steps.
You cannot, for example, use macro syntax inside a resource or trigger.
This example uses macro syntax with Bash, PowerShell, and a script task. The syntax for calling a variable with macro syntax is the same for all three.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Template expression syntax
You can use template expression syntax to expand both template parameters and variables (${{ variables.var }}). Template variables process at compile time, and get replaced before runtime starts. Template expressions are designed for reusing parts of YAML as templates.
Template variables silently coalesce to empty strings when a replacement value isn't found. Template expressions, unlike macro and runtime expressions, can appear as either keys (left side) or values (right side). The following is valid: ${{ variables.key }} : ${{ variables.value }}.
Runtime expression syntax
You can use runtime expression syntax for variables that are expanded at runtime ($[variables.var]). Runtime expression variables silently coalesce to empty strings when a replacement value isn't found. Use runtime expressions in job conditions, to support conditional execution of jobs, or whole stages.
Runtime expression variables are only expanded when they're used for a value, not as a keyword. Values appear on the right side of a pipeline definition. The following is valid: key: $[variables.value]. The following isn't valid: $[variables.key]: value. The runtime expression must take up the entire right side of a key-value pair. For example, key: $[variables.value] is valid but key: $[variables.value] foo isn't.
| Syntax | Example | When is it processed? | Where does it expand in a pipeline definition? | How does it render when not found? |
|---|---|---|---|---|
| macro | $(var) |
runtime before a task executes | value (right side) | prints $(var) |
| template expression | ${{ variables.var }} |
compile time | key or value (left or right side) | empty string |
| runtime expression | $[variables.var] |
runtime | value (right side) | empty string |
What syntax should I use?
Use macro syntax if you're providing input for a task.
Choose a runtime expression if you're working with conditions and expressions. However, don't use a runtime expression if you don't want your empty variable to print (example: $[variables.var]). For example, if you have conditional logic that relies on a variable having a specific value or no value. In that case, you should use a macro expression.
If you're defining a variable in a template, use a template expression.
Set variables in pipeline
In the most common case, you set the variables and use them within the YAML file. This allows you to track changes to the variable in your version control system. You can also define variables in the pipeline settings UI (see the Classic tab) and reference them in your YAML.
Here's an example that shows how to set two variables, configuration and platform, and use them later in steps. To use a variable in a YAML statement, wrap it in $(). Variables can't be used to define a repository in a YAML statement.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Variable scopes
In the YAML file, you can set a variable at various scopes:
- At the root level, to make it available to all jobs in the pipeline.
- At the stage level, to make it available only to a specific stage.
- At the job level, to make it available only to a specific job.
When you define a variable at the top of a YAML, the variable is available to all jobs and stages in the pipeline and is a global variable. Global variables defined in a YAML aren't visible in the pipeline settings UI.
Variables at the job level override variables at the root and stage level. Variables at the stage level override variables at the root level.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
The output from both jobs looks like this:
# job1
value
value1
value1
# job2
value
value2
value
Specify variables
In the preceding examples, the variables keyword is followed by a list of key-value pairs.
The keys are the variable names and the values are the variable values.
There's another syntax, useful when you want to use templates for variables or variable groups.
With templates, variables can be defined in one YAML and included in another YAML file.
Variable groups are a set of variables that you can use across multiple pipelines. They allow you to manage and organize variables that are common to various stages in one place.
Use this syntax for variable templates and variable groups at the root level of a pipeline.
In this alternate syntax, the variables keyword takes a list of variable specifiers.
The variable specifiers are name for a regular variable, group for a variable group, and template to include a variable template.
The following example demonstrates all three.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Learn more about variable reuse with templates.
Access variables through the environment
Notice that variables are also made available to scripts through environment variables. The syntax for using these environment variables depends on the scripting language.
The name is upper-cased, and the . is replaced with the _. This is automatically inserted into the process environment. Here are some examples:
- Batch script:
%VARIABLE_NAME% - PowerShell script:
$env:VARIABLE_NAME - Bash script:
$VARIABLE_NAME
Important
Predefined variables that contain file paths are translated to the appropriate styling (Windows style C:\foo\ versus Unix style /foo/) based on agent host type and shell type. If you are running bash script tasks on Windows, you should use the environment variable method for accessing these variables rather than the pipeline variable method to ensure you have the correct file path styling.
Set secret variables
Don't set secret variables in your YAML file. Operating systems often log commands for the processes that they run, and you wouldn't want the log to include a secret that you passed in as an input. Use the script's environment or map the variable within the variables block to pass secrets to your pipeline.
Note
Azure Pipelines makes an effort to mask secrets when emitting data to pipeline logs, so you may see additional variables and data masked in output and logs that are not set as secrets.
You need to set secret variables in the pipeline settings UI for your pipeline. These variables are scoped to the pipeline where they're set. You can also set secret variables in variable groups.
To set secrets in the web interface, follow these steps:
- Go to the Pipelines page, select the appropriate pipeline, and then select Edit.
- Locate the Variables for this pipeline.
- Add or update the variable.
- Select the option to Keep this value secret to store the variable in an encrypted manner.
- Save the pipeline.
Secret variables are encrypted at rest with a 2048-bit RSA key. Secrets are available on the agent for tasks and scripts to use. Be careful about who has access to alter your pipeline.
Important
We make an effort to mask secrets from appearing in Azure Pipelines output, but you still need to take precautions. Never echo secrets as output. Some operating systems log command line arguments. Never pass secrets on the command line. Instead, we suggest that you map your secrets into environment variables.
We never mask substrings of secrets. If, for example, "abc123" is set as a secret, "abc" isn't masked from the logs. This is to avoid masking secrets at too granular of a level, making the logs unreadable. For this reason, secrets should not contain structured data. If, for example, "{ "foo": "bar" }" is set as a secret, "bar" isn't masked from the logs.
Unlike a normal variable, they are not automatically decrypted into environment variables for scripts. You need to explicitly map secret variables.
The following example shows how to map and use a secret variable called mySecret in PowerShell and Bash scripts. Two global variables are defined. GLOBAL_MYSECRET is assigned the value of a secret variable mySecret, and GLOBAL_MY_MAPPED_ENV_VAR is assigned the value of a non-secret variable nonSecretVariable. Unlike a normal pipeline variable, there's no environment variable called MYSECRET.
The PowerShell task runs a script to print the variables.
$(mySecret): This is a direct reference to the secret variable and works.$env:MYSECRET: This attempts to access the secret variable as an environment variable, which does not work because secret variables are not automatically mapped to environment variables.$env:GLOBAL_MYSECRET: This attempts to access the secret variable through a global variable, which also does not work because secret variables cannot be mapped this way.$env:GLOBAL_MY_MAPPED_ENV_VAR: This accesses the non-secret variable through a global variable, which works.$env:MY_MAPPED_ENV_VAR: This accesses the secret variable through a task-specific environment variable, which is the recommended way to map secret variables to environment variables.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
The output from both tasks in the preceding script would look like this:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
You can also use secret variables outside of scripts. For example, you can map secret variables to tasks using the variables definition. This example shows how to use secret variables $(vmsUser) and $(vmsAdminPass) in an Azure file copy task.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Reference secret variables in variable groups
This example shows how to reference a variable group in your YAML file, and also how to add variables within the YAML. There are two variables used from the variable group: user and token. The token variable is secret, and is mapped to the environment variable $env:MY_MAPPED_TOKEN so that it can be referenced in the YAML.
This YAML makes a REST call to retrieve a list of releases, and outputs the result.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Important
By default with GitHub repositories, secret variables associated with your pipeline aren't made available to pull request builds of forks. For more information, see Contributions from forks.
Share variables across pipelines
To share variables across multiple pipelines in your project, use the web interface. Under Library, use variable groups.
Use output variables from tasks
Some tasks define output variables, which you can consume in downstream steps, jobs, and stages. In YAML, you can access variables across jobs and stages by using dependencies.
When referencing matrix jobs in downstream tasks, you'll need to use a different syntax. See Set a multi-job output variable. You also need to use a different syntax for variables in deployment jobs. See Support for output variables in deployment jobs.
Some tasks define output variables, which you can consume in downstream steps and jobs within the same stage. In YAML, you can access variables across jobs by using dependencies.
- To reference a variable from a different task within the same job, use
TASK.VARIABLE. - To reference a variable from a task from a different job, use
dependencies.JOB.outputs['TASK.VARIABLE'].
Note
By default, each stage in a pipeline depends on the one just before it in the YAML file. If you need to refer to a stage that isn't immediately prior to the current one, you can override this automatic default by adding a dependsOn section to the stage.
Note
The following examples use standard pipeline syntax. If you're using deployment pipelines, both variable and conditional variable syntax will differ. For information about the specific syntax to use, see Deployment jobs.
For these examples, assume we have a task called MyTask, which sets an output variable called MyVar.
Learn more about the syntax in Expressions - Dependencies.
Use outputs in the same job
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Use outputs in a different job
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Use outputs in a different stage
To use the output from a different stage, the format for referencing variables is stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. At the stage level, but not the job level, you can use these variables in conditions.
Output variables are only available in the next downstream stage. If multiple stages consume the same output variable, use the dependsOn condition.
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
You can also pass variables between stages with a file input. To do so, you'll need to define variables in the second stage at the job level, and then pass the variables as env: inputs.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
The output from stages in the preceding pipeline looks like this:
Hello inline version
true
crushed tomatoes
List variables
You can list all of the variables in your pipeline with the az pipelines variable list command. To get started, see Get started with Azure DevOps CLI.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parameters
- org: Azure DevOps organization URL. You can configure the default organization using
az devops configure -d organization=ORG_URL. Required if not configured as default or picked up usinggit config. Example:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: Required if pipeline-name isn't supplied. ID of the pipeline.
- pipeline-name: Required if pipeline-id isn't supplied, but ignored if pipeline-id is supplied. Name of the pipeline.
- project: Name or ID of the project. You can configure the default project using
az devops configure -d project=NAME_OR_ID. Required if not configured as default or picked up by usinggit config.
Example
The following command lists all of the variables in the pipeline with ID 12 and shows the result in table format.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Set variables in scripts
Scripts can define variables that are later consumed in subsequent steps in the pipeline. All variables set by this method are treated as strings. To set a variable from a script, you use a command syntax and print to stdout.
Set a job-scoped variable from a script
To set a variable from a script, you use the task.setvariable logging command. This updates the environment variables for subsequent jobs. Subsequent jobs have access to the new variable with macro syntax and in tasks as environment variables.
When issecret is true, the value of the variable will be saved as secret and masked from the log. For more information on secret variables, see logging commands.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
Subsequent steps will also have the pipeline variable added to their environment. You can't use the variable in the step that it's defined.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
The output from the preceding pipeline.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Set a multi-job output variable
If you want to make a variable available to future jobs, you must mark it as
an output variable by using isOutput=true. Then you can map it into future jobs by using the $[] syntax and including the step name that set the variable. Multi-job output variables only work for jobs in the same stage.
To pass variables to jobs in different stages, use the stage dependencies syntax.
Note
By default, each stage in a pipeline depends on the one just before it in the YAML file. Therefore, each stage can use output variables from the prior stage. To access further stages, you will need to alter the dependency graph, for instance, if stage 3 requires a variable from stage 1, you will need to declare an explicit dependency on stage 1.
When you create a multi-job output variable, you should assign the expression to a variable. In this YAML, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] is assigned to the variable $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
The output from the preceding pipeline.
this is the value
this is the value
If you're setting a variable from one stage to another, use stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
If you're setting a variable from a matrix or slice, then to reference the variable when you access it from a downstream job, you must include:
- The name of the job.
- The step.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Be sure to prefix the job name to the output variables of a deployment job. In this case, the job name is A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Set the
Set the  Set the
Set the  Set the
Set the Set variables by using expressions
You can set a variable by using an expression. We already encountered one case of this to set a variable to the output of another from a previous job.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
You can use any of the supported expressions for setting a variable. Here's an example of setting a variable to act as a counter that starts at 100, gets incremented by 1 for every run, and gets reset to 100 every day.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
For more information about counters, dependencies, and other expressions, see expressions.
Configure settable variables for steps
You can define settableVariables within a step or specify that no variables can be set.
In this example, the script can't set a variable.
steps:
- script: echo This is a step
target:
settableVariables: none
In this example, the script allows the variable sauce but not the variable secretSauce. You'll see a warning on the pipeline run page.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Allow at queue time
If a variable appears in the variables block of a YAML file, its value is fixed and can't be overridden at queue time. Best practice is to define your variables in a YAML file but there are times when this doesn't make sense. For example, you might want to define a secret variable and not have the variable exposed in your YAML. Or, you might need to manually set a variable value during the pipeline run.
You have two options for defining queue-time values. You can define a variable in the UI and select the option to Let users override this value when running this pipeline or you can use runtime parameters instead. If your variable isn't a secret, the best practice is to use runtime parameters.
To set a variable at queue time, add a new variable within your pipeline and select the override option.
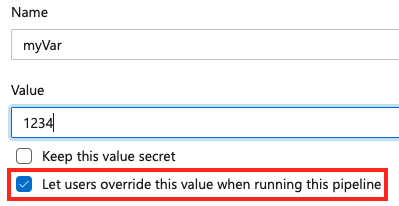
To allow a variable to be set at queue time, make sure the variable doesn't also appear in the variables block of a pipeline or job. If you define a variable in both the variables block of a YAML and in the UI, the value in the YAML has priority.

Expansion of variables
When you set a variable with the same name in multiple scopes, the following precedence applies (highest precedence first).
- Job level variable set in the YAML file
- Stage level variable set in the YAML file
- Pipeline level variable set in the YAML file
- Variable set at queue time
- Pipeline variable set in Pipeline settings UI
In the following example, the same variable a is set at the pipeline level and job level in YAML file. It's also set in a variable group G, and as a variable in the Pipeline settings UI.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
When you set a variable with the same name in the same scope, the last set value takes precedence.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Note
When you set a variable in the YAML file, don't define it in the web editor as settable at queue time. You can't currently change variables that are set in the YAML file at queue time. If you need a variable to be settable at queue time, don't set it in the YAML file.
Variables are expanded once when the run is started, and again at the beginning of each step. For example:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
There are two steps in the preceding example. The expansion of $(a) happens once at the beginning of the job, and once at the beginning of each of the two steps.
Because variables are expanded at the beginning of a job, you can't use them in a strategy. In the following example, you can't use the variable a to expand the job matrix, because the variable is only available at the beginning of each expanded job.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
If the variable a is an output variable from a previous job, then you can use it in a future job.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Recursive expansion
On the agent, variables referenced using $( ) syntax are recursively expanded.
For example:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"
Related articles
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for