Azure Event Hubs – A real-time data streaming platform with native Apache Kafka support
Azure Event Hubs is a cloud native data streaming service that can stream millions of events per second, with low latency, from any source to any destination. Event Hubs is compatible with Apache Kafka, and it enables you to run existing Kafka workloads without any code changes.
Using Event Hubs to ingest and store streaming data, businesses can harness the power of streaming data to gain valuable insights, drive real-time analytics, and respond to events as they happen, enhancing overall efficiency and customer experience.

Azure Event Hubs is the preferred event ingestion layer of any event streaming solution that you build on top of Azure. It seamlessly integrates with data and analytics services inside and outside Azure to build your complete data streaming pipeline to serve following use cases.
- Real-time analytics with Azure Stream Analytics to generate real-time insights from streaming data.
- Analyze and explore streaming data with Azure Data Explorer.
- Create your own cloud native applications, functions, or microservices that run on streaming data from Event Hubs.
- Stream events with schema validation using a built-in schema registry to ensure quality and compatibility of streaming data.
Key capabilities
Apache Kafka on Azure Event Hubs
Azure Event Hubs is a multi-protocol event streaming engine that natively supports AMQP, Apache Kafka, and HTTPs protocols. Since it supports Apache Kafka, you bring Kafka workloads to Azure Event Hubs without doing any code change. You don't need to set up, configure, and manage your own Kafka clusters or use a Kafka-as-a-Service offering that's not native to Azure.
Event Hubs is built from the ground up as a cloud native broker engine. Hence, you can run Kafka workloads with better performance, better cost efficiency and with no operational overhead.
For more information, see Azure Event Hubs for Apache Kafka.
Schema Registry in Azure Event Hubs
Azure Schema Registry in Event Hubs provides a centralized repository for managing schemas of events streaming applications. Azure Schema Registry comes free with every Event Hubs namespace, and it integrates seamlessly with your Kafka applications or Event Hubs SDK based applications.
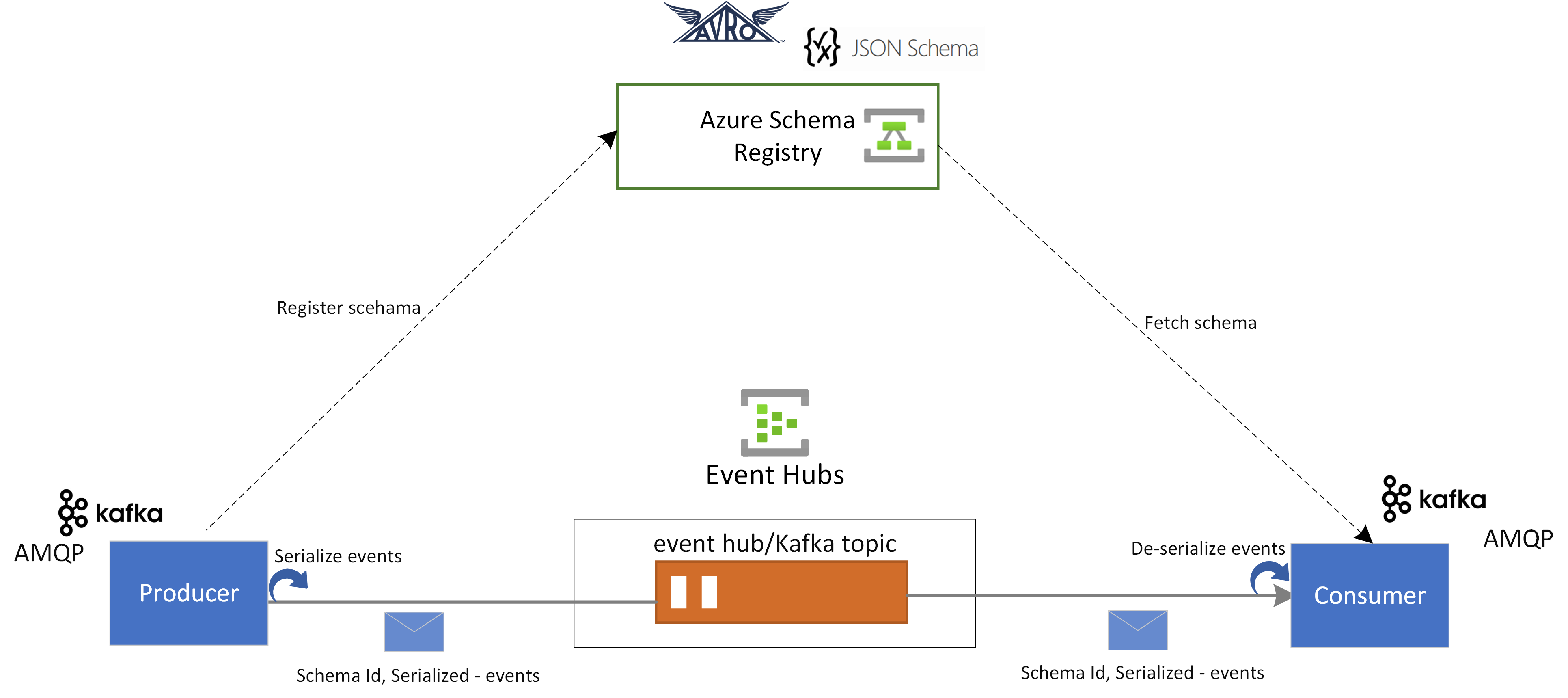
It ensures data compatibility and consistency across event producers and consumers. Schema Registry enables seamless schema evolution, validation, and governance, and promoting efficient data exchange and interoperability.
Schema Registry seamlessly integrates with your existing Kafka applications and it supports multiple schema formats including Avro and JSON Schemas.
For more information, see Azure Schema Registry in Event Hubs.
Real-time processing of streaming events with Azure Stream Analytics
Event Hubs integrates seamlessly with Azure Stream Analytics to enable real-time stream processing. With the built-in no-code editor, you can effortlessly develop a Stream Analytics job using drag-and-drop functionality, without writing any code.

Alternatively, developers can use the SQL-based Stream Analytics query language to perform real-time stream processing and take advantage of a wide range of functions for analyzing streaming data.
For more information, see articles in the Azure Stream Analytics integration section of the table of contents.
Exploring streaming data with Azure Data Explorer
Azure Data Explorer is a fully managed platform for big data analytics that delivers high performance and allows for the analysis of large volumes of data in near real time. By integrating Event Hubs with Azure Data Explorer, you can easily perform near real-time analytics and exploration of streaming data.
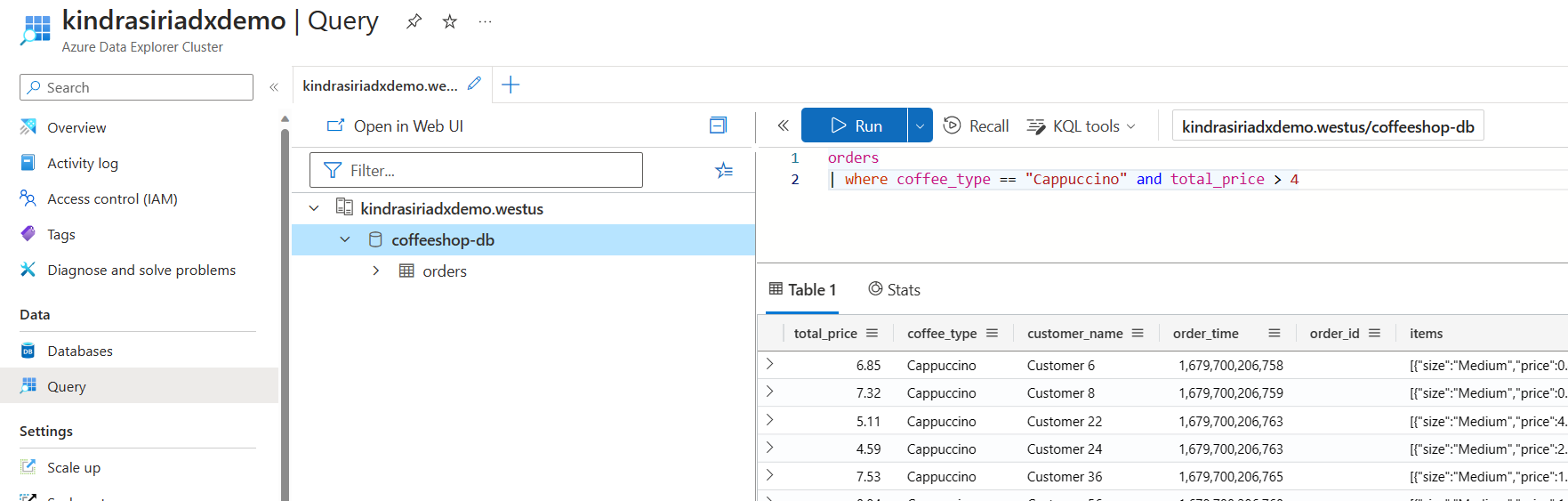
For more information, see Ingest data from an event hub into Azure Data Explorer and articles in the same section.
Rich ecosystem– Azure functions, SDKs, and Kafka ecosystem
Ingest, buffer, store, and process your stream in real time to get actionable insights. Event Hubs uses a partitioned consumer model, enabling multiple applications to process the stream concurrently and letting you control the speed of processing. Azure Event Hubs also integrates with Azure Functions for serverless architectures.
With a broad ecosystem available for the industry-standard AMQP 1.0 protocol and SDKs available in various languages: .NET, Java, Python, JavaScript, you can easily start processing your streams from Event Hubs. All supported client languages provide low-level integration.
The ecosystem also provides you with seamless integration Azure Functions, Azure Spring Apps, Kafka Connectors, and other data analytics platforms and technologies such as Apache Spark and Apache Flink.
Flexible and cost-efficient event streaming
You can experience flexible and cost-efficient event streaming through Event Hubs' diverse selection of tiers – including Standard, Premium, and Dedicated. These options cater to data streaming needs ranging from a few MB/s to several GB/s, allowing you to choose the perfect match for your requirements.
Scalable
With Event Hubs, you can start with data streams in megabytes, and grow to gigabytes or terabytes. The Auto inflate feature is one of the many options available to scale the number of throughput units or processing units to meet your usage needs.
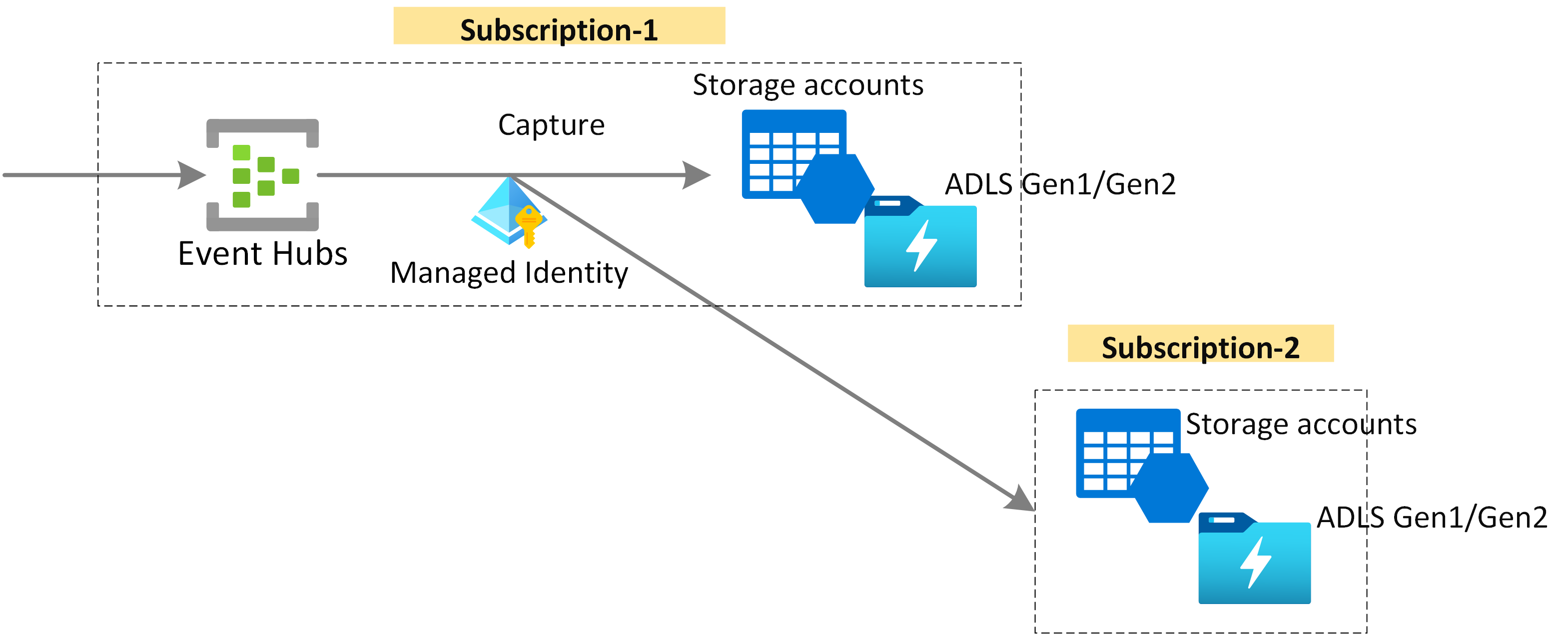
Capture streaming data for long term retention and batch analytics
Capture your data in near-real time in an Azure Blob storage or Azure Data Lake Storage for long-term retention or micro-batch processing. You can achieve this behavior on the same stream you use for deriving real-time analytics. Setting up capture of event data is fast.
How it works
Event Hubs provides a unified event streaming platform with time retention buffer, decoupling event producers from event consumers. The producers and consumer applications can perform large scale data ingestion through multiple protocols.
The following figure shows the key components of Event Hubs architecture:
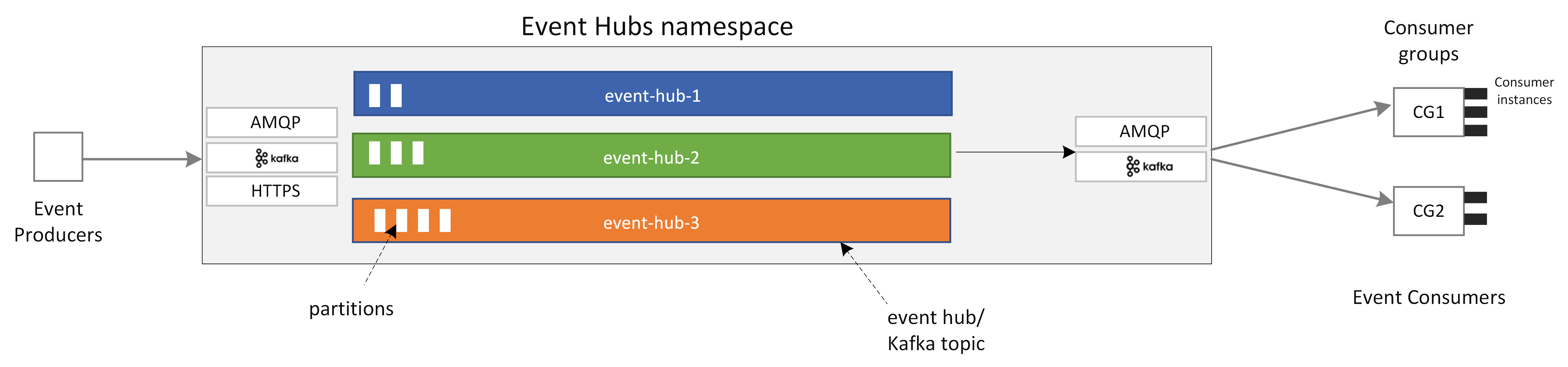
The key functional components of Event Hubs include:
- Producer applications can ingest data to an event hub using Event Hubs SDKs or any Kafka producer client.
- Namespace is the management container for one or more event hubs or Kafka topics. The management tasks such as allocating streaming capacity, configuring network security, enabling Geo Disaster recovery etc. are handled at the namespace level.
- Event Hub/Kafka topic: In Event Hubs, you can organize events into an event hub or a Kafka topic. It's an append only distributed log, which can comprise of one or more partitions.
- Partitions are used to scale an event hub. They are like lanes in a freeway. If you need more streaming throughput, you need to add more partitions.
- Consumer applications consume data by seeking through the event log and maintaining consumer offset. Consumers can be Kafka consumer clients or Event Hubs SDK clients.
- Consumer Group is a logical group of consumer instances that reads data from an event hub/Kafka topic. It enables multiple consumers to read the same streaming data in an event hub independently at their own pace and with their own offsets.
Next steps
To get started using Event Hubs, see the following quick start guides.
Stream data using Event Hubs SDK (AMQP)
You can use any of the following samples to stream data to Event Hubs using SDKs.
- .NET Core
- Java
- Spring
- Python
- JavaScript
- Go
- C (send only)
- Apache Storm (receive only)
Stream data using Apache Kafka
You can use following samples to stream data from your Kafka applications to Event Hubs.
Schema validation with Schema Registry
You can use Event Hubs Schema Registry to perform schema validation for your event streaming applications.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for