Optimize Apache Hive queries in Azure HDInsight
This article describes some of the most common performance optimizations that you can use to improve the performance of your Apache Hive queries.
Cluster type selection
In Azure HDInsight, you can run Apache Hive queries on a few different cluster types.
Choose the appropriate cluster type to help optimize performance for your workload needs:
- Choose Interactive Query cluster type to optimize for
ad hoc, interactive queries. - Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process.
- Spark and HBase cluster types can also run Hive queries, and might be appropriate if you're running those workloads.
For more information on running Hive queries on various HDInsight cluster types, see What is Apache Hive and HiveQL on Azure HDInsight?.
Scale out worker nodes
Increasing the number of worker nodes in an HDInsight cluster allows the work to use more mappers and reducers to be run in parallel. There are two ways you can increase out scale in HDInsight:
When you create a cluster, you can specify the number of worker nodes using the Azure portal, Azure PowerShell, or command-line interface. For more information, see Create HDInsight clusters. The following screenshot shows the worker node configuration on the Azure portal:

After creation, you can also edit the number of worker nodes to scale out a cluster further without recreating one:

For more information about scaling HDInsight, see Scale HDInsight clusters
Use Apache Tez instead of Map Reduce
Apache Tez is an alternative execution engine to the MapReduce engine. Linux-based HDInsight clusters have Tez enabled by default.
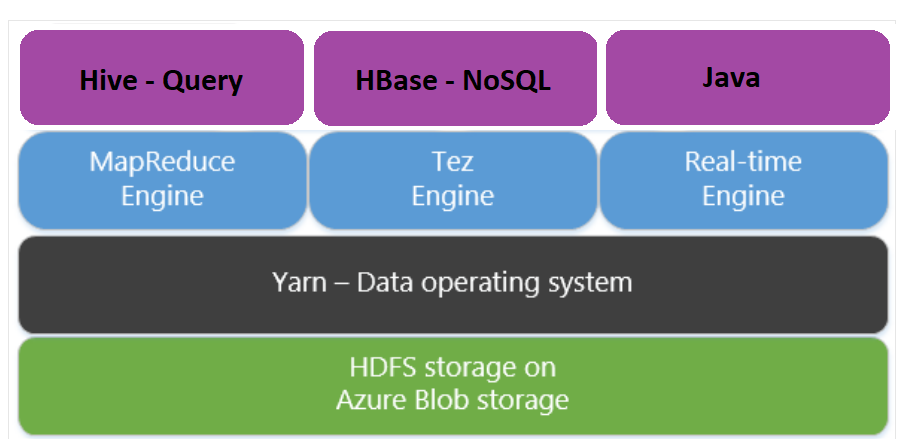
Tez is faster because:
- Execute Directed Acyclic Graph (DAG) as a single job in the MapReduce engine. The DAG requires each set of mappers to be followed by one set of reducers. This requirement causes multiple MapReduce jobs to be spun off for each Hive query. Tez doesn't have such constraint and can process complex DAG as one job minimizing job startup overhead.
- Avoids unnecessary writes. Multiple jobs are used to process the same Hive query in the MapReduce engine. The output of each MapReduce job is written to HDFS for intermediate data. Since Tez minimizes number of jobs for each Hive query, it's able to avoid unnecessary writes.
- Minimizes start-up delays. Tez is better able to minimize start-up delay by reducing the number of mappers it needs to start and also improving optimization throughout.
- Reuses containers. Whenever possible Tez reuse containers to ensure that latency from starting up containers is reduced.
- Continuous optimization techniques. Traditionally optimization was done during compilation phase. However more information about the inputs is available that allow for better optimization during runtime. Tez uses continuous optimization techniques that allow it to optimize the plan further into the runtime phase.
For more information on these concepts, see Apache TEZ.
You can make any Hive query Tez enabled by prefixing the query with the following set command:
set hive.execution.engine=tez;
Hive partitioning
I/O operations are the major performance bottleneck for running Hive queries. The performance can be improved if the amount of data that needs to be read can be reduced. By default, Hive queries scan entire Hive tables. However for queries that only need to scan a small amount of data (for example, queries with filtering), this behavior creates unnecessary overhead. Hive partitioning allows Hive queries to access only the necessary amount of data in Hive tables.
Hive partitioning is implemented by reorganizing the raw data into new directories. Each partition has its own file directory. The user defines the partitioning. The following diagram illustrates partitioning a Hive table by the column Year. A new directory is created for each year.
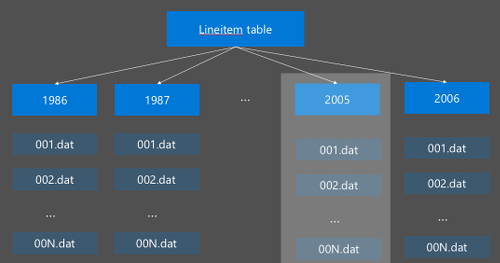
Some partitioning considerations:
- Don't under partition - Partitioning on columns with only a few values can cause few partitions. For example, partitioning on gender only creates two partitions to be created (male and female), so reduce the latency by a maximum of half.
- Don't over partition - On the other extreme, creating a partition on a column with a unique value (for example, userid) causes multiple partitions. Over partition causes much stress on the cluster namenode as it has to handle the large number of directories.
- Avoid data skew - Choose your partitioning key wisely so that all partitions are even size. For example, partitioning on State column may skew the distribution of data. Since the state of California has a population almost 30x that of Vermont, the partition size is potentially skewed, and performance may vary tremendously.
To create a partition table, use the Partitioned By clause:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Once the partitioned table is created, you can either create static partitioning or dynamic partitioning.
Static partitioning means that you have already sharded data in the appropriate directories. With static partitions, you add Hive partitions manually based on the directory location. The following code snippet is an example.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Dynamic partitioning means that you want Hive to create partitions automatically for you. Since you've already created the partitioning table from the staging table, all you need to do is insert data to the partitioned table:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
For more information, see Partitioned Tables.
Use the ORCFile format
Hive supports different file formats. For example:
- Text: the default file format and works with most scenarios.
- Avro: works well for interoperability scenarios.
- ORC/Parquet: best suited for performance.
ORC (Optimized Row Columnar) format is a highly efficient way to store Hive data. Compared to other formats, ORC has the following advantages:
- support for complex types including DateTime and complex and semi-structured types.
- up to 70% compression.
- indexes every 10,000 rows, which allow skipping rows.
- a significant drop in run-time execution.
To enable ORC format, you first create a table with the clause Stored as ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Next, you insert data to the ORC table from the staging table. For example:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
You can read more on the ORC format in the Apache Hive Language manual.
Vectorization
Vectorization allows Hive to process a batch of 1024 rows together instead of processing one row at a time. It means that simple operations are done faster because less internal code needs to run.
To enable vectorization prefix your Hive query with the following setting:
set hive.vectorized.execution.enabled = true;
For more information, see Vectorized query execution.
Other optimization methods
There are more optimization methods that you can consider, for example:
- Hive bucketing: a technique that allows to cluster or segment large sets of data to optimize query performance.
- Join optimization: optimization of Hive's query execution planning to improve the efficiency of joins and reduce the need for user hints. For more information, see Join optimization.
- Increase Reducers.
Next steps
In this article, you have learned several common Hive query optimization methods. To learn more, see the following articles:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for