How to use Apache Hive replication in Azure HDInsight clusters
In the context of databases and warehouses, replication is the process of duplicating entities from one warehouse to another. Duplication can apply to an entire database or to a smaller level, such as a table or partition. The objective is to have a replica that changes whenever the base entity changes. Replication on Apache Hive focuses on disaster recovery and offers unidirectional primary-copy replication. In HDInsight clusters, Hive Replication can be used to unidirectionally replicate the Hive metastore and the associated underlying data lake on Azure Data Lake Storage Gen2.
Hive Replication has evolved over the years with newer versions providing better functionality and being faster and less resource intensive. In this article, we discuss Hive Replication (Replv2) which is supported in both HDInsight 3.6 and HDInsight 4.0 cluster types.
Advantages of replv2
Hive ReplicationV2 (also called Replv2) has the following advantages over the first version of Hive replication that used Hive IMPORT-EXPORT:
- Event-based incremental replication
- Point-in-time replication
- Reduced bandwidth requirements
- Reduction in the number of intermediate copies
- Replication state is maintained
- Constrained replication
- Support for a Hub and Spoke model
- Support for ACID tables (in HDInsight 4.0)
Replication phases
Hive event-based replication is configured between the primary and secondary clusters. This replication consists of two distinct phases: bootstrapping and incremental runs.
Bootstrapping
Bootstrapping is intended to run once to replicate the base state of the databases from primary to secondary. You can configure bootstrapping, if needed, to include a subset of the tables in the targeted database where replication needs to be enabled.
Incremental runs
After bootstrapping, incremental runs are automated on the primary cluster and events generated during these incremental runs are played back on the secondary cluster. When the secondary cluster catches up with the primary cluster, the secondary becomes consistent with the primary's events.
Replication commands
Hive offers a set of REPL commands – DUMP, LOAD, and STATUS - to orchestrate the flow of events. The DUMP command generates a local log of all DDL/DML events on the primary cluster. The LOAD command is an approach to lazily copy metadata and data logged to the extracted replication dump output and is executed on the target cluster. The STATUS command runs from the target cluster to provide latest event ID that the most recent replication load was successfully replicated.
Set replication source
Before you start with replication, ensure the database that is to be replicated is set as the replication source. You could use the DESC DATABASE EXTENDED <db_name> command to determine if the parameter repl.source.for is set with the policy name.
If the policy is scheduled and the repl.source.for parameter isn't set, then you need to first set this parameter using ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Dump metadata to the data lake
The REPL DUMP [database name]. => location / event_id command is used in the bootstrap phase to dump relevant metadata to Azure Data Lake Storage Gen2. The event_id specifies the minimum event to which relevant metadata has been put in Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Example output:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Load data to the target cluster
The REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } command is used to load data into target cluster for both the bootstrap and the incremental phases of replication. The [database name] can be the same as the source or a different name on the target cluster. The [location] represents the location from the output of earlier REPL DUMP command. This means that the target cluster should be able to talk to the source cluster. The WITH clause was primarily added to prevent a restart of the target cluster, allowing replication.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Output the last replicated event ID
The REPL STATUS [database name] command is executed on target clusters and outputs the last replicated event_id. The command also enables users to know what state their target cluster is been replicated to. You can use the output of this command to construct the next REPL DUMP command for incremental replication.
repl status tpcds_orc;
Example output:
| last_repl_id |
|---|
| 2925 |
Dump relevant data and metadata to the data lake
The REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } command is used to dump relevant metadata and data to Azure Data Lake Storage. This command is used in the incremental phase and is run on the source warehouse. The FROM [event-id] is required for the incremental phase, and the value of event-id can be derived by running the REPL STATUS [database name] command on the target warehouse.
repl dump tpcds_orc from 2925;
Example output:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
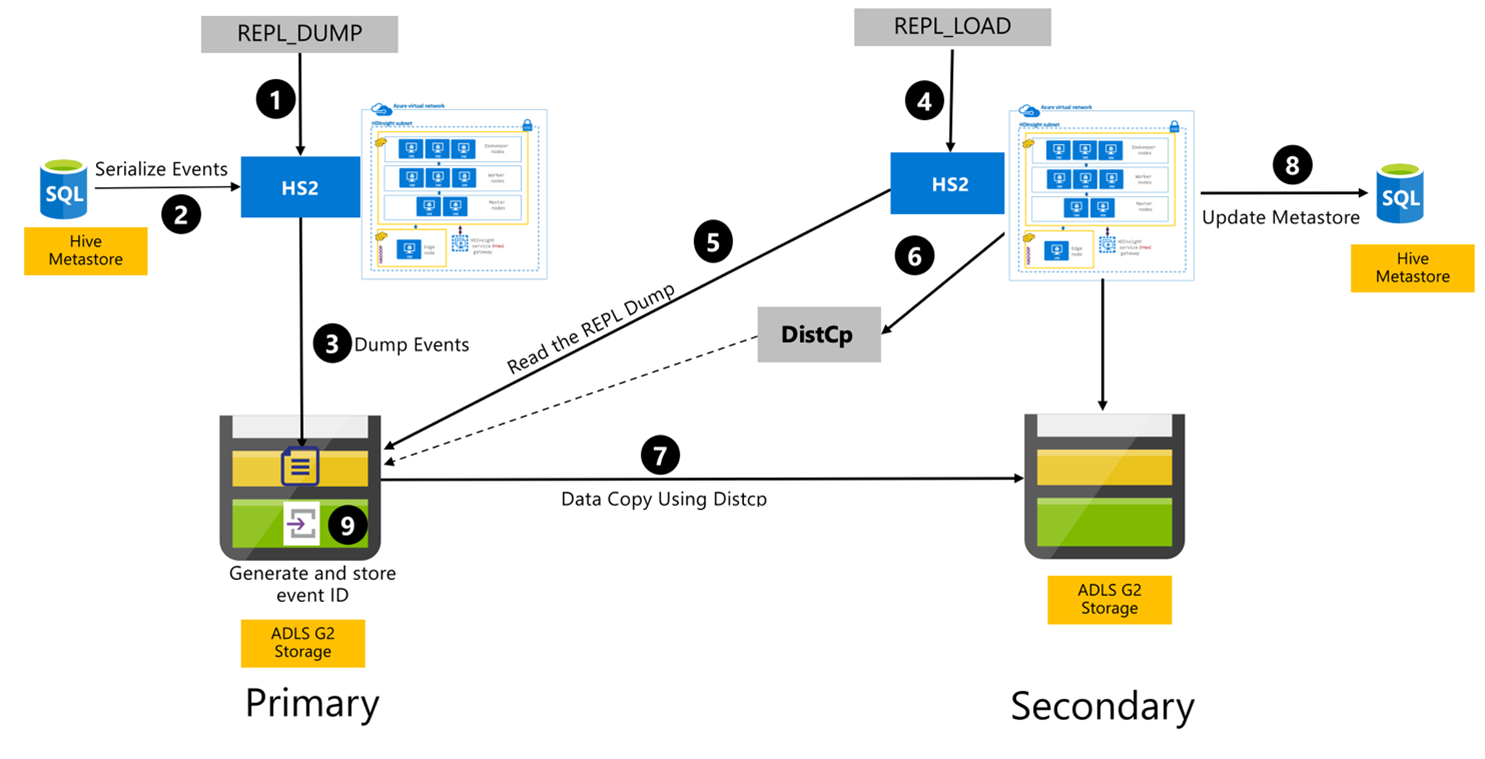
Hive replication process
The following steps are the sequential events that take place during the Hive Replication process.
Ensure that the tables to replicated are set as the replication source for a certain policy.
The
REPL_DUMPcommand is issued to the primary cluster with associated constraints like database name, event ID range, and Azure Data Lake Storage Gen2 storage URL.The system serializes a dump of all tracked events from the metastore to the latest one. This dump is stored in the Azure Data Lake Storage Gen2 storage account on the primary cluster at the URL that is specified by the
REPL_DUMP.The primary cluster persists the replication metadata to the primary cluster's Azure Data Lake Storage Gen2 storage. The path is configurable in the Hive Config UI in Ambari. The process provides the path where the metadata is stored and the ID of the latest tracked DML/DDL event.
The
REPL_LOADcommand is issued from the secondary cluster. The command points to the path configured in Step 3.The secondary cluster reads the metadata file with tracked events that was created in Step 3. Ensure that the secondary cluster has network connectivity to the Azure Data Lake Storage Gen2 storage of the primary cluster where the tracked events from
REPL_DUMPare stored.The secondary cluster spawns distributed copy (
DistCP) compute.The secondary cluster copies data from the primary cluster's storage.
The metastore on the secondary cluster is updated.
The last tracked event ID is stored in the primary metastore.
Incremental replication follows the same process, and it requires the last replicated event ID as input. This leads to an incremental copy since the last replication event. Incremental replications are normally automated with a pre-determined frequency to achieve required recovery point objectives (RPO).
Replication patterns
Replication is normally configured in a unidirectional way between the primary and secondary, where the primary caters to read and write requests. The secondary cluster caters to read requests only. Writes are allowed on the secondary if there is a disaster, but reverse replication needs to be configured back to the primary.
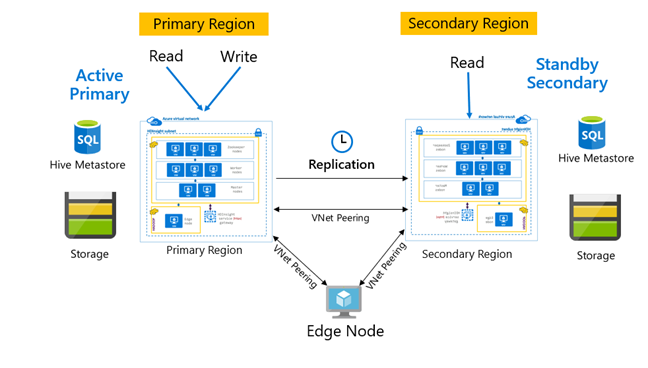
There are many patterns suitable for Hive replication including Primary – Secondary, Hub and Spoke, and Relay.
In HDInsight Active Primary – Standby Secondary is a common business continuity and disaster recovery (BCDR) pattern and HiveReplicationV2 can use this pattern with regionally separated HDInsight Hadoop clusters with VNet peering. A common virtual machine peered to both the clusters can be used to host the replication automation scripts. For more information about possible HDInsight BCDR patterns, refer to HDInsight business continuity documentation.
Hive replication with Enterprise Security Package
In cases where Hive replication is planned on HDInsight Hadoop clusters with Enterprise Security Package, you have to factor in replication mechanisms for Ranger metastore and Microsoft Entra Domain Services.
Use the Microsoft Entra Domain Services replica sets feature to create more than one Microsoft Entra Domain Services replica set per Microsoft Entra tenant across multiple regions. Each individual replica set needs to be peered with HDInsight VNets in their respective regions. In this configuration, changes to Microsoft Entra Domain Services, including configuration, user identity and credentials, groups, group policy objects, computer objects, and other changes are applied to all replica sets in the managed domain using Microsoft Entra Domain Services replication.
Ranger policies can be periodically backed up and replicated from the primary to the secondary using Ranger Import-Export functionality. You can choose to replicate all or a subset of Ranger policies depending on the level of authorizations you are seeking to implement on the secondary cluster.
Sample code
The following code sequence provides an example how bootstrapping and incremental replication can be implemented on a sample table called tpcds_orc.
Set the table as the source for a replication policy.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Bootstrap dump at the primary cluster.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Example output:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Bootstrap load at the secondary cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Check the
REPLstatus at the secondary cluster.repl status tpcds_orc;last_repl_id 2925 Incremental dump at the primary cluster.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Example output:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Incremental load at secondary cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Check
REPLstatus at secondary cluster.repl status tpcds_orc;last_repl_id 2960
Next steps
To learn more about the items discussed in this article, see:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for