Install Jupyter Notebook on your computer and connect to Apache Spark on HDInsight
In this article, you learn how to install Jupyter Notebook with the custom PySpark (for Python) and Apache Spark (for Scala) kernels with Spark magic. You then connect the notebook to an HDInsight cluster.
There are four key steps involved in installing Jupyter and connecting to Apache Spark on HDInsight.
- Configure Spark cluster.
- Install Jupyter Notebook.
- Install the PySpark and Spark kernels with the Spark magic.
- Configure Spark magic to access Spark cluster on HDInsight.
For more information about custom kernels and Spark magic, see Kernels available for Jupyter Notebooks with Apache Spark Linux clusters on HDInsight.
Prerequisites
An Apache Spark cluster on HDInsight. For instructions, see Create Apache Spark clusters in Azure HDInsight. The local notebook connects to the HDInsight cluster.
Familiarity with using Jupyter Notebooks with Spark on HDInsight.
Install Jupyter Notebook on your computer
Install Python before you install Jupyter Notebooks. The Anaconda distribution will install both, Python, and Jupyter Notebook.
Download the Anaconda installer for your platform and run the setup. While running the setup wizard, make sure you select the option to add Anaconda to your PATH variable. See also, Installing Jupyter using Anaconda.
Install Spark magic
Enter the command
pip install sparkmagic==0.13.1to install Spark magic for HDInsight clusters version 3.6 and 4.0. See also, sparkmagic documentation.Ensure
ipywidgetsis properly installed by running the following command:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Install PySpark and Spark kernels
Identify where
sparkmagicis installed by entering the following command:pip show sparkmagicThen change your working directory to the location identified with the above command.
From your new working directory, enter one or more of the commands below to install the wanted kernel(s):
Kernel Command Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOptional. Enter the command below to enable the server extension:
jupyter serverextension enable --py sparkmagic
Configure Spark magic to connect to HDInsight Spark cluster
In this section, you configure the Spark magic that you installed earlier to connect to an Apache Spark cluster.
Start the Python shell with the following command:
pythonThe Jupyter configuration information is typically stored in the users home directory. Enter the following command to identify the home directory, and create a folder called .sparkmagic. The full path will be outputted.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Within the folder
.sparkmagic, create a file called config.json and add the following JSON snippet inside it.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Make the following edits to the file:
Template value New value {USERNAME} Cluster login, default is admin.{CLUSTERDNSNAME} Cluster name {BASE64ENCODEDPASSWORD} A base64 encoded password for your actual password. You can generate a base64 password at https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Keep if using sparkmagic 0.12.7(clusters v3.5 and v3.6). If usingsparkmagic 0.2.3(clusters v3.4), replace with"should_heartbeat": true.You can see a full example file at sample config.json.
Tip
Heartbeats are sent to ensure that sessions are not leaked. When a computer goes to sleep or is shut down, the heartbeat is not sent, resulting in the session being cleaned up. For clusters v3.4, if you wish to disable this behavior, you can set the Livy config
livy.server.interactive.heartbeat.timeoutto0from the Ambari UI. For clusters v3.5, if you do not set the 3.5 configuration above, the session will not be deleted.Start Jupyter. Use the following command from the command prompt.
jupyter notebookVerify that you can use the Spark magic available with the kernels. Complete the following steps.
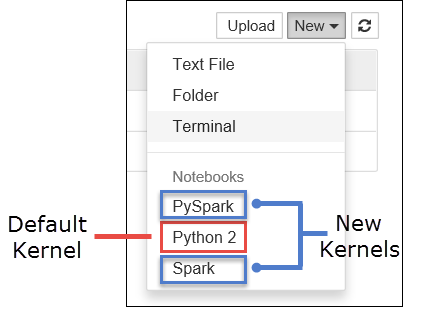
a. Create a new notebook. From the right-hand corner, select New. You should see the default kernel Python 2 or Python 3 and the kernels you installed. The actual values may vary depending on your installation choices. Select PySpark.
Important
After selecting New review your shell for any errors. If you see the error
TypeError: __init__() got an unexpected keyword argument 'io_loop'you may be experiencing a known issue with certain versions of Tornado. If so, stop the kernel and then downgrade your Tornado installation with the following command:pip install tornado==4.5.3.b. Run the following code snippet.
%%sql SELECT * FROM hivesampletable LIMIT 5If you can successfully retrieve the output, your connection to the HDInsight cluster is tested.
If you want to update the notebook configuration to connect to a different cluster, update the config.json with the new set of values, as shown in Step 3, above.
Why should I install Jupyter on my computer?
Reasons to install Jupyter on your computer and then connect it to an Apache Spark cluster on HDInsight:
- Provides you the option to create your notebooks locally, test your application against a running cluster, and then upload the notebooks to the cluster. To upload the notebooks to the cluster, you can either upload them using the Jupyter Notebook that is running or the cluster, or save them to the
/HdiNotebooksfolder in the storage account associated with the cluster. For more information on how notebooks are stored on the cluster, see Where are Jupyter Notebooks stored? - With the notebooks available locally, you can connect to different Spark clusters based on your application requirement.
- You can use GitHub to implement a source control system and have version control for the notebooks. You can also have a collaborative environment where multiple users can work with the same notebook.
- You can work with notebooks locally without even having a cluster up. You only need a cluster to test your notebooks against, not to manually manage your notebooks or a development environment.
- It may be easier to configure your own local development environment than it's to configure the Jupyter installation on the cluster. You can take advantage of all the software you've installed locally without configuring one or more remote clusters.
Warning
With Jupyter installed on your local computer, multiple users can run the same notebook on the same Spark cluster at the same time. In such a situation, multiple Livy sessions are created. If you run into an issue and want to debug that, it will be a complex task to track which Livy session belongs to which user.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for