Overview of Apache Spark Streaming
Apache Spark Streaming provides data stream processing on HDInsight Spark clusters. With a guarantee that any input event is processed exactly once, even if a node failure occurs. A Spark Stream is a long-running job that receives input data from a wide variety of sources, including Azure Event Hubs. Also: Azure IoT Hub, Apache Kafka, Apache Flume, Twitter, ZeroMQ, raw TCP sockets, or from monitoring Apache Hadoop YARN filesystems. Unlike a solely event-driven process, a Spark Stream batches input data into time windows. Such as a 2-second slice, and then transforms each batch of data using map, reduce, join, and extract operations. The Spark Stream then writes the transformed data out to filesystems, databases, dashboards, and the console.
Spark Streaming applications must wait a fraction of a second to collect each micro-batch of events before sending that batch on for processing. In contrast, an event-driven application processes each event immediately. Spark Streaming latency is typically under a few seconds. The benefits of the micro-batch approach are more efficient data processing and simpler aggregate calculations.
Introducing the DStream
Spark Streaming represents a continuous stream of incoming data using a discretized stream called a DStream. A DStream can be created from input sources such as Event Hubs or Kafka. Or by applying transformations on another DStream.
A DStream provides a layer of abstraction on top of the raw event data.
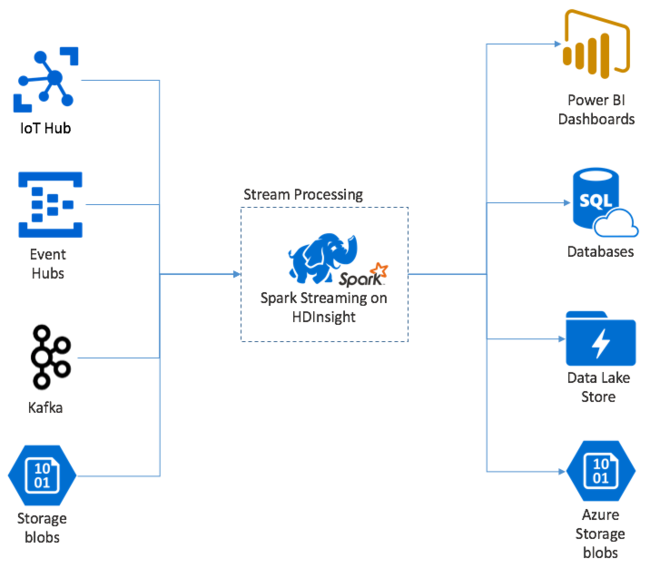
Start with a single event, say a temperature reading from a connected thermostat. When this event arrives at your Spark Streaming application, the event is stored in a reliable way, where it's replicated on multiple nodes. This fault-tolerance ensures that the failure of any single node won't result in the loss of your event. The Spark core uses a data structure that distributes data across multiple nodes in the cluster. Where each node generally maintains its own data in-memory for best performance. This data structure is called a resilient distributed dataset (RDD).
Each RDD represents events collected over a user-defined timeframe called the batch interval. As each batch interval elapses, a new RDD is produced that contains all the data from that interval. The continuous set of RDDs is collected into a DStream. For example, if the batch interval is one second long, your DStream emits a batch every second containing one RDD that contains all the data ingested during that second. When processing the DStream, the temperature event appears in one of these batches. A Spark Streaming application processes the batches that contain the events and ultimately acts on the data stored in each RDD.
Structure of a Spark Streaming application
A Spark Streaming application is a long-running application that receives data from ingest sources. Applies transformations to process the data, and then pushes the data out to one or more destinations. The structure of a Spark Streaming application has a static part and a dynamic part. The static part defines where the data comes from, what processing to do on the data. And where the results should go. The dynamic part is running the application indefinitely, waiting for a stop signal.
For example, the following simple application receives a line of text over a TCP socket and counts the number of times each word appears.
Define the application
The application logic definition has four steps:
- Create a StreamingContext.
- Create a DStream from the StreamingContext.
- Apply transformations to the DStream.
- Output the results.
This definition is static, and no data is processed until you run the application.
Create a StreamingContext
Create a StreamingContext from the SparkContext that points to your cluster. When creating a StreamingContext, you specify the size of the batch in seconds, for example:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Create a DStream
With the StreamingContext instance, create an input DStream for your input source. In this case, the application is watching for the appearance of new files in the default attached storage.
val lines = ssc.textFileStream("/uploads/Test/")
Apply transformations
You implement the processing by applying transformations on the DStream. This application receives one line of text at a time from the file, splits each line into words. And then uses a map-reduce pattern to count the number of times each word appears.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Output results
Push the transformation results out to the destination systems by applying output operations. In this case, the result of each run through the computation is printed in the console output.
wordCounts.print()
Run the application
Start the streaming application and run until a termination signal is received.
ssc.start()
ssc.awaitTermination()
For details on the Spark Stream API, see Apache Spark Streaming Programming Guide.
The following sample application is self-contained, so you can run it inside a Jupyter Notebook. This example creates a mock data source in the class DummySource that outputs the value of a counter and the current time in milliseconds every five seconds. A new StreamingContext object has a batch interval of 30 seconds. Every time a batch is created, the streaming application examines the RDD produced. Then converts the RDD to a Spark DataFrame, and creates a temporary table over the DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Wait for about 30 seconds after starting the application above. Then, you can query the DataFrame periodically to see the current set of values present in the batch, for example using this SQL query:
%%sql
SELECT * FROM demo_numbers
The resulting output looks like the following output:
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
There are six values, since the DummySource creates a value every 5 seconds and the application emits a batch every 30 seconds.
Sliding windows
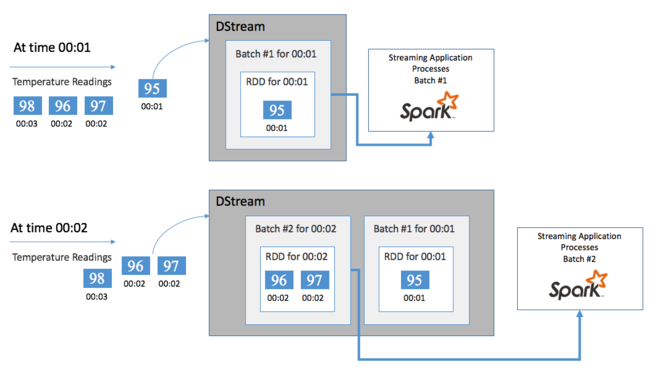
To do aggregate calculations on your DStream over some time period, for example to get an average temperature over the last two seconds, use the sliding window operations included with Spark Streaming. A sliding window has a duration (the window length) and the interval during which the window's contents are evaluated (the slide interval).
Sliding windows can overlap, for example, you can define a window with a length of two seconds, that slides every one second. This action means every time you do an aggregation calculation, the window will include data from the last one second of the previous window. And any new data in the next one second.

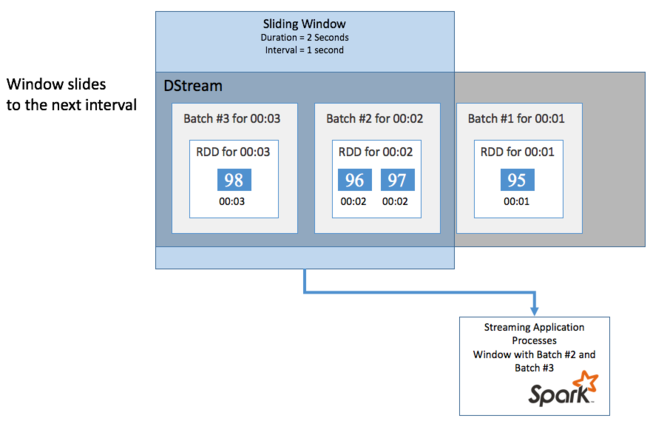
The following example updates the code that uses the DummySource, to collect the batches into a window with a one-minute duration and a one-minute slide.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
After the first minute, there are 12 entries - six entries from each of the two batches collected in the window.
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
The sliding window functions available in the Spark Streaming API include window, countByWindow, reduceByWindow, and countByValueAndWindow. For details on these functions, see Transformations on DStreams.
Checkpointing
To deliver resiliency and fault tolerance, Spark Streaming relies on checkpointing to ensure that stream processing can continue uninterrupted, even in the face of node failures. Spark creates checkpoints to durable storage (Azure Storage or Data Lake Storage). These checkpoints store streaming application metadata such as the configuration, and the operations defined by the application. Also, any batches that were queued but not yet processed. Sometimes, the checkpoints will also include saving the data in the RDDs to more quickly rebuild the state of the data from what is present in the RDDs managed by Spark.
Deploying Spark Streaming applications
You typically build a Spark Streaming application locally into a JAR file. Then deploy it to Spark on HDInsight by copying the JAR file to the default attached storage. You can start your application with the LIVY REST APIs available from your cluster using a POST operation. The body of the POST includes a JSON document that provides the path to your JAR. And the name of the class whose main method defines and runs the streaming application, and optionally the resource requirements of the job (such as the number of executors, memory, and cores). Also, any configuration settings your application code requires.
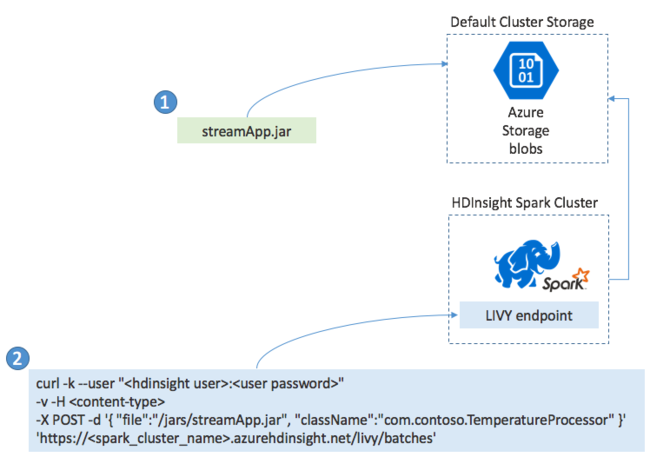
The status of all applications can also be checked with a GET request against a LIVY endpoint. Finally, you can end a running application by issuing a DELETE request against the LIVY endpoint. For details on the LIVY API, see Remote jobs with Apache LIVY
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for