Tutorial: Transfer data to Azure Files with Azure Import/Export
This article provides step-by-step instructions on how to use the Azure Import/Export service to securely import large amounts of data into Azure Files. To import data, the service requires you to ship supported disk drives containing your data to an Azure datacenter.
The Import/Export service supports only import of Azure Files into Azure Storage. Exporting Azure Files isn't supported.
In this tutorial, you learn how to:
- Prerequisites to import data to Azure Files
- Step 1: Prepare the drives
- Step 2: Create an import job
- Step 3: Ship the drives to Azure datacenter
- Step 4: Update the job with tracking information
- Step 5: Verify data upload to Azure
Prerequisites
Before you create an import job to transfer data into Azure Files, carefully review and complete the following list of prerequisites. You must:
- Have an active Azure subscription to use with Import/Export service.
- Have at least one Azure Storage account. See the list of Supported storage accounts and storage types for Import/Export service.
- Consider configuring large file shares on the storage account. During imports to Azure Files, if a file share doesn't have enough free space, auto splitting the data to multiple Azure file shares is no longer supported, and the copy will fail. For instructions, see Configure large file shares on a storage account.
- For information on creating a new storage account, see How to create a storage account.
- Have an adequate number of disks of supported types.
- Have a Windows system running a supported OS version.
- Download the current release of the Azure Import/Export version 2 tool, for files, on the Windows system:
- Download WAImportExport version 2. The current version is 2.2.0.300.
- Unzip to the default folder
WaImportExportV2. For example,C:\WaImportExportV2.
- Have a valid carrier account and a tracking number for the order:
- You must use a carrier in the Carrier names list on the Shipping tab for your order. If you don't have a carrier account, contact the carrier to create one.
- The carrier account must be valid, should have a balance, and must have return shipping capabilities. Microsoft uses the selected carrier to return all storage media.
- Generate a tracking number for the import/export job in the carrier account. Every job should have a separate tracking number. Multiple jobs with the same tracking number aren't supported.
Step 1: Prepare the drives
This step generates a journal file. The journal file stores basic information such as drive serial number, encryption key, and storage account details.
Do the following steps to prepare the drives.
Connect your disk drives to the Windows system via SATA connectors.
Create a single NTFS volume on each drive. Assign a drive letter to the volume. Do not use mountpoints.
Modify the dataset.csv file in the root folder where the tool is. Depending on whether you want to import a file or folder or both, add entries in the dataset.csv file similar to the following examples.
To import a file: In the following example, the data to copy is on the F: drive. Your file MyFile1.txt is copied to the root of the MyAzureFileshare1. If the MyAzureFileshare1 doesn't exist, it's created in the Azure Storage account. Folder structure is maintained.
BasePath,DstItemPathOrPrefix,ItemType "F:\MyFolder1\MyFile1.txt","MyAzureFileshare1/MyFile1.txt",fileTo import a folder: All files and folders under MyFolder2 are recursively copied to the fileshare. Folder structure is maintained. If you import a file with the same name as an existing file in the destination folder, the imported file will overwrite that file.
"F:\MyFolder2\","MyAzureFileshare1/",fileNote
The /Disposition parameter, which let you choose what to do when you import a file that already exists in earlier versions of the tool, isn't supported in Azure Import/Export version 2.2.0.300. In the earlier tool versions, an imported file with the same name as an existing file was renamed by default.
Multiple entries can be made in the same file corresponding to folders or files that are imported.
"F:\MyFolder1\MyFile1.txt","MyAzureFileshare1/MyFile1.txt",file "F:\MyFolder2\","MyAzureFileshare1/",file
Modify the driveset.csv file in the root folder where the tool is. Add entries in the driveset.csv file similar to the following examples. The driveset file has the list of disks and corresponding drive letters so that the tool can correctly pick the list of disks to be prepared.
This example assumes that two disks are attached and basic NTFS volumes G:\ and H:\ are created. H:\is not encrypted while G: is already encrypted. The tool formats and encrypts the disk that hosts H:\ only (and not G:).
For a disk that isn't encrypted: Specify Encrypt to enable BitLocker encryption on the disk.
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey H,Format,SilentMode,Encrypt,For a disk that is already encrypted: Specify AlreadyEncrypted and supply the BitLocker key.
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey G,AlreadyFormatted,SilentMode,AlreadyEncrypted,060456-014509-132033-080300-252615-584177-672089-411631Multiple entries can be made in the same file corresponding to multiple drives. Learn more about preparing the driveset CSV file.
Use the
PrepImportoption to copy and prepare data to the disk drive. For the first copy session to copy directories and/or files with a new copy session, run the following command:.\WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] [/silentmode] [/InitialDriveSet:<driveset.csv>]/DataSet:<dataset.csv>An import example is shown below.
.\WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#1 /InitialDriveSet:driveset.csv /DataSet:dataset.csv /logdir:C:\logsNote
If you don't have long paths enabled on the client, and any path and file name in your data copy exceeds 256 characters, the WAImportExport tool will report failures. To avoid this kind of failure, enable long paths on your Windows client.
A journal file with name you provided with
/j:parameter, is created for every run of the command line. Each drive you prepare has a journal file that must be uploaded when you create the import job. Drives without journal files aren't processed.Important
Do not modify the journal files or the data on the disk drives, and don't reformat any disks, after completing disk preparation.
For additional samples, go to Samples for journal files.
Step 2: Create an import job
Do the following steps to order an import job in Azure Import/Export job via the portal.
Use your Microsoft Azure credentials to sign in at this URL: https://portal.azure.com.
Select + Create a resource, and search for Azure Data Box. Select Azure Data Box.
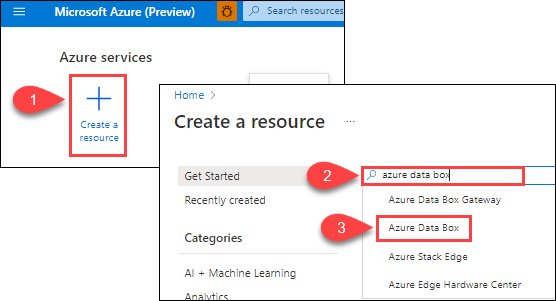
Select Create.

To get started with the import order, select the following options:
- Select the Import to Azure transfer type.
- Select the subscription to use for the Import/Export job.
- Select a resource group.
- Select the Source country/region for the job.
- Select the Destination Azure region for the job.
- Then select Apply.
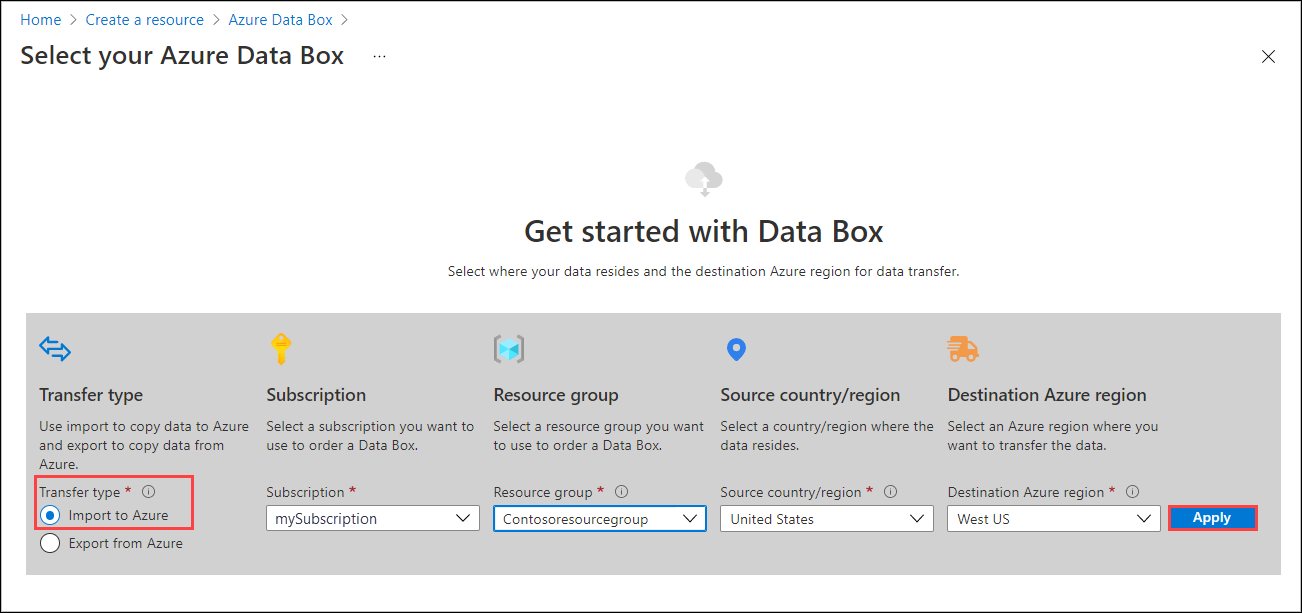
Choose the Select button for Import/Export Job.
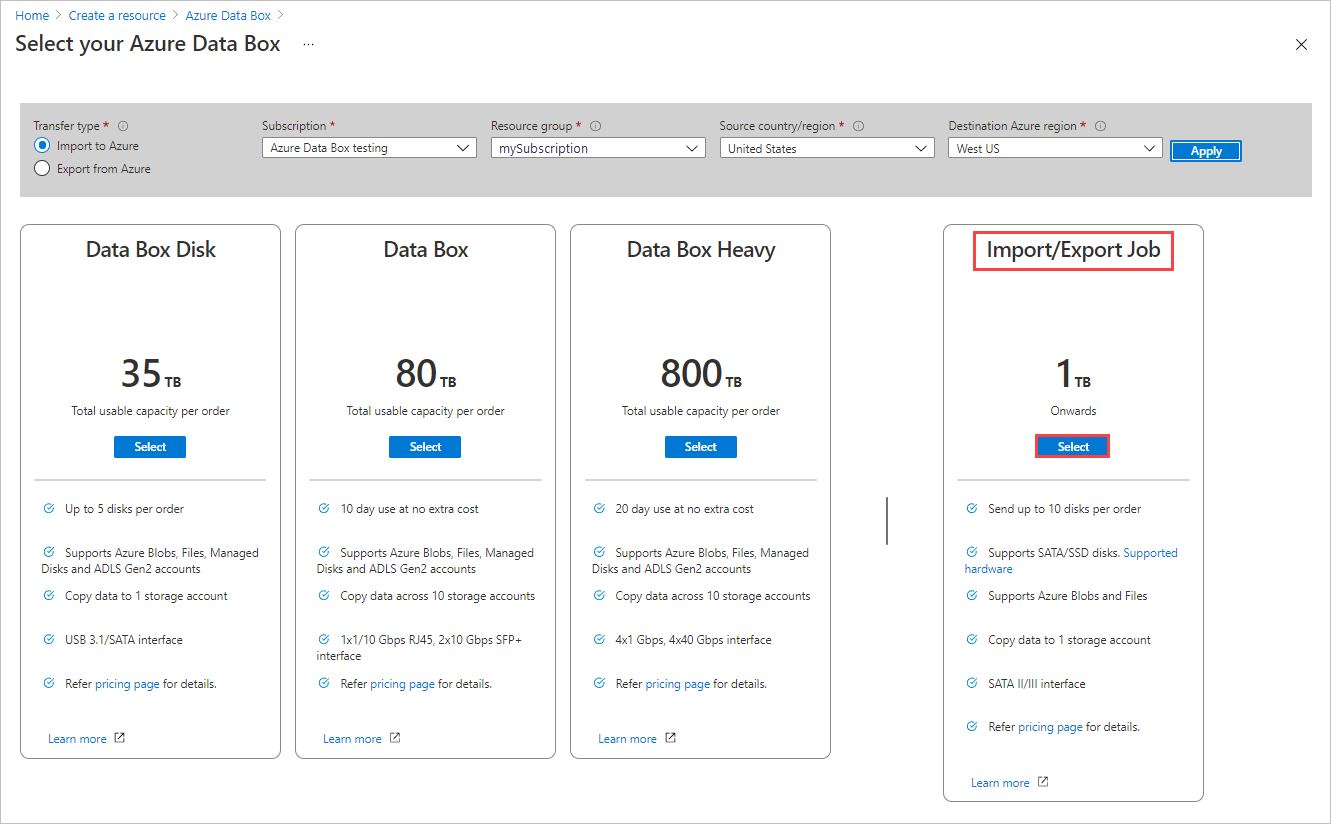
In Basics:
- Enter a descriptive name for the job. Use the name to track the progress of your jobs.
- The name must have from 3 to 24 characters.
- The name must include only letters, numbers, and hyphens.
- The name must start and end with a letter or number.
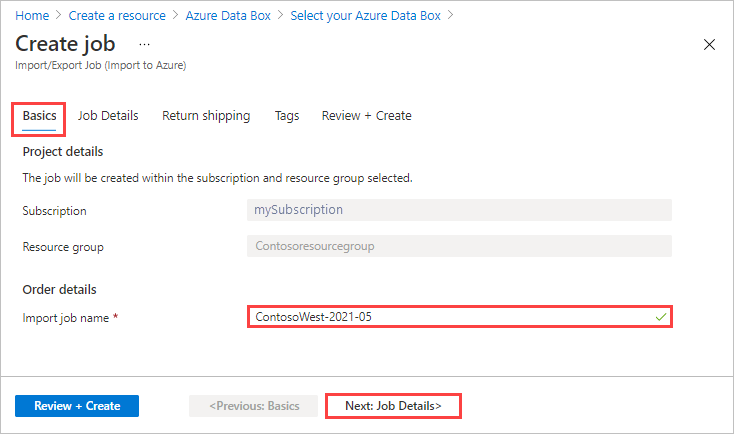
Select Next: Job Details > to proceed.
- Enter a descriptive name for the job. Use the name to track the progress of your jobs.
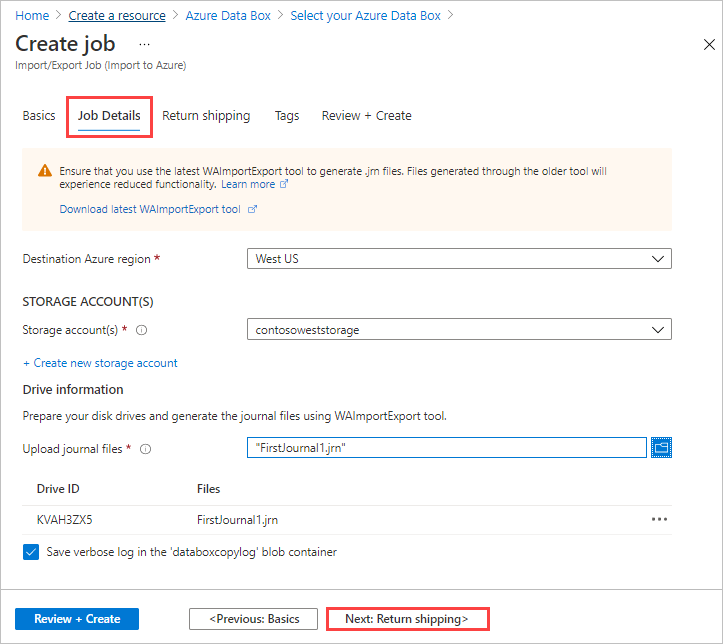
In Job Details:
Before you go further, make sure you're using the latest WAImportExport tool. The tool is used to read the journal file(s) that you upload. You can use the download link to update the tool.
Change the destination Azure region for the job if needed.
Select one or more storage accounts to use for the job. You can create a new storage account if needed.
Under Drive information, use the Copy button to upload each journal file that you created during the preceding Step 1: Prepare the drives. When you upload a journal file, the Drive ID is displayed.
If
waimportexport.exe version1was used, upload one file for each drive that you prepared.If the journal file is larger than 2 MB, then you can use the
<Journal file name>_DriveInfo_<Drive serial ID>.xml, which was created along with the journal file.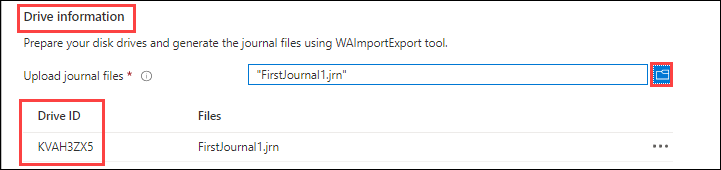
In Return shipping:
Select a shipping carrier from the drop-down list for Carrier. The location of the Microsoft datacenter for the selected region determines which carriers are available.
Enter a Carrier account number. The account number for a valid carrier account is required.
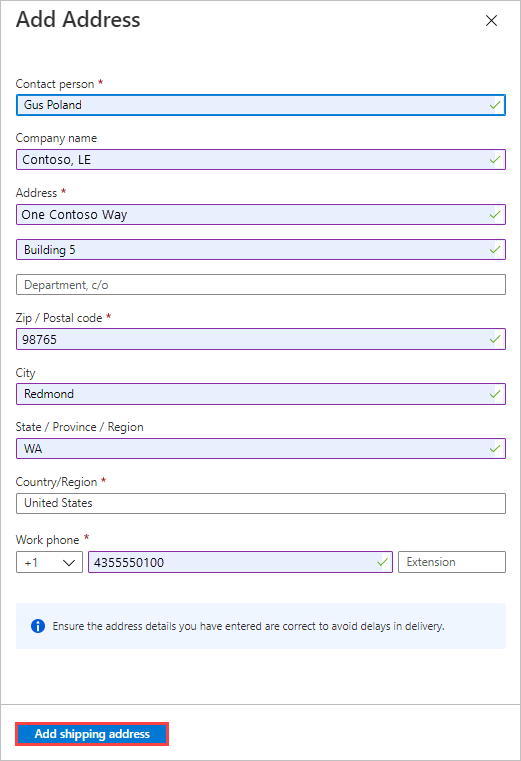
In the Return address area, select the + Add Address button, and add the address to ship to.
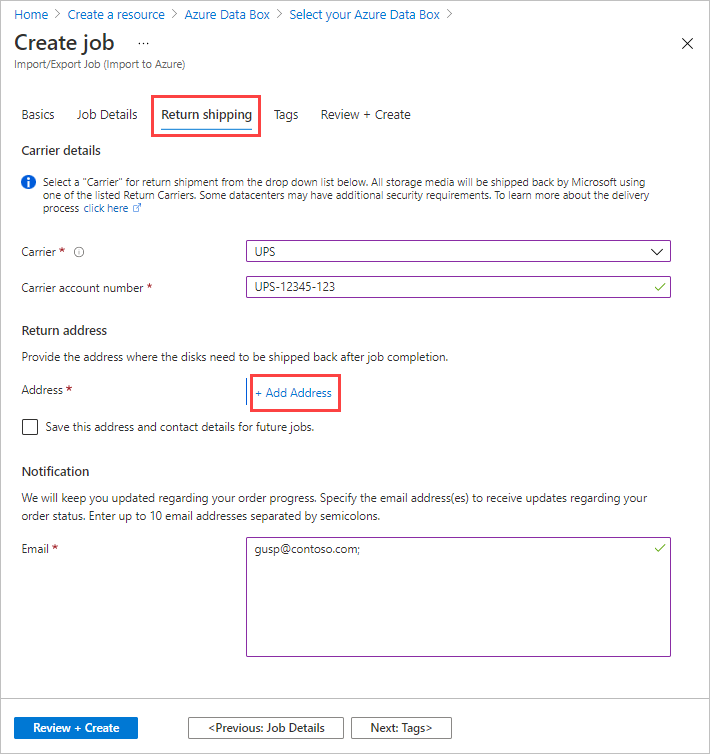
On the Add Address blade, you can add an address or use an existing one. When you complete the address fields, select Add shipping address.
In the Notification area, enter email addresses for the people you want to notify of the job's progress.
Tip
Instead of specifying an email address for a single user, provide a group email to ensure that you receive notifications even if an admin leaves.
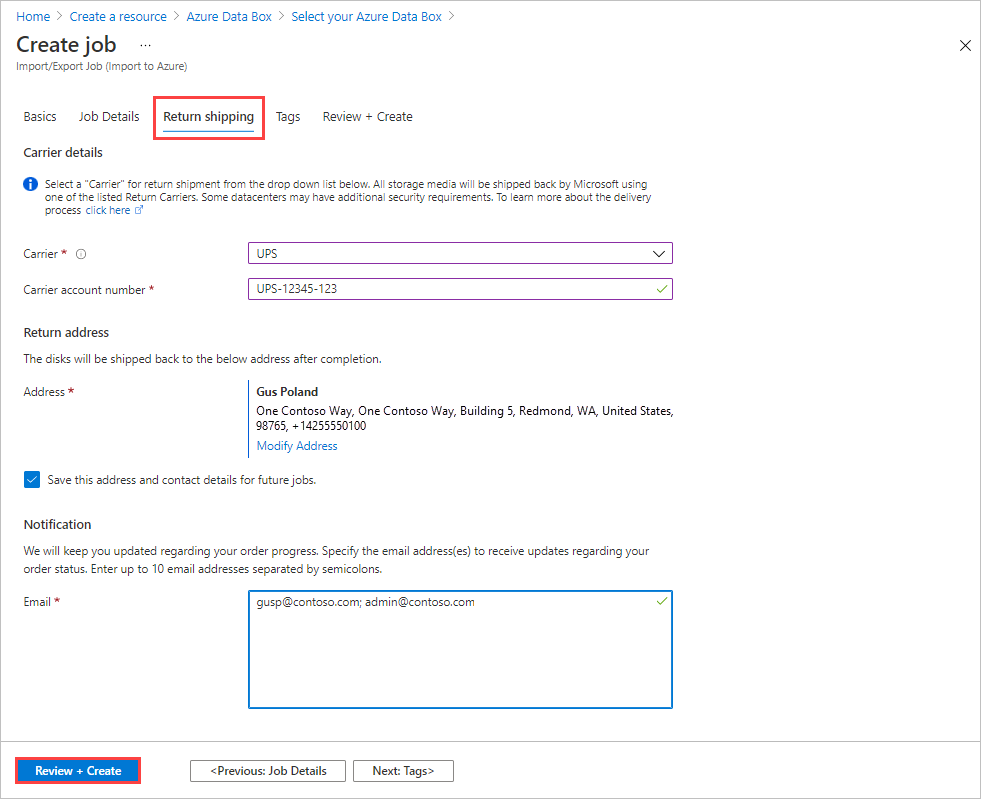
Select Review + Create to proceed.
In Review + Create:
- Review the Terms and Privacy information, and then select the checkbox by "I acknowledge that all the information provided is correct and agree to the terms and conditions." Validation is then done.
- Review the job information. Make a note of the job name and the Azure datacenter shipping address to ship disks back to. This information is used later on the shipping label.
- Select Create.
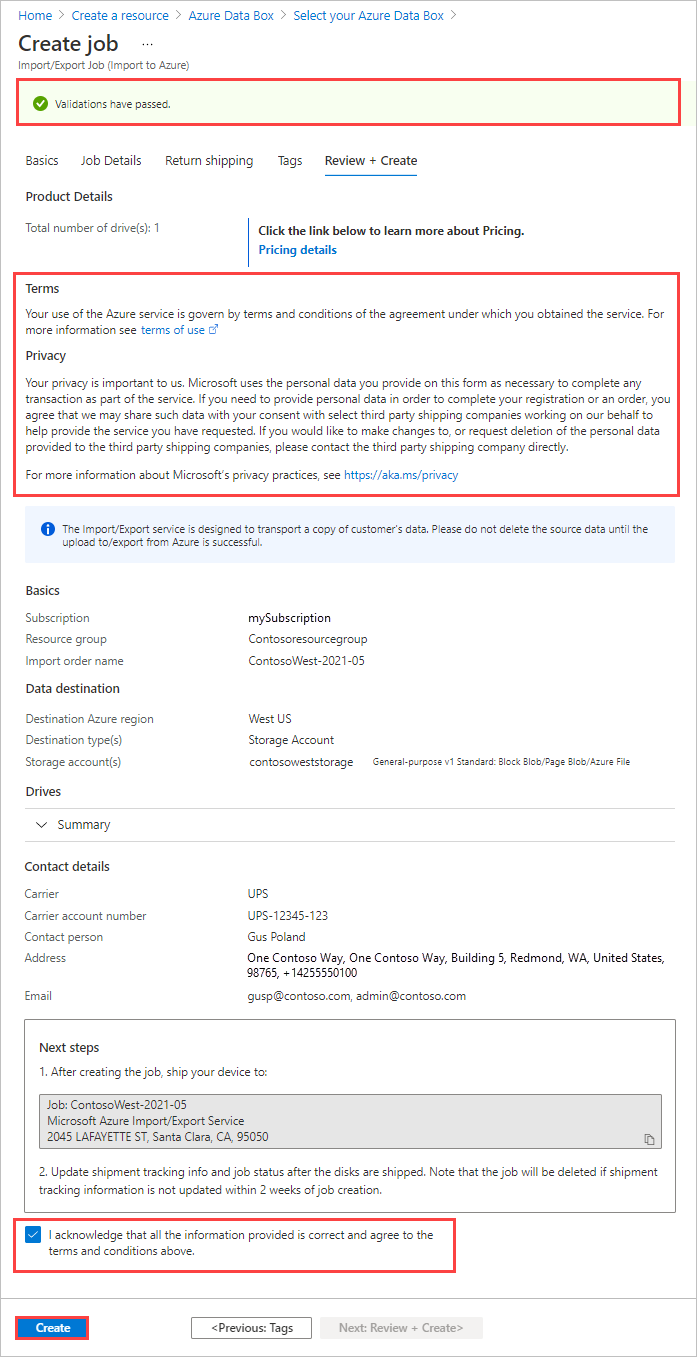
After the job is created, you'll see the following message.
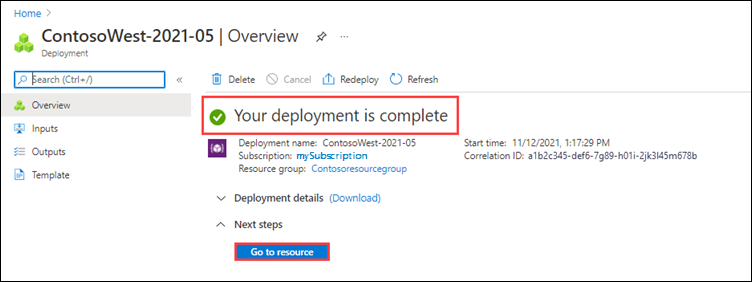
You can select Go to resource to open the Overview of the job.



Step 3: Ship the drives to the Azure datacenter
FedEx, UPS, or DHL can be used to ship the package to Azure datacenter. If you want to use a carrier other than FedEx/DHL, contact Azure Data Box Operations team at adbops@microsoft.com
- Provide a valid FedEx, UPS, or DHL carrier account number for use by Microsoft to return the drives.
- When shipping your packages, you must follow the Microsoft Azure Service Terms.
- Properly package your disks to avoid potential damage and delays in processing. Follow these recommended best practices:
- Wrap the disk drives securely with protective bubble wrap. Bubble wrap acts as a shock absorber and protects the drive from impact during transit. Before shipping, ensure that the entire drive is thoroughly covered and cushioned.
- Place the wrapped drives within a foam shipper. The foam shipper provides extra protection and keeps the drive securely in place during transit.
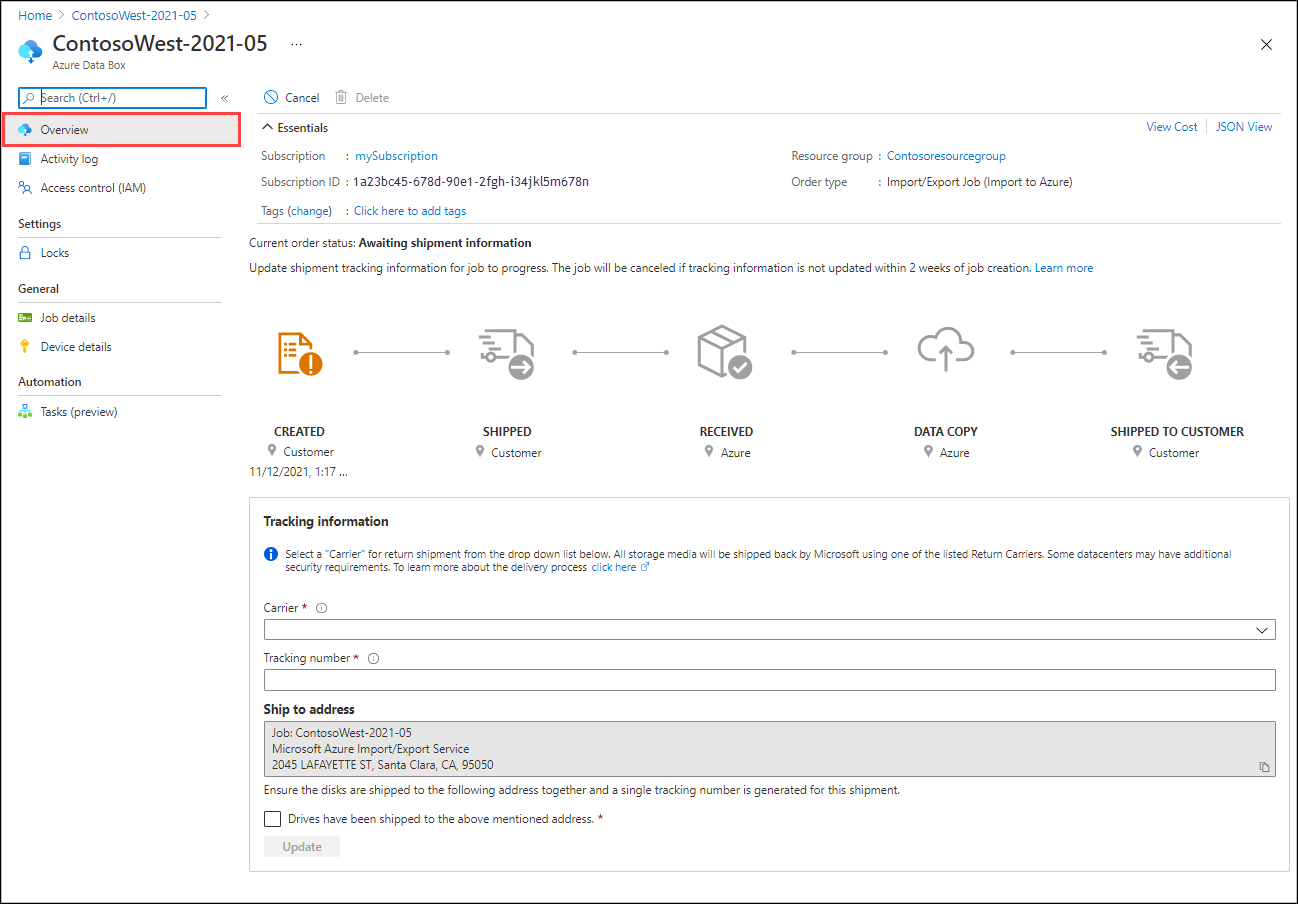
Step 4: Update the job with tracking information
After you ship the disks, return to the job in the Azure portal and fill in the tracking information.
After you provide tracking details, the job status changes to Shipping, and the job can't be canceled. You can only cancel a job while it's in Creating state.
Important
If the tracking number is not updated within 2 weeks of creating the job, the job expires.
To complete the tracking information for a job that you created in the portal, do these steps:
Open the job in the Azure portal/.
On the Overview pane, scroll down to Tracking information and complete the entries:
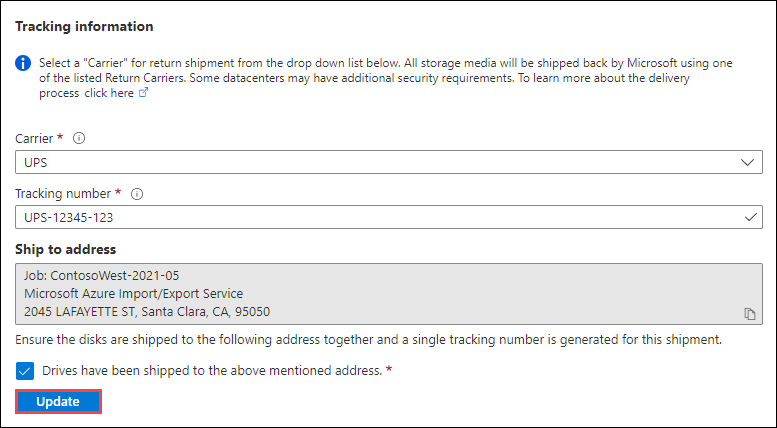
- Provide the Carrier and Tracking number.
- Make sure the Ship to address is correct.
- Select the checkbox by "Drives have been shipped to the above mentioned address."
- When you finish, select Update.
You can track the job progress on the Overview pane. For a description of each job state, go to View your job status.
![]()
Step 5: Verify data upload to Azure
Track the job to completion, then verify that the upload was successful and all data is present.
Review the Data copy details of the completed job to locate the logs for each drive included in the job:
- Use the verbose log to verify each successfully transferred file.
- Use the copy log to find the source of each failed data copy.

For more information, see Review copy logs from imports and exports.
After you verify the data transfers, you can delete your on-premises data. Delete your on-premises data only after you verify that the upload was successful.
Note
In the latest version of the Azure Import/Export tool for files (2.2.0.300), if a file share doesn't have enough free space, the data is no longer auto split to multiple Azure file shares. Instead, the copy fails, and you'll be contacted by Support. You'll need to either configure large file shares on the storage account or move around some data to make space in the share. For more information, see Configure large file shares on a storage account.
Samples for journal files
To add more drives, create a new driveset file and run the command as below.
For subsequent copy sessions to disk drives other than those specified in the InitialDriveset .csv file, specify a new driveset .csv file and provide it as a value to the parameter AdditionalDriveSet. Use the same journal file name and provide a new session ID. The format of AdditionalDriveset CSV file is same as InitialDriveSet format.
WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> /AdditionalDriveSet:<driveset.csv>
An import example is shown below.
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#3 /AdditionalDriveSet:driveset-2.csv
To add additional data to the same driveset, use the PrepImport command for subsequent copy sessions to copy additional files/directory.
For subsequent copy sessions to the same hard disk drives specified in InitialDriveset.csv file, specify the same journal file name and provide a new session ID; there is no need to provide the storage account key.
WAImportExport PrepImport /j:<JournalFile> /id:<SessionId> /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] DataSet:<dataset.csv>
An import example is shown below.
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /DataSet:dataset-2.csv
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for