Application Lifecycle Management in Machine Learning Studio (classic)
APPLIES TO:  Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning
ML Studio (classic) documentation is being retired and may not be updated in the future.
Machine Learning Studio (classic) is a tool for developing machine learning experiments that are operationalized in the Azure cloud platform. It is like the Visual Studio IDE and scalable cloud service merged into a single platform. You can incorporate standard Application Lifecycle Management (ALM) practices from versioning various assets to automated execution and deployment, into Machine Learning Studio (classic). This article discusses some of the options and approaches.
Note
We recommend that you use the Azure Az PowerShell module to interact with Azure. See Install Azure PowerShell to get started. To learn how to migrate to the Az PowerShell module, see Migrate Azure PowerShell from AzureRM to Az.
Versioning experiment
There are two recommended ways to version your experiments. You can either rely on the built-in run history or export the experiment in a JSON format so as to manage it externally. Each approach comes with its pros and cons.
Experiment snapshots using Run History
In the execution model of the Machine Learning Studio (classic) learning experiment, an immutable snapshot of the experiment is submitted to the job scheduler whenever you click Run in the experiment editor. To view this list of snapshots, click Run History on the command bar in the experiment editor view.
You can then open the snapshot in Locked mode by clicking the name of the experiment at the time the experiment was submitted to run and the snapshot was taken. Notice that only the first item in the list, which represents the current experiment, is in an Editable state. Also notice that each snapshot can be in various Status states as well, including Finished (Partial run), Failed, Failed (Partial run), or Draft.
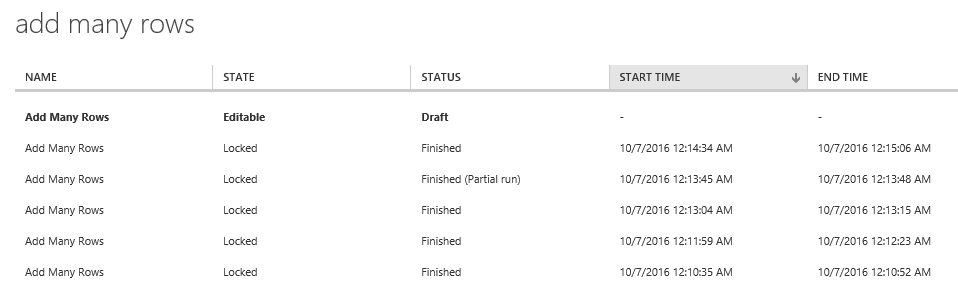
After it's opened, you can save the snapshot experiment as a new experiment and then modify it. If your experiment snapshot contains assets such as trained models, transforms, or datasets that have updated versions, the snapshot retains the references to the original version when the snapshot was taken. If you save the locked snapshot as a new experiment, Machine Learning Studio (classic) detects the existence of a newer version of these assets, and automatically updates them in the new experiment.
If you delete the experiment, all snapshots of that experiment are deleted.
Export/import experiment in JSON format
The run history snapshots keep an immutable version of the experiment in Machine Learning Studio (classic) every time it is submitted to run. You can also save a local copy of the experiment and check it in to your favorite source control system, such as Team Foundation Server, and later on re-create an experiment from that local file. You can use the Machine Learning Studio (classic) PowerShell commandlets Export-AmlExperimentGraph and Import-AmlExperimentGraph to accomplish that.
The JSON file is a textual representation of the experiment graph, which might include a reference to assets in the workspace such as a dataset or a trained model. It doesn't contain a serialized version of the asset. If you attempt to import the JSON document back into the workspace, the referenced assets must already exist with the same asset IDs that are referenced in the experiment. Otherwise you cannot access the imported experiment.
Versioning trained model
A trained model in Machine Learning Studio (classic) is serialized into a format known as an iLearner file (.iLearner), and is stored in the Azure Blob storage account associated with the workspace. One way to get a copy of the iLearner file is through the retraining API. This article explains how the retraining API works. The high-level steps:
- Set up your training experiment.
- Add a web service output port to the Train Model module, or the module that produces the trained model, such as Tune Model Hyperparameter or Create R Model.
- Run your training experiment and then deploy it as a model training web service.
- Call the BES endpoint of the training web service, and specify the desired iLearner file name and Blob storage account location where it will be stored.
- Harvest the produced iLearner file after the BES call finishes.
Another way to retrieve the iLearner file is through the PowerShell commandlet Download-AmlExperimentNodeOutput. This might be easier if you just want to get a copy of the iLearner file without the need to retrain the model programmatically.
After you have the iLearner file containing the trained model, you can then employ your own versioning strategy. The strategy can be as simple as applying a pre/postfix as a naming convention and just leaving the iLearner file in Blob storage, or copying/importing it into your version control system.
The saved iLearner file can then be used for scoring through deployed web services.
Versioning web service
You can deploy two types of web services from an Machine Learning Studio (classic) experiment. The classic web service is tightly coupled with the experiment as well as the workspace. The new web service uses the Azure Resource Manager framework, and it is no longer coupled with the original experiment or the workspace.
Classic web service
To version a classic web service, you can take advantage of the web service endpoint construct. Here is a typical flow:
- From your predictive experiment, you deploy a new classic web service, which contains a default endpoint.
- You create a new endpoint named ep2, which exposes the current version of the experiment/trained model.
- You go back and update your predictive experiment and trained model.
- You redeploy the predictive experiment, which will then update the default endpoint. But this will not alter ep2.
- You create an additional endpoint named ep3, which exposes the new version of the experiment and trained model.
- Go back to step 3 if needed.
Over time, you might have many endpoints created in the same web service. Each endpoint represents a point-in-time copy of the experiment containing the point-in-time version of the trained model. You can then use external logic to determine which endpoint to call, which effectively means selecting a version of the trained model for the scoring run.
You can also create many identical web service endpoints, and then patch different versions of the iLearner file to the endpoint to achieve similar effect. This article explains in more detail how to accomplish that.
New web service
If you create a new Azure Resource Manager-based web service, the endpoint construct is no longer available. Instead, you can generate web service definition (WSD) files, in JSON format, from your predictive experiment by using the Export-AmlWebServiceDefinitionFromExperiment PowerShell commandlet, or by using the Export-AzMlWebservice PowerShell commandlet from a deployed Resource Manager-based web service.
After you have the exported WSD file and version control it, you can also deploy the WSD as a new web service in a different web service plan in a different Azure region. Just make sure you supply the proper storage account configuration as well as the new web service plan ID. To patch in different iLearner files, you can modify the WSD file and update the location reference of the trained model, and deploy it as a new web service.
Automate experiment execution and deployment
An important aspect of ALM is to be able to automate the execution and deployment process of the application. In Machine Learning Studio (classic), you can accomplish this by using the PowerShell module. Here is an example of end-to-end steps that are relevant to a standard ALM automated execution/deployment process by using the Machine Learning Studio (classic) PowerShell module. Each step is linked to one or more PowerShell commandlets that you can use to accomplish that step.
- Upload a dataset.
- Copy a training experiment into the workspace from a workspace or from Gallery, or import an exported experiment from local disk.
- Update the dataset in the training experiment.
- Run the training experiment.
- Promote the trained model.
- Copy a predictive experiment into the workspace.
- Update the trained model in the predictive experiment.
- Run the predictive experiment.
- Deploy a web service from the predictive experiment.
- Test the web service RRS or BES endpoint.
Next steps
- Download the Machine Learning Studio (classic) PowerShell module and start to automate your ALM tasks.
- Learn how to create and manage large number of ML models by using just a single experiment through PowerShell and retraining API.
- Learn more about deploying Machine Learning web services.