Version and track Azure Machine Learning datasets
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
In this article, you'll learn how to version and track Azure Machine Learning datasets for reproducibility. Dataset versioning bookmarks specific states of your data, so that you can apply a specific version of the dataset for future experiments.
You might want to version your Azure Machine Learning resources in these typical scenarios:
- When new data becomes available for retraining
- When you apply different data preparation or feature engineering approaches
Prerequisites
The Azure Machine Learning SDK for Python. This SDK includes the azureml-datasets package
An Azure Machine Learning workspace. Create a new workspace, or retrieve an existing workspace with this code sample:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Register and retrieve dataset versions
You can version, reuse, and share a registered dataset across experiments and with your colleagues. You can register multiple datasets under the same name, and retrieve a specific version by name and version number.
Register a dataset version
This code sample sets the create_new_version parameter of the titanic_ds dataset to True, to register a new version of that dataset. If the workspace has no existing titanic_ds dataset registered, the code creates a new dataset with the name titanic_ds, and sets its version to 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Retrieve a dataset by name
By default, the Dataset class get_by_name() method returns the latest version of the dataset registered with the workspace.
This code returns version 1 of the titanic_ds dataset.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Versioning best practice
When you create a dataset version, you don't create an extra copy of data with the workspace. Since datasets are references to the data in your storage service, you have a single source of truth, managed by your storage service.
Important
If the data referenced by your dataset is overwritten or deleted, a call to a specific version of the dataset does not revert the change.
When you load data from a dataset, the current data content referenced by the dataset is always loaded. If you want to make sure that each dataset version is reproducible, we recommend that you avoid modification of data content referenced by the dataset version. When new data comes in, save new data files into a separate data folder, and then create a new dataset version to include data from that new folder.
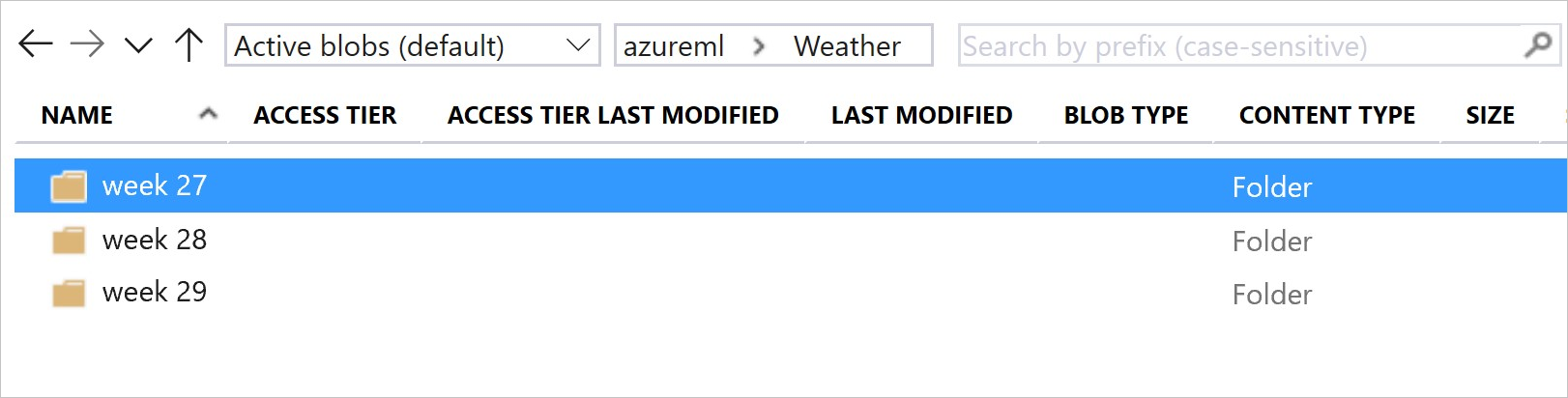
This image and sample code show the recommended way to both structure your data folders and create dataset versions that reference those folders:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Version an ML pipeline output dataset
You can use a dataset as the input and output of each ML pipeline step. When you rerun pipelines, the output of each pipeline step is registered as a new dataset version.
Machine Learning pipelines populate the output of each step into a new folder every time the pipeline reruns. The versioned output datasets then become reproducible. For more information, visit datasets in pipelines.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Track data in your experiments
Azure Machine Learning tracks your data throughout your experiment as input and output datasets. In these scenarios, your data is tracked as an input dataset:
As a
DatasetConsumptionConfigobject, through either theinputsorargumentsparameter of yourScriptRunConfigobject, when submitting the experiment jobWhen your script calls certain methods -
get_by_name()orget_by_id()- for example. The name assigned to the dataset at the time you registered that dataset to the workspace is the displayed name
In these scenarios, your data is tracked as an output dataset:
Pass an
OutputFileDatasetConfigobject through either theoutputsorargumentsparameter when you submit an experiment job.OutputFileDatasetConfigobjects can also persist data between pipeline steps. For more information, visit Move data between ML pipeline stepsRegister a dataset in your script. The name assigned to the dataset when you registered it to the workspace is the name displayed. In this code sample,
training_dsis the displayed name:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Submission of a child job, with an unregistered dataset, in the script. This submission results in an anonymous saved dataset
Trace datasets in experiment jobs
For each Machine Learning experiment, you can trace the input datasets for the experiment Job object. This code sample uses the get_details() method to track the input datasets used with the experiment run:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
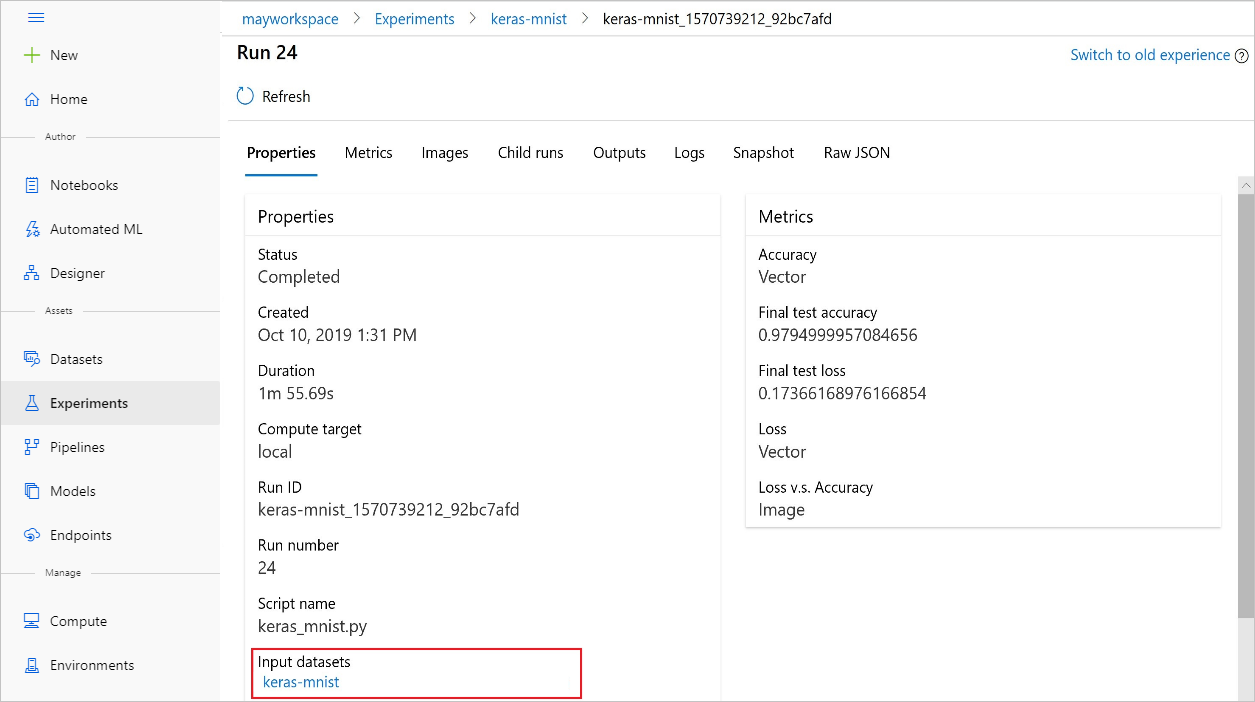
You can also find the input_datasets from experiments with the Azure Machine Learning studio.
This screenshot shows where to find the input dataset of an experiment on Azure Machine Learning studio. For this example, start at your Experiments pane, and open the Properties tab for a specific run of your experiment, keras-mnist.
This code registers models with datasets:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
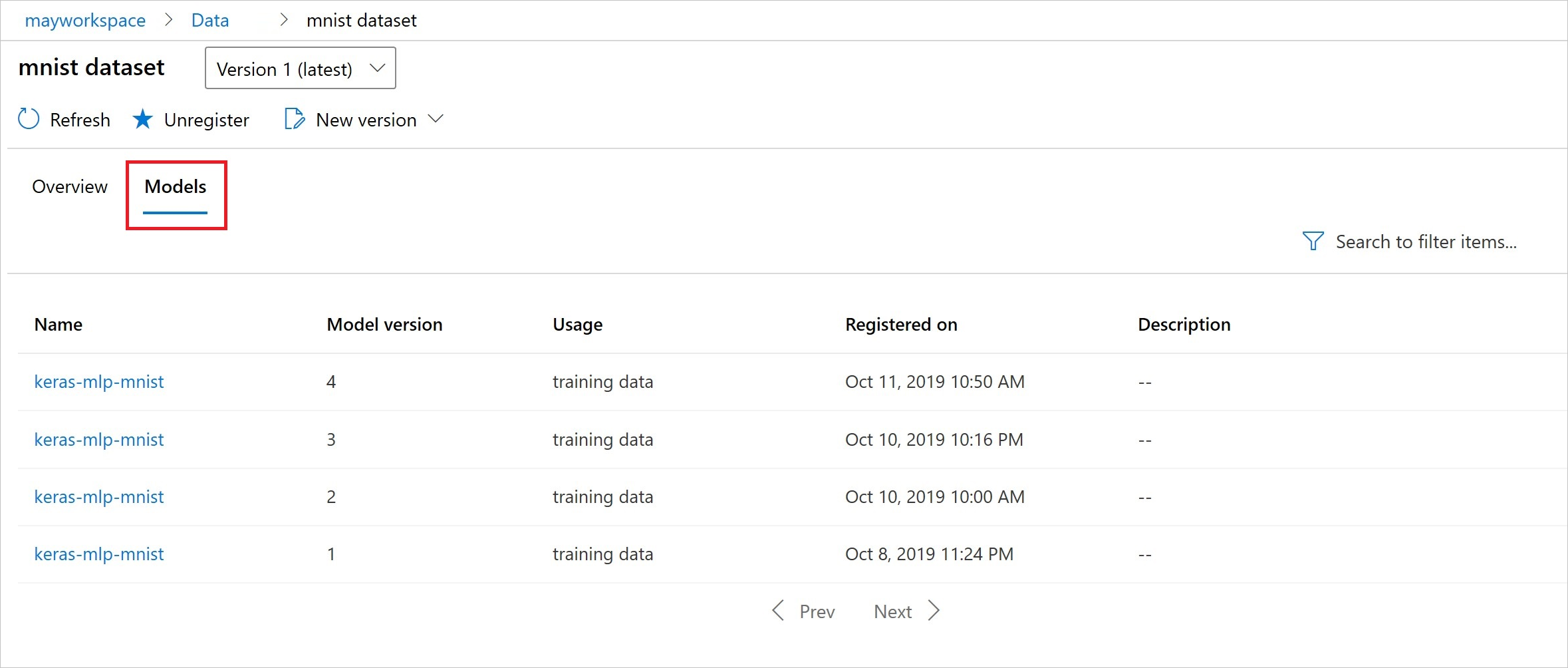
After registration, you can see the list of models registered with the dataset with either Python or the studio.
Thia screenshot is from the Datasets pane under Assets. Select the dataset, and then select the Models tab for a list of the models that are registered with the dataset.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for