Reliability in Azure Traffic Manager
This article contains specific reliability recommendations for Azure Traffic Manager as well as cross-region disaster recovery and business continuity support for Azure Traffic Manager.
For a more detailed overview of reliability principles in Azure, see Azure reliability.
Reliability recommendations
This section contains recommendations for achieving resiliency and availability. Each recommendation falls into one of two categories:
Health items cover areas such as configuration items and the proper function of the major components that make up your Azure Workload, such as Azure Resource configuration settings, dependencies on other services, and so on.
Risk items cover areas such as availability and recovery requirements, testing, monitoring, deployment, and other items that, if left unresolved, increase the chances of problems in the environment.
Reliability recommendations priority matrix
Each recommendation is marked in accordance with the following priority matrix:
| Image | Priority | Description |
|---|---|---|
| High | Immediate fix needed. | |
| Medium | Fix within 3-6 months. | |
| Low | Needs to be reviewed. |
Reliability recommendations summary
Availability
 Traffic Manager Monitor Status should be Online
Traffic Manager Monitor Status should be Online
Monitor status should be online to provide failover for the application workload. If the health of your Traffic Manager displays a Degraded status, then the status of one or more endpoints may also be Degraded.
For more information Traffic Manager endpoint monitoring, see Traffic Manager endpoint monitoring.
To troubleshoot a degraded state on Azure Traffic Manager, see Troubleshooting degraded state on Azure Traffic Manager.
Traffic manager profiles should have more than one endpoint
When configuring the Azure traffic manager, you should provision minimum of two endpoints to fail-over the workload to another instance.
To learn about Traffic Manager endpoint types, see Traffic Manager endpoints.
System Efficiency
 TTL value of user profiles should be in 60 seconds
TTL value of user profiles should be in 60 seconds
Time to Live (TTL) affects how recent of a response a client will get when it makes a request to Azure Traffic Manager. Reducing the TTL value means that the client will be routed to a functioning endpoint faster in the case of a failover. Configure your TTL to 60 seconds to route traffic to a health endpoint as quickly as possible.
For more information on configuring DNS TTL, see Configure DNS Time to Live.
Disaster recovery
Configure at least one endpoint within another region
Profiles should have more than one endpoint to ensure availability if one of the endpoints fails. It is also recommended that endpoints be in different regions.
To learn about Traffic Manager endpoint types, see Traffic Manager endpoints.
Ensure endpoint configured to “(All World)” for geographic profiles
For geographic routing, traffic is routed to endpoints based on defined regions. When a region fails, there is no pre-defined failover. Having an endpoint where the Regional Grouping is configured to “All (World)” for geographic profiles will avoid traffic black holing and guarantee service remains available.
To learn how to add and configure an endpoint, see Add, disable, enable, delete, or move endpoints.
Cross-region disaster recovery and business continuity
Disaster recovery (DR) is about recovering from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you begin to think about creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
When it comes to DR, Microsoft uses the shared responsibility model. In a shared responsibility model, Microsoft ensures that the baseline infrastructure and platform services are available. At the same time, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you are responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR and you can use service-specific features to support fast recovery to help develop your DR plan.
Azure Traffic Manager is a DNS-based traffic load balancer that lets you distribute traffic to your public facing applications across global Azure regions. Traffic Manager also provides your public endpoints with high availability and quick responsiveness.
Traffic Manager uses DNS to direct client requests to the appropriate service endpoint based on a traffic-routing method. Traffic manager also provides health monitoring for every endpoint. The endpoint can be any Internet-facing service hosted inside or outside of Azure. Traffic Manager provides a range of traffic-routing methods and endpoint monitoring options to suit different application needs and automatic failover models. Traffic Manager is resilient to failure, including the failure of an entire Azure region.
Disaster recovery in multi-region geography
DNS is one of the most efficient mechanisms to divert network traffic. DNS is efficient because DNS is often global and external to the data center. DNS is also insulated from any regional or availability zone (AZ) level failures.
There are two technical aspects towards setting up your disaster recovery architecture:
Using a deployment mechanism to replicate instances, data, and configurations between primary and standby environments. This type of disaster recovery can be done natively viaAzure Site Recovery, see Azure Site Recovery Documentation via Microsoft Azure partner appliances/services like Veritas or NetApp.
Developing a solution to divert network/web traffic from the primary site to the standby site. This type of disaster recovery can be achieved via Azure DNS, Azure Traffic Manager(DNS), or third-party global load balancers.
This article focuses specifically on Azure Traffic Manager disaster recovery planning.
Outage detection, notification, and management
During a disaster, the primary endpoint gets probed and the status changes to degraded and the disaster recovery site remains Online. By default, Traffic Manager sends all traffic to the primary (highest-priority) endpoint. If the primary endpoint appears degraded, Traffic Manager routes the traffic to the second endpoint as long as it remains healthy. One can configure more endpoints within Traffic Manager that can serve as extra failover endpoints, or, as load balancers sharing the load between endpoints.
Set up disaster recovery and outage detection
When you have complex architectures and multiple sets of resources capable of performing the same function, you can configure Azure Traffic Manager (based on DNS) to check the health of your resources and route the traffic from the non-healthy resource to the healthy resource.
In the following example, both the primary region and the secondary region have a full deployment. This deployment includes the cloud services and a synchronized database.
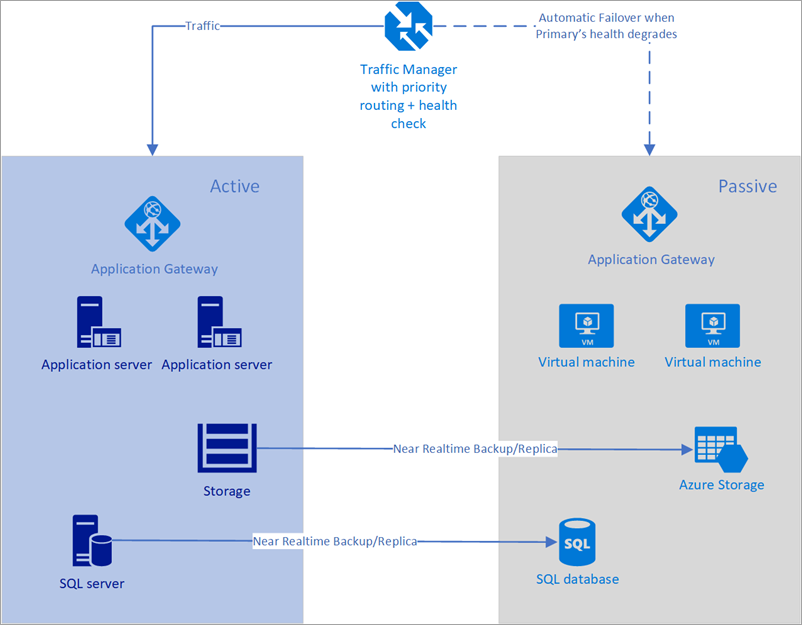
Figure - Automatic failover using Azure Traffic Manager
However, only the primary region is actively handling network requests from the users. The secondary region becomes active only when the primary region experiences a service disruption. In that case, all new network requests route to the secondary region. Since the backup of the database is near instantaneous, both the load balancers have IPs that can be health checked, and the instances are always up and running, this topology provides an option for going in for a low RTO and failover without any manual intervention. The secondary failover region must be ready to go-live immediately after failure of the primary region.
This scenario is ideal for the use of Azure Traffic Manager that has inbuilt probes for various types of health checks including http / https and TCP. Azure Traffic manager also has a rule engine that can be configured to fail over when a failure occurs as described below. Let’s consider the following solution using Traffic Manager:
- Customer has the Region #1 endpoint known as prod.contoso.com with a static IP as 100.168.124.44 and a Region #2 endpoint known as dr.contoso.com with a static IP as 100.168.124.43.
- Each of these environments is fronted via a public facing property like a load balancer. The load balancer can be configured to have a DNS-based endpoint or a fully qualified domain name (FQDN) as shown above.
- All the instances in Region 2 are in near real-time replication with Region 1. Furthermore, the machine images are up to date, and all software/configuration data is patched and are in line with Region 1.
- Autoscaling is preconfigured in advance.
To configure the failover with Azure Traffic Manager:
Create a new Azure Traffic Manager profile Create a new Azure Traffic manager profile with the name contoso123 and select the Routing method as Priority. If you have a pre-existing resource group that you want to associate with, then you can select an existing resource group, otherwise, create a new resource group.
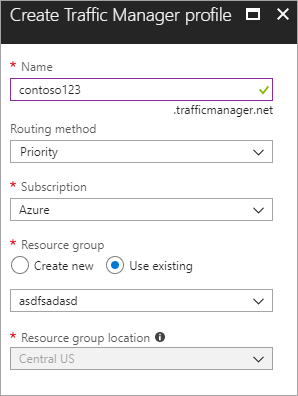
Figure - Create a Traffic Manager profile
Create endpoints within the Traffic Manager profile
In this step, you create endpoints that point to the production and disaster recovery sites. Here, choose the Type as an external endpoint, but if the resource is hosted in Azure, then you can choose Azure endpoint as well. If you choose Azure endpoint, then select a Target resource that is either an App Service or a Public IP that is allocated by Azure. The priority is set as 1 since it's the primary service for Region 1. Similarly, create the disaster recovery endpoint within Traffic Manager as well.
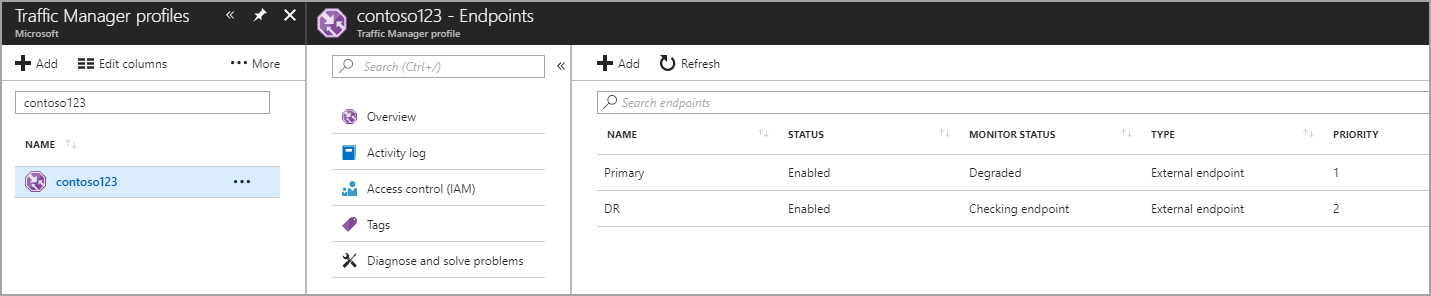
Figure - Create disaster recovery endpoints
Set up health check and failover configuration
In this step, you set the DNS TTL to 10 seconds, which is honored by most internet-facing recursive resolvers. This configuration means that no DNS resolver will cache the information for more than 10 seconds.
For the endpoint monitor settings, the path is current set at / or root, but you can customize the endpoint settings to evaluate a path, for example, prod.contoso.com/index.
The example below shows the https as the probing protocol. However, you can choose http or tcp as well. The choice of protocol depends upon the end application. The probing interval is set to 10 seconds, which enables fast probing, and the retry is set to 3. As a result, Traffic Manager will fail over to the second endpoint if three consecutive intervals register a failure.
The following formula defines the total time for an automated failover:
Time for failover = TTL + Retry * Probing intervalAnd in this case, the value is 10 + 3 * 10 = 40 seconds (Max).
If the Retry is set to 1 and TTL is set to 10 secs, then the time for failover 10 + 1 * 10 = 20 seconds.
Set the Retry to a value greater than 1 to eliminate chances of failovers due to false positives or any minor network blips.
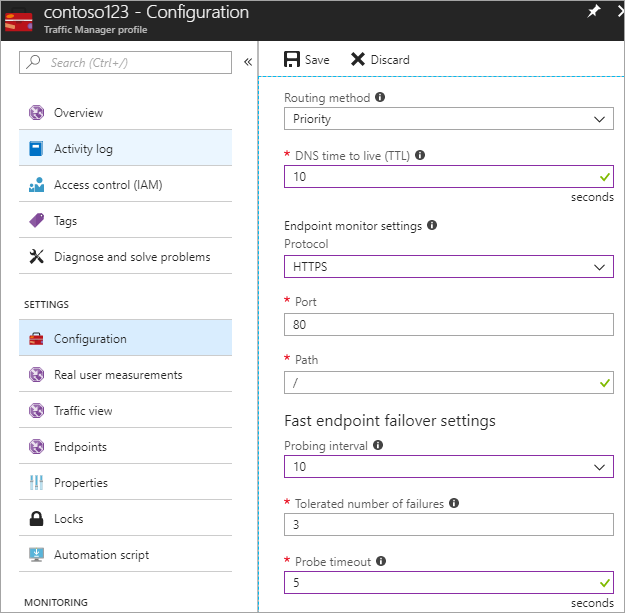
Figure - Set up health check and failover configuration
Next steps
Learn more about Azure Traffic Manager.
Learn more about Azure DNS.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for