How to connect Azure Data Factory and Microsoft Purview
This document explains the steps required for connecting an Azure Data Factory account with a Microsoft Purview account to track data lineage and ingest data sources. The document also gets into the details of the activity coverage scope and supported lineage patterns.
When you connect an Azure Data Factory to Microsoft Purview, whenever a supported Azure Data Factory activity is run, metadata about the activity's source data, output data, and the activity will be automatically ingested into the Microsoft Purview Data Map.
If a data source has already been scanned and exists in the data map, the ingestion process will add the lineage information from Azure Data Factory to that existing source. If the source or output doesn't exist in the data map and is supported by Azure Data Factory lineage Microsoft Purview will automatically add their metadata from Azure Data Factory into the data map under the root collection.
This can be an excellent way to monitor your data estate as users move and transform information using Azure Data Factory.
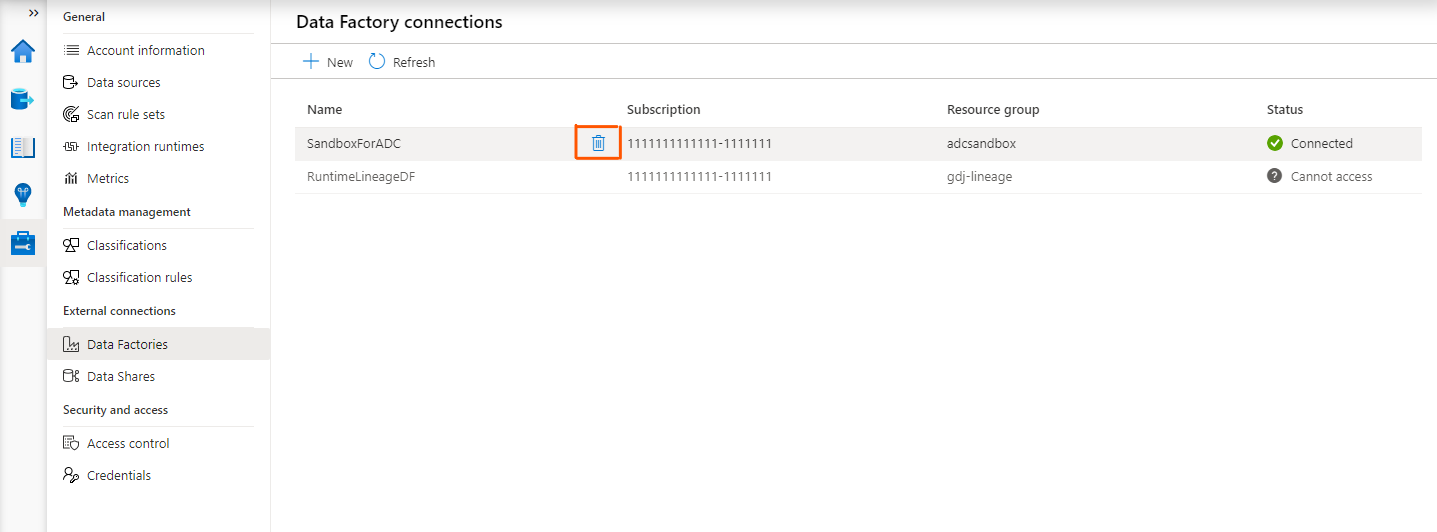
View existing Data Factory connections
Multiple Azure Data Factories can connect to a single Microsoft Purview to push lineage information. The current limit allows you to connect up to 10 Data Factory accounts at a time from the Microsoft Purview management center. To show the list of Data Factory accounts connected to your Microsoft Purview account, do the following:
Select Management on the left navigation pane.
Under Lineage connections, select Data Factory.
The Data Factory connection list appears.

Notice the various values for connection Status:
- Connected: The Data Factory is connected to the Microsoft Purview account.
- Disconnected: The Data Factory has access to the catalog, but it's connected to another catalog. As a result, data lineage won't be reported to the catalog automatically.
- Unknown: The current user doesn't have access to the Data Factory, so the connection status is unknown.

Note
To view the Data Factory connections, you need to be assigned the following role. Role inheritance from management group is not supported. Collection admins role on the root collection.
Create new Data Factory connection
Note
To add or remove the Data Factory connections, you need to be assigned the following role. Role inheritance from management group is not supported. Collection admins role on the root collection.
Also, it requires the users to be the data factory's "Owner" or "Contributor".
Your data factory needs to have system assigned managed identity enabled.
Follow the steps below to connect an existing data factory to your Microsoft Purview account. You can also connect Data Factory to Microsoft Purview account from ADF.
Select Management on the left navigation pane.
Under Lineage connections, select Data Factory.
On the Data Factory connection page, select New.
Select your Data Factory account from the list and select OK. You can also filter by subscription name to limit your list.
Some Data Factory instances might be disabled if the data factory is already connected to the current Microsoft Purview account, or the data factory doesn't have a managed identity.
A warning message will be displayed if any of the selected Data Factories are already connected to other Microsoft Purview account. When you select OK, the Data Factory connection with the other Microsoft Purview account will be disconnected. No other confirmations are required.

Note
We support adding up to 10 Azure Data Factory accounts at once. If you want to add more than 10 data factory accounts, do so in multiple batches.
How authentication works
Data factory's managed identity is used to authenticate lineage push operations from data factory to Microsoft Purview. When you connect your data factory to Microsoft Purview on UI, it adds the role assignment automatically.
Grant the data factory's managed identity Data Curator role on Microsoft Purview root collection. Learn more about Access control in Microsoft Purview and Add roles and restrict access through collections.
Remove Data Factory connections
To remove a data factory connection, do the following:
On the Data Factory connection page, select the Remove button next to one or more data factory connections.
Select Confirm in the popup to delete the selected data factory connections.

Monitor the Data Factory links
In Microsoft Purview governance portal, you can monitor the Data Factory links.
Supported Azure Data Factory activities
Microsoft Purview captures runtime lineage from the following Azure Data Factory activities:
Important
Microsoft Purview drops lineage if the source or destination uses an unsupported data storage system.
The integration between Data Factory and Microsoft Purview supports only a subset of the data systems that Data Factory supports, as described in the following sections.
Copy activity support
| Data store | Supported |
|---|---|
| Azure Blob Storage | Yes |
| Azure Cognitive Search | Yes |
| Azure Cosmos DB for NoSQL * | Yes |
| Azure Cosmos DB for MongoDB * | Yes |
| Azure Data Explorer * | Yes |
| Azure Data Lake Storage Gen1 | Yes |
| Azure Data Lake Storage Gen2 | Yes |
| Azure Database for MariaDB * | Yes |
| Azure Database for MySQL * | Yes |
| Azure Database for PostgreSQL * | Yes |
| Azure Files | Yes |
| Azure SQL Database * | Yes |
| Azure SQL Managed Instance * | Yes |
| Azure Synapse Analytics * | Yes |
| Azure Dedicated SQL pool (formerly SQL DW) * | Yes |
| Azure Table Storage | Yes |
| Amazon S3 | Yes |
| Hive * | Yes |
| Oracle * | Yes |
| SAP Table (when connecting to SAP ECC or SAP S/4HANA) | Yes |
| SQL Server * | Yes |
| Teradata * | Yes |
* Microsoft Purview currently doesn't support query or stored procedure for lineage or scanning. Lineage is limited to table and view sources only.
If you use Self-hosted Integration Runtime, note the minimal version with lineage support for:
- Any use case: version 5.9.7885.3 or later
- Copying data from Oracle: version 5.10 or later
- Copying data into Azure Synapse Analytics via COPY command or PolyBase: version 5.10 or later
Limitations on copy activity lineage
Currently, if you use the following copy activity features, the lineage is not yet supported:
- Copy data into Azure Data Lake Storage Gen1 using Binary format.
- Compression setting for Binary, delimited text, Excel, JSON, and XML files.
- Source partition options for Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server, and SAP Table.
- Copy data to file-based sink with setting of max rows per file.
- Column level lineage is not currently supported by copy activity when source/sink is resource set.
In additional to lineage, the data asset schema (shown in Asset -> Schema tab) is reported for the following connectors:
- CSV and Parquet files on Azure Blob, Azure Files, ADLS Gen1, ADLS Gen2, and Amazon S3
- Azure Data Explorer, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server, Teradata
Data Flow support
| Data store | Supported |
|---|---|
| Azure Blob Storage | Yes |
| Azure Cosmos DB for NoSQL * | Yes |
| Azure Data Lake Storage Gen1 | Yes |
| Azure Data Lake Storage Gen2 | Yes |
| Azure Database for MySQL * | Yes |
| Azure Database for PostgreSQL * | Yes |
| Azure SQL Database * | Yes |
| Azure SQL Managed Instance * | Yes |
| Azure Synapse Analytics * | Yes |
| Azure Dedicated SQL pool (formerly SQL DW) * | Yes |
* Microsoft Purview currently doesn't support query or stored procedure for lineage or scanning. Lineage is limited to table and view sources only.
Limitations on data flow lineage
- Data flow lineage may generate folder level resource set without visibility on the involved files.
- Column level lineage is not currently supported when source/sink is resource set.
- For the lineage of data flow activity, Microsoft Purview only supports showing the source and sink involved. The detailed lineage for data flow transformation isn't supported yet.
- Lineage is not supported when flowlets are part of the dataflow.
- Currently Purview doesn't support lineage reporting for Synapse tables (LakeHouse DB/Workspace DB)
Execute SSIS Package support
Refer to supported data stores.
Access secured Microsoft Purview account
If your Microsoft Purview account is protected by firewall, learn how to let Data Factory access a secured Microsoft Purview account through Microsoft Purview private endpoints.
Bring Data Factory lineage into Microsoft Purview
For an end to end walkthrough, follow the Tutorial: Push Data Factory lineage data to Microsoft Purview.
Supported lineage patterns
There are several patterns of lineage that Microsoft Purview supports. The generated lineage data is based on the type of source and sink used in the Data Factory activities. Although Data Factory supports over 80 source and sinks, Microsoft Purview supports only a subset, as listed in Supported Azure Data Factory activities.
To configure Data Factory to send lineage information, see Get started with lineage.
Some other ways of finding information in the lineage view, include the following:
- In the Lineage tab, hover on shapes to preview additional information about the asset in the tooltip.
- Select the node or edge to see the asset type it belongs or to switch assets.
- Columns of a dataset are displayed in the left side of the Lineage tab. For more information about column-level lineage, see Dataset column lineage.
Data lineage for 1:1 operations
The most common pattern for capturing data lineage, is moving data from a single input dataset to a single output dataset, with a process in between.
An example of this pattern would be the following:
- 1 source/input: Customer (SQL Table)
- 1 sink/output: Customer1.csv (Azure Blob)
- 1 process: CopyCustomerInfo1#Customer1.csv (Data Factory Copy activity)

Data movement with 1:1 lineage and wildcard support
Another common scenario for capturing lineage is using a wildcard to copy files from a single input dataset to a single output dataset. The wildcard allows the copy activity to match multiple files for copying using a common portion of the file name. Microsoft Purview captures file-level lineage for each individual file copied by the corresponding copy activity.
An example of this pattern would be the following:
- Source/input: CustomerCall*.csv (ADLS Gen2 path)
- Sink/output: CustomerCall*.csv (Azure blob file)
- 1 process: CopyGen2ToBlob#CustomerCall.csv (Data Factory Copy activity)

Data movement with n:1 lineage
You can use Data Flow activities to perform data operations like merge, join, and so on. More than one source dataset can be used to produce a target dataset. In this example, Microsoft Purview captures file-level lineage for individual input files to a SQL table that is part of a Data Flow activity.
An example of this pattern would be the following:
- 2 sources/inputs: Customer.csv, Sales.parquet (ADLS Gen2 Path)
- 1 sink/output: Company data (Azure SQL table)
- 1 process: DataFlowBlobsToSQL (Data Factory Data Flow activity)

Lineage for resource sets
A resource set is a logical object in the catalog that represents many partition files in the underlying storage. For more information, see Understanding Resource sets. When Microsoft Purview captures lineage from the Azure Data Factory, it applies the rules to normalize the individual partition files and create a single logical object.
In the following example, an Azure Data Lake Gen2 resource set is produced from an Azure Blob:
- 1 source/input: Employee_management.csv (Azure Blob)
- 1 sink/output: Employee_management.csv (Azure Data Lake Gen 2)
- 1 process: CopyBlobToAdlsGen2_RS (Data Factory Copy activity)

Next steps
Tutorial: Push Data Factory lineage data to Microsoft Purview
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for