Connect to and manage Google BigQuery projects in Microsoft Purview
This article outlines how to register Google BigQuery projects, and how to authenticate and interact with Google BigQuery in Microsoft Purview. For more information about Microsoft Purview, read the introductory article.
Supported capabilities
| Metadata Extraction | Full Scan | Incremental Scan | Scoped Scan | Classification | Labeling | Access Policy | Lineage | Data Sharing | Live view |
|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | No | Yes | No | No | No | Yes | No | No |
When scanning Google BigQuery source, Microsoft Purview supports:
Extracting technical metadata including:
- Projects
- Datasets
- Tables including the columns
- Views including the columns
Fetching static lineage on assets relationships among tables and views.
When setting up scan, you can choose to scan an entire Google BigQuery project, or scope the scan to a subset of datasets matching the given name(s) or name pattern(s).
Known limitations
- Currently, Microsoft Purview only supports scanning Google BigQuery datasets in US multi-regional location. If the specified dataset is in other location e.g. us-east1 or EU, you will observe scan completes but no assets shown up in Microsoft Purview.
- When object is deleted from the data source, currently the subsequent scan won't automatically remove the corresponding asset in Microsoft Purview.
Prerequisites
An Azure account with an active subscription. Create an account for free.
An active Microsoft Purview account.
You need Data Source Administrator and Data Reader permissions to register a source and manage it in the Microsoft Purview governance portal. For more information about permissions, see Access control in Microsoft Purview.
Set up the latest self-hosted integration runtime. For more information, see the create and configure a self-hosted integration runtime guide.
Ensure JDK 11 is installed on the machine where the self-hosted integration runtime is installed. Restart the machine after you newly install the JDK for it to take effect.
Ensure Visual C++ Redistributable (version Visual Studio 2012 Update 4 or newer) is installed on the self-hosted integration runtime machine. If you don't have this update installed, you can download it here.
Download and unzip the BigQuery JDBC driver on the machine where your self-hosted integration runtime is running. Note down the folder path which you will use to set up the scan.
Note
The driver should be accessible by the self-hosted integration runtime. By default, self-hosted integration runtime uses local service account "NT SERVICE\DIAHostService". Make sure it has "Read and execute" and "List folder contents" permission to the driver folder.
Required permissions for scan
The Google BigQuery service account you use for scan needs to have both BigQuery Metadata Viewer and BigQuery Job User IAM roles on the project(s) you want to scan. These permissions are required because Microsoft Purview extracts the metadata by reading the Google BigQuery database system tables (e.g. INFORMATION_SCHEMA). And the underlying Google BigQuery JDBC driver creates a BigQuery job when it needs to read from these system tables.
Microsoft Purview uses Oauth 2.0 protocol for accessing Google BigQuery service. Set up the credential by following the instruction in Create and run scan section.
Register
This section describes how to register a Google BigQuery project in Microsoft Purview using the Microsoft Purview governance portal.
Steps to register
Open the Microsoft Purview governance portal by:
- Browsing directly to https://web.purview.azure.com and selecting your Microsoft Purview account.
- Opening the Azure portal, searching for and selecting the Microsoft Purview account. Selecting the the Microsoft Purview governance portal button.
Select Data Map on the left navigation.
Select Register.
On Register sources, select Google BigQuery . Select Continue.

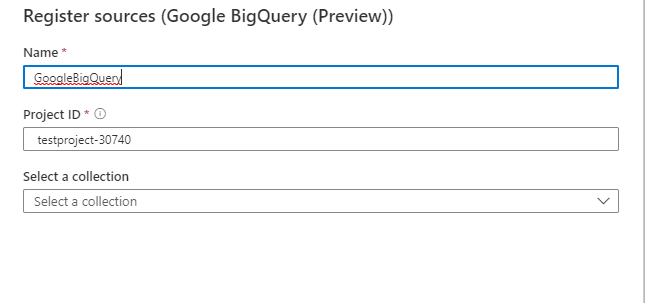
On the Register sources (Google BigQuery) screen, do the following:
Enter a Name that the data source will be listed within the Catalog.
Enter the ProjectID. This should be a fully qualified project ID. For example, mydomain.com:myProject
Select a collection from the list.
Select Register.
Scan
Follow the steps below to scan a Google BigQuery project to automatically identify assets. For more information about scanning in general, see our introduction to scans and ingestion.
Create and run scan
In the Management Center, select Integration runtimes. Make sure a self-hosted integration runtime is set up. If it isn't set up, use the steps mentioned here.
Navigate to Sources.
Select the registered BigQuery project.
Select + New scan.
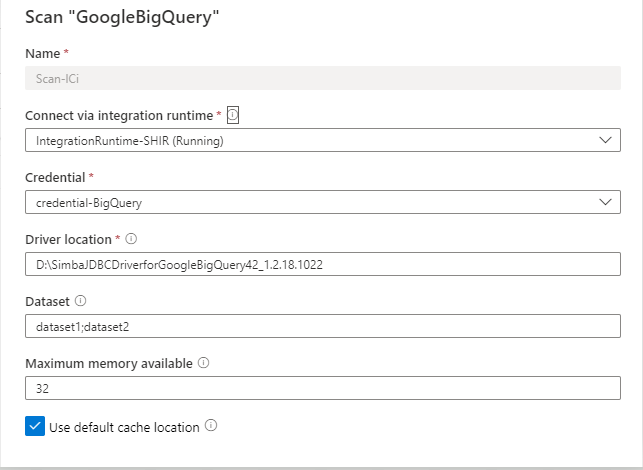
Provide the below details:
Name: The name of the scan
Connect via integration runtime: Select the configured self-hosted integration runtime
Credential: While configuring BigQuery credential, make sure to:
- Select Basic Authentication as the Authentication method
- Provide the email ID of the service account in the User name field. For example,
xyz\@developer.gserviceaccount.com - Follow below steps to generate the private key, copy the entire JSON key file then store it as the value of a Key Vault secret.
To create a new private key from Google's cloud platform:
- In the navigation menu, select IAM & Admin -> Service Accounts -> Select a project ->
- Select the email address of the service account that you want to create a key for.
- Select the Keys tab.
- Select the Add key drop-down menu, then select Create new key.
- Choose JSON format.
Note
The contents of the private key are saved in a temp file on the VM when scanning processes are running. This temp file is deleted after the scans are successfully completed. In the event of a scan failure, the system will continue to retry until success. Please make sure access is appropriately restricted on the VM where SHIR is running.
To understand more on credentials, refer to the link here.
Driver location: Specify the path to the JDBC driver location in your machine where self-host integration runtime is running, e.g.
D:\Drivers\GoogleBigQuery. It's the path to valid JAR folder location. The value must be a valid absolute file path and does not contain space. Make sure the driver is accessible by the self-hosted integration runtime, learn more from prerequisites section.Dataset: Specify a list of BigQuery datasets to import. For example,
dataset1;dataset2. When the list is empty, all available datasets are imported. Acceptable dataset name patterns can be static names or contain wildcard %.Example:
A%;%B;%C%;D- Start with A or
- end with B or
- contain C or
- equal D
Usage of NOT and special characters aren't acceptable.
Maximum memory available: Maximum memory (in GB) available on your VM to be used by scanning processes. This is dependent on the size of Google BigQuery project to be scanned.
Select Test connection.
Select Continue.
Choose your scan trigger. You can set up a schedule or ran the scan once.
Review your scan and select Save and Run.
View your scans and scan runs
To view existing scans:
- Go to the Microsoft Purview portal. On the left pane, select Data map.
- Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
- Select the scan that has results you want to view. The pane shows you all the previous scan runs, along with the status and metrics for each scan run.
- Select the run ID to check the scan run details.
Manage your scans
To edit, cancel, or delete a scan:
Go to the Microsoft Purview portal. On the left pane, select Data Map.
Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
Select the scan that you want to manage. You can then:
- Edit the scan by selecting Edit scan.
- Cancel an in-progress scan by selecting Cancel scan run.
- Delete your scan by selecting Delete scan.
Note
- Deleting your scan does not delete catalog assets created from previous scans.
Lineage
After scanning your Google BigQuery source, you can browse data catalog or search data catalog to view the asset details.
Go to the asset -> lineage tab, you can see the asset relationship when applicable. Refer to the supported capabilities section on the supported Google BigQuery lineage scenarios. For more information about lineage in general, see data lineage and lineage user guide.

Next steps
Now that you've registered your source, follow the below guides to learn more about Microsoft Purview and your data.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for