Choose a programming language for the next step. The Azure.Search.Documents client libraries are available in Azure SDKs for .NET, Python, Java, and JavaScript.
Build a console application using the Azure.Search.Documents client library to create, load, and query a search index. Alternatively, you can download the source code to start with a finished project or follow these steps to create your own.
Set up your environment
Start Visual Studio and create a new project for a console app.
In Tools > NuGet Package Manager, select Manage NuGet Packages for Solution....
Select Browse.
Search for Azure.Search.Documents package and select version 11.0 or later.
Select Install on the right to add the assembly to your project and solution.
Create a search client
In Program.cs, change the namespace to AzureSearch.SDK.Quickstart.v11 and then add the following using directives.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
Create two clients: SearchIndexClient creates the index, and SearchClient loads and queries an existing index. Both need the service endpoint and an admin API key for authentication with create/delete rights.
Because the code builds out the URI for you, specify just the search service name in the "serviceName" property.
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
Create an index
This quickstart builds a Hotels index that you'll load with hotel data and execute queries against. In this step, define the fields in the index. Each field definition includes a name, data type, and attributes that determine how the field is used.
In this example, synchronous methods of the Azure.Search.Documents library are used for simplicity and readability. However, for production scenarios, you should use asynchronous methods to keep your app scalable and responsive. For example, you would use CreateIndexAsync instead of CreateIndex.
Add an empty class definition to your project: Hotel.cs
Copy the following code into Hotel.cs to define the structure of a hotel document. Attributes on the field determine how it's used in an application. For example, the IsFilterable attribute must be assigned to every field that supports a filter expression.
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
In the Azure.Search.Documents client library, you can use SearchableField and SimpleField to streamline field definitions. Both are derivatives of a SearchField and can potentially simplify your code:
SimpleField can be any data type, is always non-searchable (it's ignored for full text search queries), and is retrievable (it's not hidden). Other attributes are off by default, but can be enabled. You might use a SimpleField for document IDs or fields used only in filters, facets, or scoring profiles. If so, be sure to apply any attributes that are necessary for the scenario, such as IsKey = true for a document ID. For more information, see SimpleFieldAttribute.cs in source code.
SearchableField must be a string, and is always searchable and retrievable. Other attributes are off by default, but can be enabled. Because this field type is searchable, it supports synonyms and the full complement of analyzer properties. For more information, see the SearchableFieldAttribute.cs in source code.
Whether you use the basic SearchField API or either one of the helper models, you must explicitly enable filter, facet, and sort attributes. For example, IsFilterable, IsSortable, and IsFacetable must be explicitly attributed, as shown in the sample above.
Add a second empty class definition to your project: Address.cs. Copy the following code into the class.
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
Create two more classes: Hotel.Methods.cs and Address.Methods.cs for ToString() overrides. These classes are used to render search results in the console output. The contents of these classes aren't provided in this article, but you can copy the code from files in GitHub.
In Program.cs, create a SearchIndex object, and then call the CreateIndex method to express the index in your search service. The index also includes a SearchSuggester to enable autocomplete on the specified fields.
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
Load documents
Azure AI Search searches over content stored in the service. In this step, you'll load JSON documents that conform to the hotel index you just created.
In Azure AI Search, search documents are data structures that are both inputs to indexing and outputs from queries. As obtained from an external data source, document inputs might be rows in a database, blobs in Blob storage, or JSON documents on disk. In this example, we're taking a shortcut and embedding JSON documents for four hotels in the code itself.
When uploading documents, you must use an IndexDocumentsBatch object. An IndexDocumentsBatch object contains a collection of Actions, each of which contains a document and a property telling Azure AI Search what action to perform (upload, merge, delete, and mergeOrUpload).
In Program.cs, create an array of documents and index actions, and then pass the array to IndexDocumentsBatch. The documents below conform to the hotels-quickstart index, as defined by the hotel class.
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Secret Point Motel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Twin Dome Motel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Triple Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Cliff Hotel",
Description = "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
Once you initialize the IndexDocumentsBatch object, you can send it to the index by calling IndexDocuments on your SearchClient object.
Add the following lines to Main(). Loading documents is done using SearchClient, but the operation also requires admin rights on the service, which is typically associated with SearchIndexClient. One way to set up this operation is to get SearchClient through SearchIndexClient (adminClient in this example).
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
Because this is a console app that runs all commands sequentially, add a 2-second wait time between indexing and queries.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
The 2-second delay compensates for indexing, which is asynchronous, so that all documents can be indexed before the queries are executed. Coding in a delay is typically only necessary in demos, tests, and sample applications.
Search an index
You can get query results as soon as the first document is indexed, but actual testing of your index should wait until all documents are indexed.
This section adds two pieces of functionality: query logic, and results. For queries, use the Search method. This method takes search text (the query string) and other options.
The SearchResults class represents the results.
In Program.cs, create a WriteDocuments method that prints search results to the console.
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
Create a RunQueries method to execute queries and return results. Results are Hotel objects. This sample shows the method signature and the first query. This query demonstrates the Select parameter that lets you compose the result using selected fields from the document.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
In the second query, search on a term, add a filter that selects documents where Rating is greater than 4, and then sort by Rating in descending order. Filter is a boolean expression that is evaluated over IsFilterable fields in an index. Filter queries either include or exclude values. As such, there's no relevance score associated with a filter query.
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
The third query demonstrates searchFields, used to scope a full text search operation to specific fields.
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
The fourth query demonstrates facets, which can be used to structure a faceted navigation structure.
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
In the fifth query, return a specific document. A document lookup is a typical response to OnClick event in a result set.
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
The last query shows the syntax for autocomplete, simulating a partial user input of "sa" that resolves to two possible matches in the sourceFields associated with the suggester you defined in the index.
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
Add RunQueries to Main().
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
The previous queries show multiple ways of matching terms in a query: full-text search, filters, and autocomplete.
Full text search and filters are performed using the SearchClient.Search method. A search query can be passed in the searchText string, while a filter expression can be passed in the Filter property of the SearchOptions class. To filter without searching, just pass "*" for the searchText parameter of the Search method. To search without filtering, leave the Filter property unset, or don't pass in a SearchOptions instance at all.
Run the program
Press F5 to rebuild the app and run the program in its entirety.
Output includes messages from Console.WriteLine, with the addition of query information and results.
Use a Jupyter notebook and the azure-search-documents library in the Azure SDK for Python to create, load, and query a search index.
Alternatively, download and run a finished notebook.
Set up your environment
Use Visual Studio Code with the Python extension, or equivalent IDE, with Python 3.10 or later.
We recommend a virtual environment for this quickstart:
Start Visual Studio Code.
Open the Command Palette (Ctrl+Shift+P).
Search for Python: Create Environment.
Select Venv.
Select a Python interpreter. Choose 3.10 or later.
It can take a minute to set up. If you run into problems, see Python environments in VS Code.
Install packages and set variables
Install packages, including azure-search-documents.
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
Provide endpoint and API keys:
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
Create an index
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index=
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
Create a documents payload
Use an index action for the operation type (upload, merge-and-upload, and so forth). Documents originate from HotelsData on GitHub.
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Secret Point Motel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Twin Dome Motel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Triple Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Cliff Hotel",
"Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
"Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
Upload documents
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
Run your first query
Use the search method of the search.client class.
This example executes an empty search (search=*), returning an unranked list (search score = 1.0) of arbitrary documents. Because there are no criteria, all documents are included in results.
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Run a term query
The next query adds whole terms to the search expression ("wifi"). This query specifies that results contain only those fields in the select statement. Limiting the fields that come back minimizes the amount of data sent back over the wire and reduces search latency.
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Add a filter
Add a filter expression, returning only those hotels with a rating greater than four, sorted in descending order.
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
Add field scoping
Add search_fields to scope query execution to specific fields.
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
Add facets
Facets are generated for positive matches found in search results. There are no zero matches. If search results don't include the term "wifi", then "wifi" doesn't appear in the faceted navigation structure.
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
Look up a document
Return a document based on its key. This operation is useful if you want to provide drill through when a user selects an item in a search result.
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
Add autocomplete
Autocomplete can provide potential matches as the user types into the search box.
Autocomplete uses a suggester (sg) to know which fields contain potential matches to suggester requests. In this quickstart, those fields are Tags, Address/City, Address/Country.
To simulate autocomplete, pass in the letters "sa" as a partial string. The autocomplete method of SearchClient sends back potential term matches.
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Build a Java console application using the Azure.Search.Documents library to create, load, and query a search index. Alternatively, you can download the source code to start with a finished project or follow these steps to create your own.
Set up your environment
We used the following tools to create this quickstart.
Create the project
Start Visual Studio Code.
Open the Command Palette Ctrl+Shift+P. Search for Create Java Project.

Select Maven.
Select maven-archetype-quickstart.
Select the latest version, currently 1.4.

Enter azure.search.sample as the group ID.
Enter azuresearchquickstart as the artifact ID.

Select the folder to create the project in.
Finish project creation in the integrated terminal. Press enter to accept the default for "1.0-SNAPSHOT" and then type "y" to confirm the properties for your project.
Open the folder you created the project in.
Specify Maven dependencies
Open the pom.xml file and add the following dependencies
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.5.2</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.34.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Change the compiler Java version to 11
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
Create a search client
Open the App class under src, main, java, azure, search, sample. Add the following import directives
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
The following example includes placeholders for a search service name, admin API key that grants create and delete permissions, and index name. Substitute valid values for all three placeholders. Create two clients: SearchIndexClient creates the index, and SearchClient loads and queries an existing index. Both need the service endpoint and an admin API key for authentication with create and delete rights.
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
Create an index
This quickstart builds a Hotels index that you'll load with hotel data and execute queries against. In this step, define the fields in the index. Each field definition includes a name, data type, and attributes that determine how the field is used.
In this example, synchronous methods of the azure-search-documents library are used for simplicity and readability. However, for production scenarios, you should use asynchronous methods to keep your app scalable and responsive. For example, you would use SearchAsyncClient instead of SearchClient.
Add an empty class definition to your project: Hotel.java
Copy the following code into Hotel.java to define the structure of a hotel document. Attributes on the field determine how it's used in an application. For example, the IsFilterable annotation must be assigned to every field that supports a filter expression
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
In the Azure.Search.Documents client library, you can use SearchableField and SimpleField to streamline field definitions.
SimpleField can be any data type, is always non-searchable (it's ignored for full text search queries), and is retrievable (it's not hidden). Other attributes are off by default, but can be enabled. You might use a SimpleField for document IDs or fields used only in filters, facets, or scoring profiles. If so, be sure to apply any attributes that are necessary for the scenario, such as IsKey = true for a document ID.SearchableField must be a string, and is always searchable and retrievable. Other attributes are off by default, but can be enabled. Because this field type is searchable, it supports synonyms and the full complement of analyzer properties.
Whether you use the basic SearchField API or either one of the helper models, you must explicitly enable filter, facet, and sort attributes. For example, isFilterable, isSortable, and isFacetable must be explicitly attributed, as shown in the sample above.
Add a second empty class definition to your project: Address.cs. Copy the following code into the class.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
In App.java, create a SearchIndex object in the main method, and then call the createOrUpdateIndex method to create the index in your search service. The index also includes a SearchSuggester to enable autocomplete on the specified fields.
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
Load Documents
Azure AI Search searches over content stored in the service. In this step, you'll load JSON documents that conform to the hotel index you just created.
In Azure AI Search, search documents are data structures that are both inputs to indexing and outputs from queries. As obtained from an external data source, document inputs might be rows in a database, blobs in Blob storage, or JSON documents on disk. In this example, we're taking a shortcut and embedding JSON documents for four hotels in the code itself.
When uploading documents, you must use an IndexDocumentsBatch object. An IndexDocumentsBatch object contains a collection of IndexActions, each of which contains a document and a property telling Azure AI Search what action to perform (upload, merge, delete, and mergeOrUpload).
In App.java, create documents and index actions, and then pass them to IndexDocumentsBatch. The documents below conform to the hotels-quickstart index, as defined by the hotel class.
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Secret Point Motel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Twin Dome Motel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Triple Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Cliff Hotel";
hotel.description = "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
Once you initialize the IndexDocumentsBatch object, you can send it to the index by calling indexDocuments on your SearchClient object.
Add the following lines to Main(). Loading documents is done using SearchClient.
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
Because this is a console app that runs all commands sequentially, add a 2-second wait time between indexing and queries.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
The 2-second delay compensates for indexing, which is asynchronous, so that all documents can be indexed before the queries are executed. Coding in a delay is typically only necessary in demos, tests, and sample applications.
Search an index
You can get query results as soon as the first document is indexed, but actual testing of your index should wait until all documents are indexed.
This section adds two pieces of functionality: query logic, and results. For queries, use the Search method. This method takes search text (the query string) and other options.
In App.java, create a WriteDocuments method that prints search results to the console.
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
Create a RunQueries method to execute queries and return results. Results are Hotel objects. This sample shows the method signature and the first query. This query demonstrates the Select parameter that lets you compose the result using selected fields from the document.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
In the second query, search on a term, add a filter that selects documents where Rating is greater than 4, and then sort by Rating in descending order. Filter is a boolean expression that is evaluated over isFilterable fields in an index. Filter queries either include or exclude values. As such, there's no relevance score associated with a filter query.
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
The third query demonstrates searchFields, used to scope a full text search operation to specific fields.
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
The fourth query demonstrates facets, which can be used to structure a faceted navigation structure.
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
In the fifth query, return a specific document.
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
The last query shows the syntax for autocomplete, simulating a partial user input of "s" that resolves to two possible matches in the sourceFields associated with the suggester you defined in the index.
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
Add RunQueries to Main().
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
The previous queries show multiple ways of matching terms in a query: full-text search, filters, and autocomplete.
Full text search and filters are performed using the SearchClient.search method. A search query can be passed in the searchText string, while a filter expression can be passed in the filter property of the SearchOptions class. To filter without searching, just pass "*" for the searchText parameter of the search method. To search without filtering, leave the filter property unset, or don't pass in a SearchOptions instance at all.
Run the program
Press F5 to rebuild the app and run the program in its entirety.
Output includes messages from System.out.println, with the addition of query information and results.
Build a Node.js application using the @azure/search-documents library to create, load, and query a search index. Alternatively, you can download the source code to start with a finished project or follow these steps to create your own.
Set up your environment
We used the following tools to create this quickstart.
Create the project
Start Visual Studio Code.
Open the Command Palette Ctrl+Shift+P and open the integrated terminal.
Create a development directory, giving it the name quickstart :
mkdir quickstart
cd quickstart
Initialize an empty project with npm by running the following command. To fully initialize the project, press Enter multiple times to accept the default values, except for the License, which you should set to "MIT".
npm init
Install @azure/search-documents, the JavaScript/TypeScript SDK for Azure AI Search.
npm install @azure/search-documents
Install dotenv, which is used to import the environment variables such as your search service name and API key.
npm install dotenv
Confirm that you've configured the projects and its dependencies by checking that your package.json file looks similar to the following json:
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
Create a file .env to hold your search service parameters:
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Replace the <search-service-name> value with the name of your search service. Replace <search-admin-key> with the key value you recorded earlier.
Create index.js file
Next we create an index.js file, which is the main file that will host our code.
At the top of this file, we import the @azure/search-documents library:
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
Next, we need to require the dotenv package to read in the parameters from the .env file as follows:
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
With our imports and environment variables in place, we're ready to define the main function.
Most of the functionality in the SDK is asynchronous so we make our main function async. We also include a main().catch() below the main function to catch and log any errors encountered:
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
With that in place, we're ready to create an index.
Create index
Create a file hotels_quickstart_index.json. This file defines how Azure AI Search works with the documents you'll be loading in the next step. Each field will be identified by a name and have a specified type. Each field also has a series of index attributes that specify whether Azure AI Search can search, filter, sort, and facet upon the field. Most of the fields are simple data types, but some, like AddressType are complex types that allow you to create rich data structures in your index. You can read more about supported data types and index attributes described in Create Index (REST).
Add the following content to hotels_quickstart_index.json or download the file.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
With our index definition in place, we want to import hotels_quickstart_index.json at the top of index.js so the main function can access the index definition.
const indexDefinition = require('./hotels_quickstart_index.json');
Within the main function, we then create a SearchIndexClient, which is used to create and manage indexes for Azure AI Search.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
Next, we want to delete the index if it already exists. This operation is a common practice for test/demo code.
We do this by defining a simple function that tries to delete the index.
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
To run the function, we extract the index name from the index definition and pass the indexName along with the indexClient to the deleteIndexIfExists() function.
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
After that, we're ready to create the index with the createIndex() method.
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
Run the sample
At this point, you're ready to run the sample. Use a terminal window to run the following command:
node index.js
If you downloaded the source code and haven't installed the required packages yet, run npm install first.
You should see a series of messages describing the actions being taken by the program.
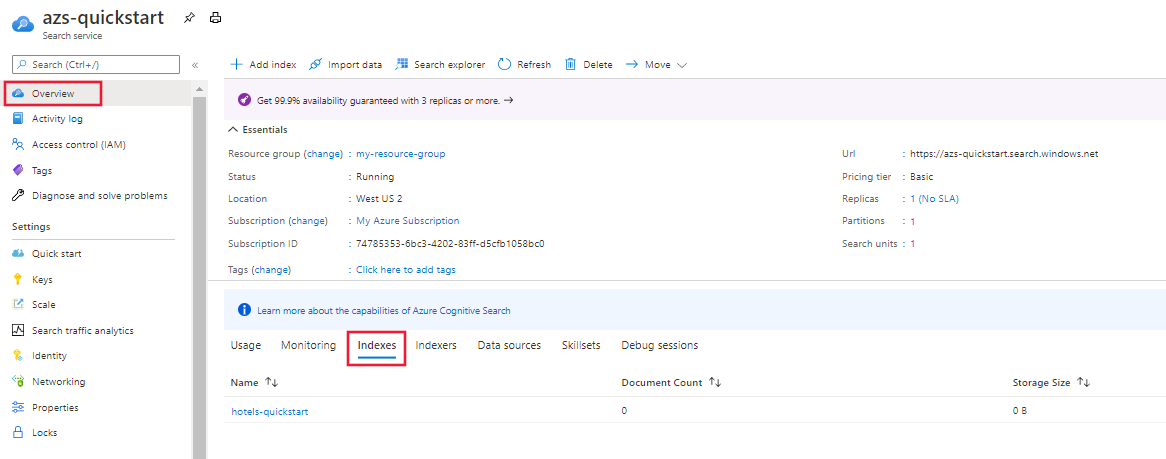
Open the Overview of your search service in the Azure portal. Select the Indexes tab. You should see something like the following example:
In the next step, you'll add data to index.
Load documents
In Azure AI Search, documents are data structures that are both inputs to indexing and outputs from queries. You can push such data to the index or use an indexer. In this case, we'll programatically push the documents to the index.
Document inputs might be rows in a database, blobs in Blob storage, or, as in this sample, JSON documents on disk. You can either download hotels.json or create your own hotels.json file with the following content:
{
"value": [
{
"HotelId": "1",
"HotelName": "Secret Point Motel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Twin Dome Motel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Triple Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Cliff Hotel",
"Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.",
"Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
Similar to what we did with the indexDefinition, we also need to import hotels.json at the top of index.js so that the data can be accessed in our main function.
const hotelData = require('./hotels.json');
To index data into the search index, we now need to create a SearchClient. While the SearchIndexClient is used to create and manage an index, the SearchClient is used to upload documents and query the index.
There are two ways to create a SearchClient. The first option is to create a SearchClient from scratch:
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
Alternatively, you can use the getSearchClient() method of the SearchIndexClient to create the SearchClient:
const searchClient = indexClient.getSearchClient(indexName);
Now that the client is defined, upload the documents into the search index. In this case, we use the mergeOrUploadDocuments() method, which will upload the documents or merge them with an existing document if a document with the same key already exists.
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Run the program again with node index.js. You should see a slightly different set of messages from those you saw in Step 1. This time, the index does exist, and you should see a message about deleting it before the app creates the new index and posts data to it.
Before we run the queries in the next step, define a function to have the program wait for one second. This is done just for test/demo purposes to ensure the indexing finishes and that the documents are available in the index for our queries.
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
To have the program wait for one second, call the sleep function like below:
sleep(1000);
Search an index
With an index created and documents uploaded, you're ready to send queries to the index. In this section, we'll send five different queries to the search index to demonstrate different pieces of query functionality available to you.
The queries are written in a sendQueries() function that we'll call in the main function as follows:
await sendQueries(searchClient);
Queries are sent using the search() method of searchClient. The first parameter is the search text and the second parameter specifies search options.
The first query searches *, which is equivalent to searching everything and selects three of the fields in the index. It's a best practice to only select the fields you need because pulling back unnecessary data can add latency to your queries.
The searchOptions for this query also has includeTotalCount set to true, which will return the number of matching results found.
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
The remaining queries outlined below should also be added to the sendQueries() function. They're separated here for readability.
In the next query, we specify the search term "wifi" and also include a filter to only return results where the state is equal to 'FL'. Results are also ordered by the Hotel's Rating.
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Next, the search is limited to a single searchable field using the searchFields parameter. This approach is a great option to make your query more efficient if you know you're only interested in matches in certain fields.
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("sublime cliff", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
Another common option to include in a query is facets. Facets allow you to build out filters on your UI to make it easy for users to know what values they can filter down to.
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
The final query uses the getDocument() method of the searchClient. This allows you to efficiently retrieve a document by its key.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Run the sample
Run the program with node index.js. Now, in addition to the previous steps, the queries will be sent and the results written to the console.
When you're working in your own subscription, it's a good idea at the end of a project to identify whether you still need the resources you created. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
If you're using a free service, remember that you're limited to three indexes, indexers, and data sources. You can delete individual items in the portal to stay under the limit.
In this quickstart, you worked through a set of tasks to create an index, load it with documents, and run queries. At different stages, we took shortcuts to simplify the code for readability and comprehension. Now that you're familiar with the basic concepts, try a tutorial that calls the Azure AI Search APIs in a web app.
