Defragmentation of metrics and load in Service Fabric
The Service Fabric Cluster Resource Manager's default strategy for managing load metrics in the cluster is to distribute the load. Ensuring that nodes are evenly utilized avoids hot and cold spots that lead to both contention and wasted resources. Distributing workloads in the cluster is also the safest in terms of surviving failures since it ensures that a failure doesn’t take out a large percentage of a given workload.
The Service Fabric Cluster Resource Manager does support a different strategy for managing load, which is defragmentation. Defragmentation means that instead of trying to distribute the utilization of a metric across the cluster, it is consolidated. Consolidation is just an inversion of the default balancing strategy – instead of minimizing the average standard deviation of metric load, the Cluster Resource Manager tries to increase it.
When to use defragmentation
Distributing load in the cluster consumes some of the resources on each node. Some workloads create services that are exceptionally large and consume most or all of a node. In these cases, it's possible that when there are large workloads getting created that there isn't enough space on any node to run them. Large workloads aren't a problem in Service Fabric; in these cases the Cluster Resource Manager determines that it needs to reorganize the cluster to make room for this large workload. However, in the meantime that workload has to wait to be scheduled in the cluster.
If there are many services and state to move around, then it could take a long time for the large workload to be placed in the cluster. This is more likely if other workloads in the cluster are also large and so take longer to reorganize. The Service Fabric team measured creation times in simulations of this scenario. We found that creating large services took much longer as soon as cluster utilization got above between 30% and 50%. To handle this scenario, we introduced defragmentation as a balancing strategy. We found that for large workloads, especially ones where creation time was important, defragmentation really helped those new workloads get scheduled in the cluster.
You can configure defragmentation metrics to have the Cluster Resource Manager to proactively try to condense the load of the services into fewer nodes. This helps ensure that there is almost always room for large services without reorganizing the cluster. Not having to reorganize the cluster allows creating large workloads quickly.
Most people don’t need defragmentation. Services are usually small, so it’s not hard to find room for them in the cluster. When reorganization is possible, it goes quickly, again because most services are small and can be moved quickly and in parallel. However, if you have large services and need them created quickly then the defragmentation strategy is for you. We'll discuss the tradeoffs of using defragmentation next.
Defragmentation tradeoffs
Defragmentation can increase impactfulness of failures, since more services are running on nodes that fail. Defragmentation can also increase costs, since resources in the cluster must be held in reserve, waiting for the creation of large workloads.
The following diagram gives a visual representation of two clusters, one that is defragmented and one that is not.
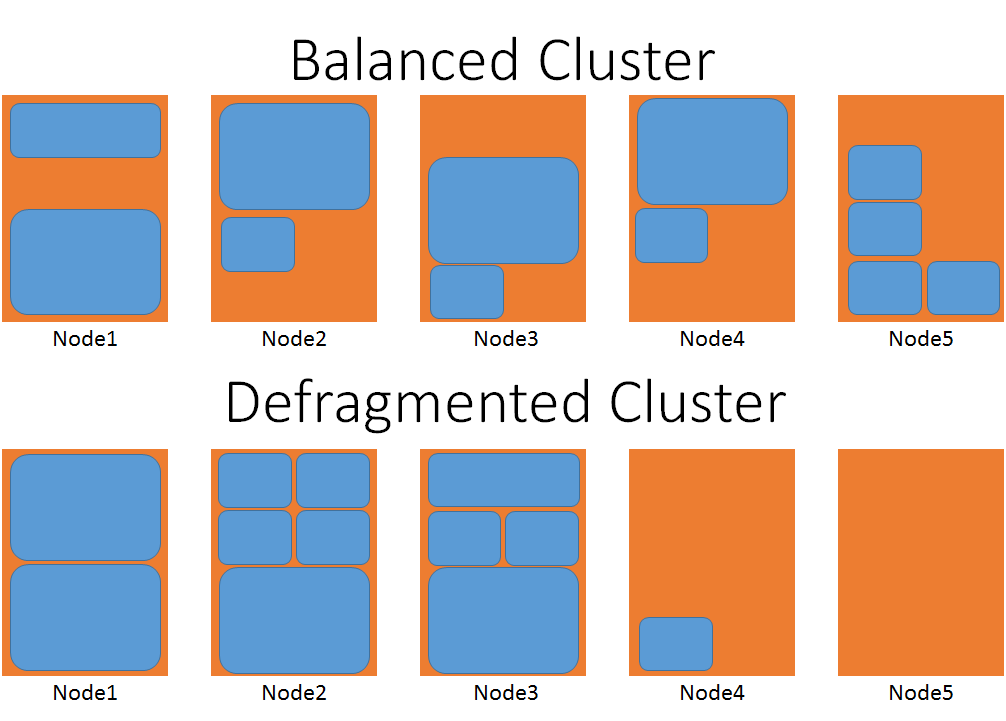
In the balanced case, consider the number of movements that would be necessary to place one of the largest service objects. In the defragmented cluster, the large workload could be placed on nodes four or five without having to wait for any other services to move.
Defragmentation pros and cons
So what are those other conceptual tradeoffs? Here’s a quick table of things to think about:
| Defragmentation Pros | Defragmentation Cons |
|---|---|
| Allows faster creation of large services | Concentrates load onto fewer nodes, increasing contention |
| Enables lower data movement during creation | Failures can impact more services and cause more churn |
| Allows rich description of requirements and reclamation of space | More complex overall Resource Management configuration |
You can mix defragmented and normal metrics in the same cluster. The Cluster Resource Manager tries to consolidate the defragmentation metrics as much as possible while spreading out the others. The results of mixing defragmentation and balancing strategies depend on several factors, including:
- the number of balancing metrics vs. the number of defragmentation metrics
- Whether any service uses both types of metrics
- the metric weights
- current metric loads
Experimentation is required to determine the exact configuration necessary. We recommend thorough measurement of your workloads before you enable defragmentation metrics in production. This is especially true when mixing defragmentation and balanced metrics within the same service.
Configuring defragmentation metrics
Configuring defragmentation metrics is a global decision in the cluster, and individual metrics can be selected for defragmentation. The following config snippets show how to configure metrics for defragmentation. In this case, "Metric1" is configured as a defragmentation metric, while "Metric2" will continue to be balanced normally.
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
via ClusterConfig.json for Standalone deployments or Template.json for Azure hosted clusters:
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
Next steps
- The Cluster Resource Manager has many options for describing the cluster. To find out more about them, check out this article on describing a Service Fabric cluster
- Metrics are how the Service Fabric Cluster Resource Manger manages consumption and capacity in the cluster. To learn more about metrics and how to configure them, check out this article
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for