Introduction to Service Fabric Reliable Actors
Reliable Actors is a Service Fabric application framework based on the Virtual Actor pattern. The Reliable Actors API provides a single-threaded programming model built on the scalability and reliability guarantees provided by Service Fabric.
What are Actors?
An actor is an isolated, independent unit of compute and state with single-threaded execution. The actor pattern is a computational model for concurrent or distributed systems in which a large number of these actors can execute simultaneously and independently of each other. Actors can communicate with each other and they can create more actors.
When to use Reliable Actors
Service Fabric Reliable Actors is an implementation of the actor design pattern. As with any software design pattern, the decision whether to use a specific pattern is made based on whether or not a software design problem fits the pattern.
Although the actor design pattern can be a good fit to a number of distributed systems problems and scenarios, careful consideration of the constraints of the pattern and the framework implementing it must be made. As general guidance, consider the actor pattern to model your problem or scenario if:
- Your problem space involves a large number (thousands or more) of small, independent, and isolated units of state and logic.
- You want to work with single-threaded objects that do not require significant interaction from external components, including querying state across a set of actors.
- Your actor instances won't block callers with unpredictable delays by issuing I/O operations.
Actors in Service Fabric
In Service Fabric, actors are implemented in the Reliable Actors framework: An actor-pattern-based application framework built on top of Service Fabric Reliable Services. Each Reliable Actor service you write is actually a partitioned, stateful Reliable Service.
Every actor is defined as an instance of an actor type, identical to the way a .NET object is an instance of a .NET type. For example, there may be an actor type that implements the functionality of a calculator and there could be many actors of that type that are distributed on various nodes across a cluster. Each such actor is uniquely identified by an actor ID.
Actor Lifetime
Service Fabric actors are virtual, meaning that their lifetime is not tied to their in-memory representation. As a result, they do not need to be explicitly created or destroyed. The Reliable Actors runtime automatically activates an actor the first time it receives a request for that actor ID. If an actor is not used for a period of time, the Reliable Actors runtime garbage-collects the in-memory object. It will also maintain knowledge of the actor's existence should it need to be reactivated later. For more details, see Actor lifecycle and garbage collection.
This virtual actor lifetime abstraction carries some caveats as a result of the virtual actor model, and in fact the Reliable Actors implementation deviates at times from this model.
- An actor is automatically activated (causing an actor object to be constructed) the first time a message is sent to its actor ID. After some period of time, the actor object is garbage collected. In the future, using the actor ID again, causes a new actor object to be constructed. An actor's state outlives the object's lifetime when stored in the state manager.
- Calling any actor method for an actor ID activates that actor. For this reason, actor types have their constructor called implicitly by the runtime. Therefore, client code cannot pass parameters to the actor type's constructor, although parameters may be passed to the actor's constructor by the service itself. The result is that actors may be constructed in a partially initialized state by the time other methods are called on it, if the actor requires initialization parameters from the client. There is no single entry point for the activation of an actor from the client.
- Although Reliable Actors implicitly create actor objects; you do have the ability to explicitly delete an actor and its state.
Distribution and failover
To provide scalability and reliability, Service Fabric distributes actors throughout the cluster and automatically migrates them from failed nodes to healthy ones as required. This is an abstraction over a partitioned, stateful Reliable Service. Distribution, scalability, reliability, and automatic failover are all provided by virtue of the fact that actors are running inside a stateful Reliable Service called the Actor Service.
Actors are distributed across the partitions of the Actor Service, and those partitions are distributed across the nodes in a Service Fabric cluster. Each service partition contains a set of actors. Service Fabric manages distribution and failover of the service partitions.
For example, an actor service with nine partitions deployed to three nodes using the default actor partition placement would be distributed thusly:
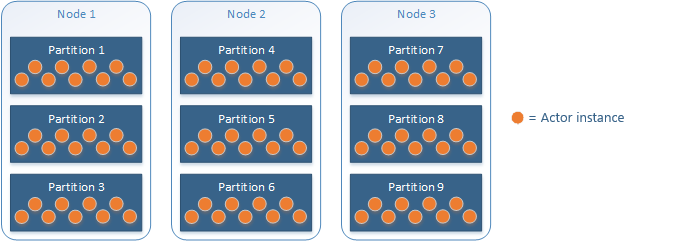
The Actor Framework manages partition scheme and key range settings for you. This simplifies some choices but also carries some consideration:
- Reliable Services allows you to choose a partitioning scheme, key range (when using a range partitioning scheme), and partition count. Reliable Actors is restricted to the range partitioning scheme (the uniform Int64 scheme) and requires you use the full Int64 key range.
- By default, actors are randomly placed into partitions resulting in uniform distribution.
- Because actors are randomly placed, it should be expected that actor operations will always require network communication, including serialization and deserialization of method call data, incurring latency and overhead.
- In advanced scenarios, it is possible to control actor partition placement by using Int64 actor IDs that map to specific partitions. However, doing so can result in an unbalanced distribution of actors across partitions.
For more information on how actor services are partitioned, refer to partitioning concepts for actors.
Actor communication
Actor interactions are defined in an interface that is shared by the actor that implements the interface, and the client that gets a proxy to an actor via the same interface. Because this interface is used to invoke actor methods asynchronously, every method on the interface must be Task-returning.
Method invocations and their responses ultimately result in network requests across the cluster, so the arguments and the result types of the tasks that they return must be serializable by the platform. In particular, they must be data contract serializable.
The actor proxy
The Reliable Actors client API provides communication between an actor instance and an actor client. To communicate with an actor, a client creates an actor proxy object that implements the actor interface. The client interacts with the actor by invoking methods on the proxy object. The actor proxy can be used for client-to-actor and actor-to-actor communication.
// Create a randomly distributed actor ID
ActorId actorId = ActorId.CreateRandom();
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
IMyActor myActor = ActorProxy.Create<IMyActor>(actorId, new Uri("fabric:/MyApp/MyActorService"));
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
await myActor.DoWorkAsync();
// Create actor ID with some name
ActorId actorId = new ActorId("Actor1");
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
MyActor myActor = ActorProxyBase.create(actorId, new URI("fabric:/MyApp/MyActorService"), MyActor.class);
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
myActor.DoWorkAsync().get();
Note that the two pieces of information used to create the actor proxy object are the actor ID and the application name. The actor ID uniquely identifies the actor, while the application name identifies the Service Fabric application where the actor is deployed.
The ActorProxy(C#) / ActorProxyBase(Java) class on the client side performs the necessary resolution to locate the actor by ID and open a communication channel with it. It also retries to locate the actor in the cases of communication failures and failovers. As a result, message delivery has the following characteristics:
- Message delivery is best effort.
- Actors may receive duplicate messages from the same client.
Concurrency
The Reliable Actors runtime provides a simple turn-based access model for accessing actor methods. This means that no more than one thread can be active inside an actor object's code at any time. Turn-based access greatly simplifies concurrent systems as there is no need for synchronization mechanisms for data access. It also means systems must be designed with special considerations for the single-threaded access nature of each actor instance.
- A single actor instance cannot process more than one request at a time. An actor instance can cause a throughput bottleneck if it is expected to handle concurrent requests.
- Actors can deadlock each other if there is a circular request between two actors while an external request is made to one of the actors simultaneously. The actor runtime will automatically time out on actor calls and throw an exception to the caller to interrupt possible deadlock situations.
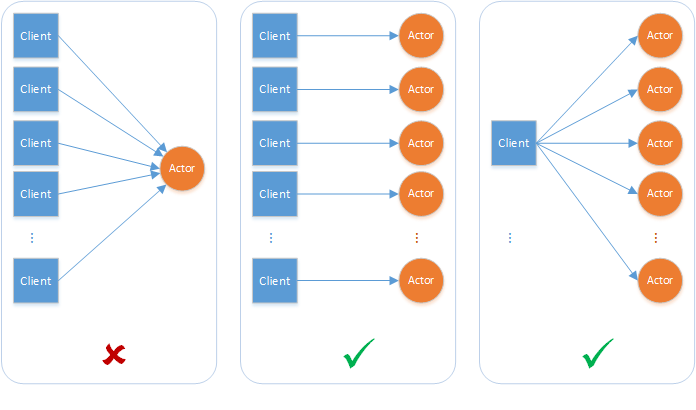
Turn-based access
A turn consists of the complete execution of an actor method in response to a request from other actors or clients, or the complete execution of a timer/reminder callback. Even though these methods and callbacks are asynchronous, the Actors runtime does not interleave them. A turn must be fully finished before a new turn is allowed. In other words, an actor method or timer/reminder callback that is currently executing must be fully finished before a new call to a method or callback is allowed. A method or callback is considered to have finished if the execution has returned from the method or callback and the task returned by the method or callback has finished. It is worth emphasizing that turn-based concurrency is respected even across different methods, timers, and callbacks.
The Actors runtime enforces turn-based concurrency by acquiring a per-actor lock at the beginning of a turn and releasing the lock at the end of the turn. Thus, turn-based concurrency is enforced on a per-actor basis and not across actors. Actor methods and timer/reminder callbacks can execute simultaneously on behalf of different actors.
The following example illustrates the above concepts. Consider an actor type that implements two asynchronous methods (say, Method1 and Method2), a timer, and a reminder. The diagram below shows an example of a timeline for the execution of these methods and callbacks on behalf of two actors (ActorId1 and ActorId2) that belong to this actor type.
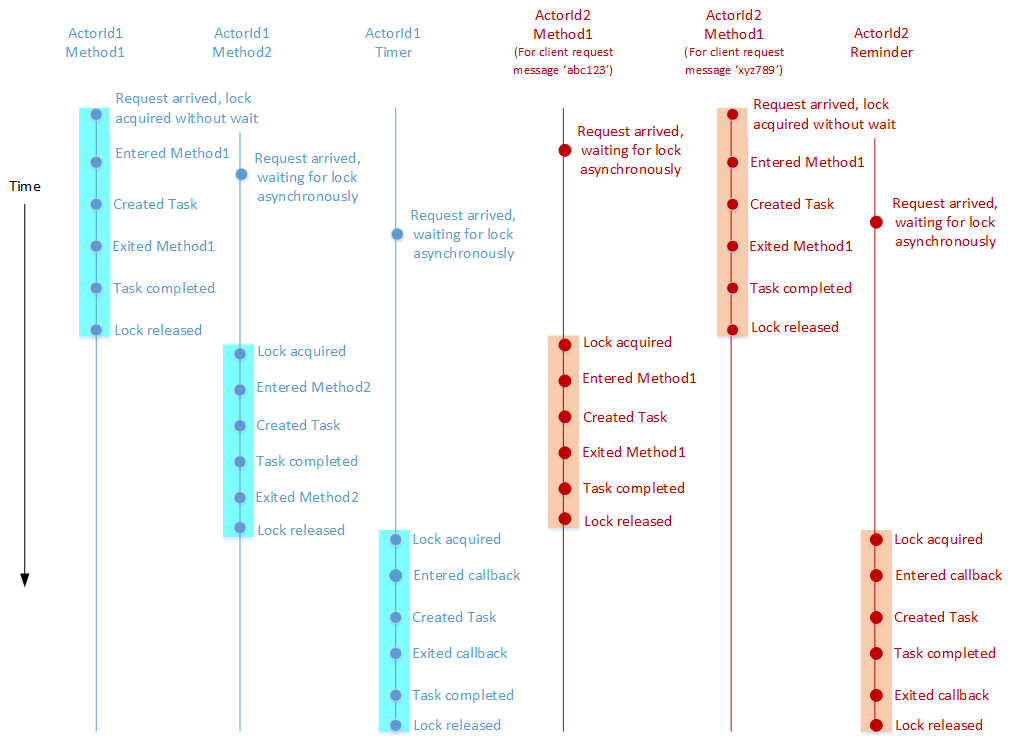
This diagram follows these conventions:
- Each vertical line shows the logical flow of execution of a method or a callback on behalf of a particular actor.
- The events marked on each vertical line occur in chronological order, with newer events occurring below older ones.
- Different colors are used for timelines corresponding to different actors.
- Highlighting is used to indicate the duration for which the per-actor lock is held on behalf of a method or callback.
Some important points to consider:
- While Method1 is executing on behalf of ActorId2 in response to client request xyz789, another client request (abc123) arrives that also requires Method1 to be executed by ActorId2. However, the second execution of Method1 does not begin until the prior execution has finished. Similarly, a reminder registered by ActorId2 fires while Method1 is being executed in response to client request xyz789. The reminder callback is executed only after both executions of Method1 are complete. All of this is due to turn-based concurrency being enforced for ActorId2.
- Similarly, turn-based concurrency is also enforced for ActorId1, as demonstrated by the execution of Method1, Method2, and the timer callback on behalf of ActorId1 happening in a serial fashion.
- Execution of Method1 on behalf of ActorId1 overlaps with its execution on behalf of ActorId2. This is because turn-based concurrency is enforced only within an actor and not across actors.
- In some of the method/callback executions, the
Task(C#) /CompletableFuture(Java) returned by the method/callback finishes after the method returns. In some others, the asynchronous operation has already finished by the time the method/callback returns. In both cases, the per-actor lock is released only after both the method/callback returns and the asynchronous operation finishes.
Reentrancy
The Actors runtime allows reentrancy by default. This means that if an actor method of Actor A calls a method on Actor B, which in turn calls another method on Actor A, that method is allowed to run. This is because it is part of the same logical call-chain context. All timer and reminder calls start with the new logical call context. See the Reliable Actors reentrancy for more details.
Scope of concurrency guarantees
The Actors runtime provides these concurrency guarantees in situations where it controls the invocation of these methods. For example, it provides these guarantees for the method invocations that are done in response to a client request, as well as for timer and reminder callbacks. However, if the actor code directly invokes these methods outside of the mechanisms provided by the Actors runtime, then the runtime cannot provide any concurrency guarantees. For example, if the method is invoked in the context of some task that is not associated with the task returned by the actor methods, then the runtime cannot provide concurrency guarantees. If the method is invoked from a thread that the actor creates on its own, then the runtime also cannot provide concurrency guarantees. Therefore, to perform background operations, actors should use actor timers and actor reminders that respect turn-based concurrency.
Next steps
Get started by building your first Reliable Actors service:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for