Performance tuning with ordered clustered columnstore index
Applies to: Azure Synapse Analytics dedicated SQL pools, SQL Server 2022 (16.x) and later
When users query a columnstore table in dedicated SQL pool, the optimizer checks the minimum and maximum values stored in each segment. Segments that are outside the bounds of the query predicate aren't read from disk to memory. A query can finish faster if the number of segments to read and their total size are small.
Ordered vs. non-ordered clustered columnstore index
By default, for each table created without an index option, an internal component (index builder) creates a non-ordered clustered columnstore index (CCI) on it. Data in each column is compressed into a separate CCI rowgroup segment. There's metadata on each segment's value range, so segments that are outside the bounds of the query predicate aren't read from disk during query execution. CCI offers the highest level of data compression and reduces the size of segments to read so queries can run faster. However, because the index builder doesn't sort data before compressing them into segments, segments with overlapping value ranges could occur, causing queries to read more segments from disk and take longer to finish.
Ordered clustered columnstore indexes by enabling efficient segment elimination, resulting in much faster performance by skipping large amounts of ordered data that don't match the query predicate. When creating an ordered CCI, the dedicated SQL pool engine sorts the existing data in memory by the order key(s) before the index builder compresses them into index segments. With sorted data, segment overlapping is reduced allowing queries to have a more efficient segment elimination and thus faster performance because the number of segments to read from disk is smaller. If all data can be sorted in memory at once, then segment overlapping can be avoided. Due to large tables in data warehouses, this scenario doesn't happen often.
To check the segment ranges for a column, run the following command with your table name and column name:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Note
In an ordered CCI table, the new data resulting from the same batch of DML or data loading operations are sorted within that batch, there is no global sorting across all data in the table. Users can REBUILD the ordered CCI to sort all data in the table. In dedicated SQL pool, the columnstore index REBUILD is an offline operation. For a partitioned table, the REBUILD is done one partition at a time. Data in the partition that is being rebuilt is "offline" and unavailable until the REBUILD is complete for that partition.
Query performance
A query's performance gain from an ordered CCI depends on the query patterns, the size of data, how well the data is sorted, the physical structure of segments, and the DWU and resource class chosen for the query execution. Users should review all these factors before choosing the ordering columns when designing an ordered CCI table.
Queries with all these patterns typically run faster with ordered CCI.
- The queries have equality, inequality, or range predicates
- The predicate columns and the ordered CCI columns are the same.
In this example, table T1 has a clustered columnstore index ordered in the sequence of Col_C, Col_B, and Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
The performance of query 1 and query 2 can benefit more from ordered CCI than the other queries, as they reference all the ordered CCI columns.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Data loading performance
The performance of data loading into an ordered CCI table is similar to a partitioned table. Loading data into an ordered CCI table can take longer than a non-ordered CCI table because of the data sorting operation, however queries can run faster afterwards with ordered CCI.
Here's an example performance comparison of loading data into tables with different schemas.
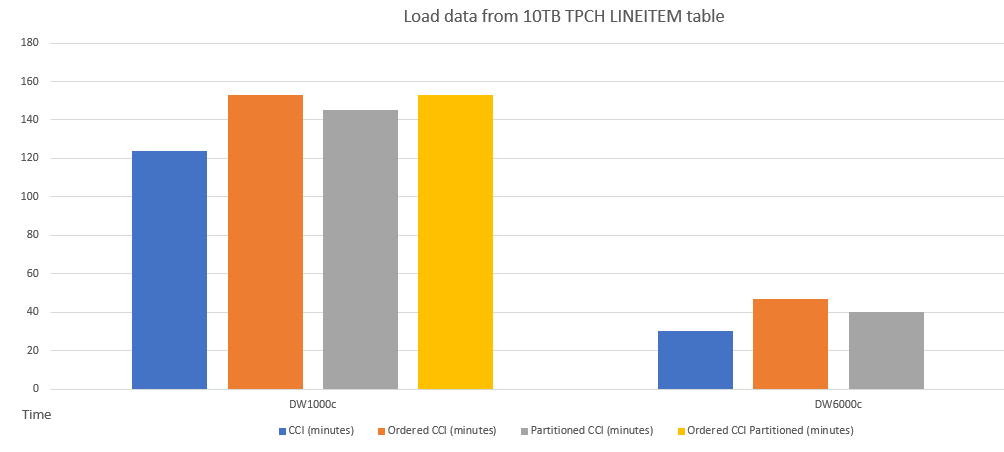
Here's an example query performance comparison between CCI and ordered CCI.
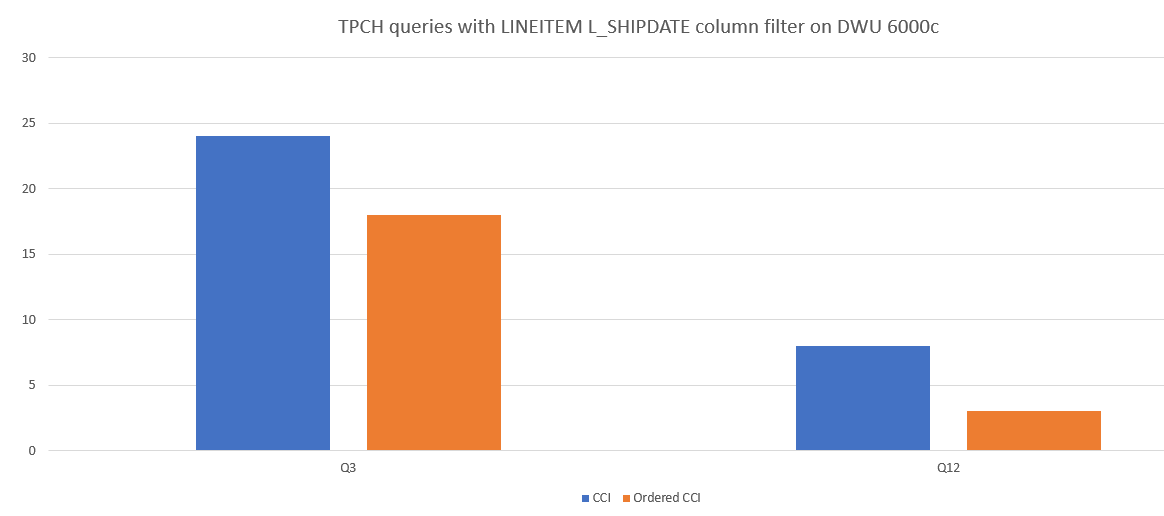
Reduce segment overlapping
The number of overlapping segments depends on the size of data to sort, the available memory, and the maximum degree of parallelism (MAXDOP) setting during ordered CCI creation. The following strategies reduce segment overlapping when creating ordered CCI.
Use
xlargercresource class on a higher DWU to allow more memory for data sorting before the index builder compresses the data into segments. Once in an index segment, the physical location of the data cannot be changed. There's no data sorting within a segment or across segments.Create ordered CCI with
OPTION (MAXDOP = 1). Each thread used for ordered CCI creation works on a subset of data and sorts it locally. There's no global sorting across data sorted by different threads. Using parallel threads can reduce the time to create an ordered CCI but will generate more overlapping segments than using a single thread. Using a single threaded operation delivers the highest compression quality. For example:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Note
Currently, in dedicated SQL pools in Azure Synapse Analytics, the MAXDOP option is only supported in creating an ordered CCI table using CREATE TABLE AS SELECT command. Creating an ordered CCI via CREATE INDEX or CREATE TABLE commands doesn't support the MAXDOP option. This limitation does not apply to SQL Server 2022 and later versions, where you can specify MAXDOP with the CREATE INDEX or CREATE TABLE commands.
- Pre-sort the data by the sort key(s) before loading them into tables.
Here's an example of an ordered CCI table distribution that has zero segment overlapping following above recommendations. The ordered CCI table is created in a DWU1000c database via CTAS from a 20-GB heap table using MAXDOP 1 and xlargerc. The CCI is ordered on a BIGINT column with no duplicates.
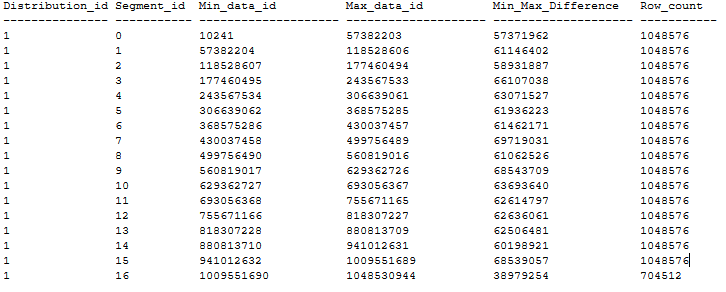
Create ordered CCI on large tables
Creating an ordered CCI is an offline operation. For tables with no partitions, the data won't be accessible to users until the ordered CCI creation process completes. For partitioned tables, since the engine creates the ordered CCI partition by partition, users can still access the data in partitions where ordered CCI creation isn't in process. You can use this option to minimize the downtime during ordered CCI creation on large tables:
- Create partitions on the target large table (called
Table_A). - Create an empty ordered CCI table (called
Table_B) with the same table and partition schema asTable_A. - Switch one partition from
Table_AtoTable_B. - Run
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>to rebuild the switched-in partition onTable_B. - Repeat step 3 and 4 for each partition in
Table_A. - Once all partitions are switched from
Table_AtoTable_Band have been rebuilt, dropTable_A, and renameTable_BtoTable_A.
Tip
For a dedicated SQL pool table with an ordered CCI, ALTER INDEX REBUILD will re-sort the data using tempdb. Monitor tempdb during rebuild operations. If you need more tempdb space, scale up the pool. Scale back down once the index rebuild is complete.
For a dedicated SQL pool table with an ordered CCI, ALTER INDEX REORGANIZE does not re-sort the data. To resort data, use ALTER INDEX REBUILD.
For more information on ordered CCI maintenance, see Optimizing clustered columnstore indexes.
Feature differences in SQL Server 2022 capabilities
SQL Server 2022 (16.x) introduced ordered clustered columnstore indexes similar to the feature in Azure Synapse dedicated SQL pools.
- Currently, only SQL Server 2022 (16.x) and later versions support clustered columnstore enhanced segment elimination capabilities for string, binary, and guid data types, and the datetimeoffset data type for scale greater than two. Previously, this segment elimination applies to numeric, date, and time data types, and the datetimeoffset data type with scale less than or equal to two.
- Currently, only SQL Server 2022 (16.x) and later versions support clustered columnstore rowgroup elimination for the prefix of
LIKEpredicates, for examplecolumn LIKE 'string%'. Segment elimination is not supported for non-prefix use of LIKE such ascolumn LIKE '%string'.
For more information, see What's New in Columnstore Indexes.
Examples
A. To check for ordered columns and order ordinal:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. To change column ordinal, add or remove columns from the order list, or to change from CCI to ordered CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for