Quickstart: Use a sample notebook from the Synapse Analytics gallery
In this quickstart, you'll learn how to copy a sample machine learning notebook from the Synapse Analytics gallery into your workspace, modify it, and run it.
Prerequisites
- Azure Synapse Analytics workspace with an Azure Data Lake Storage Gen2 storage account configured as the default storage. You need to be the Storage Blob Data Contributor of the Data Lake Storage Gen2 file system that you work with.
- Spark pool in your Azure Synapse Analytics workspace.
Copy the notebook to your workspace
Open your workspace and select Learn from the home page.
In the Knowledge center, select Browse gallery.
In the gallery, select Notebooks.
Find and select a notebook from the gallery.

Select Continue.
On the notebook preview page, select Open notebook. The sample notebook is copied into your workspace and opened.
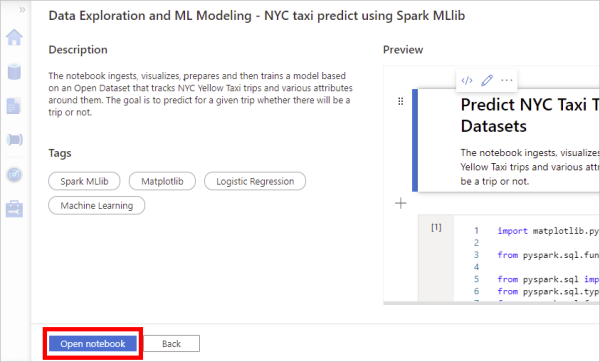
In the Attach to menu in the open notebook, select your Apache Spark pool.
Save the notebook
To save your notebook by selecting Publish on the workspace command bar.
Copying the sample notebook
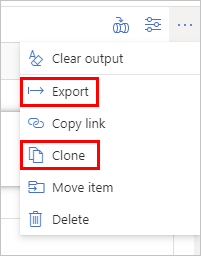
To make a copy of this notebook, click the ellipsis in the top command bar and select Clone to create a copy in your workspace or Export to download a copy of the notebook (.ipynb) file.
Clean up resources
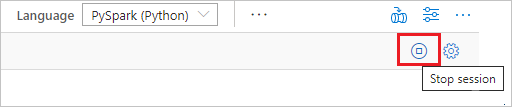
To ensure the Spark instance is shut down when you're finished, end any connected sessions (notebooks). The pool shuts down when the idle time specified in the Apache Spark pool is reached. You can also select stop session from the status bar at the upper right of the notebook.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for