Monitor and mitigate throttling to reduce latency in Azure Time Series Insights Gen1
Note
The Time Series Insights (TSI) service will no longer be supported after March 2025. Consider migrating existing TSI environments to alternative solutions as soon as possible. For more information on the deprecation and migration, visit our documentation.
Caution
This is a Gen1 article.
When the amount of incoming data exceeds your environment's configuration, you may experience latency or throttling in Azure Time Series Insights.
You can avoid latency and throttling by properly configuring your environment for the amount of data you want to analyze.
You are most likely to experience latency and throttling when you:
- Add an event source that contains old data that may exceed your allotted ingress rate (Azure Time Series Insights will need to catch up).
- Add more event sources to an environment, resulting in a spike from additional events (which could exceed your environment’s capacity).
- Push large amounts of historical events to an event source, resulting in a lag (Azure Time Series Insights will need to catch up).
- Join reference data with telemetry, resulting in larger event size. The maximum allowed packet size is 32 KB; data packets larger than 32 KB are truncated.
Video
Learn about Azure Time Series Insights data ingress behavior and how to plan for it.
Monitor latency and throttling with alerts
Alerts can help you to diagnose and mitigate latency issues occurring in your environment.
In the Azure portal, select your Azure Time Series Insights environment. Then select Alerts.

Select + New alert rule. The Create rule panel will then be displayed. Select Add under CONDITION.

Next, configure the exact conditions for the signal logic.
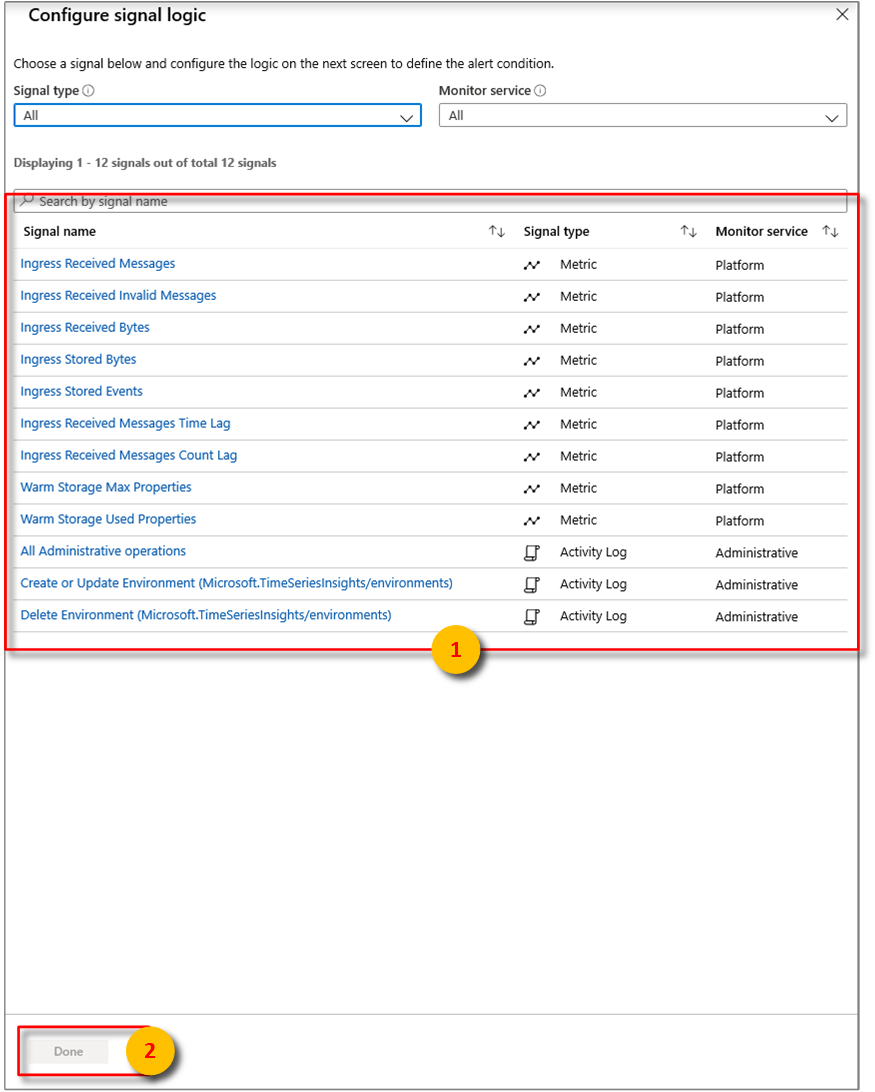
From there, you can configure alerts using some of the following conditions:
Metric Description Ingress Received Bytes Count of raw bytes read from event sources. Raw count usually includes the property name and value. Ingress Received Invalid Messages Count of invalid messages read from all Azure Event Hubs or Azure IoT Hub event sources. Ingress Received Messages Count of messages read from all Event Hubs or IoT Hubs event sources. Ingress Stored Bytes Total size of events stored and available for query. Size is computed only on the property value. Ingress Stored Events Count of flattened events stored and available for query. Ingress Received Message Time Lag Difference in seconds between the time that the message is enqueued in the event source and the time it is processed in Ingress. Ingress Received Message Count Lag Difference between the sequence number of last enqueued message in the event source partition and sequence number of message being processed in Ingress. Select Done.
After configuring the desired signal logic, review the chosen alert rule visually.





Throttling and ingress management
If you're being throttled, a value for the Ingress Received Message Time Lag will be registered informing you about how many seconds behind your Azure Time Series Insights environment are from the actual time the message hits the event source (excluding indexing time of appx. 30-60 seconds).
Ingress Received Message Count Lag should also have a value, allowing you to determine how many messages behind you are. The easiest way to get caught up is to increase your environment's capacity to a size that will enable you to overcome the difference.
For example, if your S1 environment is demonstrating lag of 5,000,000 messages, you might increase the size of your environment to six units for around a day to get caught up. You could increase even further to catch up faster. The catch-up period is a common occurrence when initially provisioning an environment, particularly when you connect it to an event source that already has events in it or when you bulk upload lots of historical data.
Another technique is to set an Ingress Stored Events alert >= a threshold slightly below your total environment capacity for a period of 2 hours. This alert can help you understand if you are constantly at capacity, which indicates a high likelihood of latency.
For example, if you have three S1 units provisioned (or 2100 events per minute ingress capacity), you can set an Ingress Stored Events alert for >= 1900 events for 2 hours. If you are constantly exceeding this threshold, and therefore, triggering your alert, you are likely under-provisioned.
If you suspect you are being throttled, you can compare your Ingress Received Messages with your event source’s egressed messages. If ingress into your Event Hub is greater than your Ingress Received Messages, your Azure Time Series Insights are likely being throttled.
Improving performance
To reduce throttling or experiencing latency, the best way to correct it is to increase your environment's capacity.
You can avoid latency and throttling by properly configuring your environment for the amount of data you want to analyze. For more information about how to add capacity to your environment, read Scale your environment.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for