Function Overloading
C++ lets you specify more than one function of the same name in the same scope. These functions are called overloaded functions, or overloads. Overloaded functions enable you to supply different semantics for a function, depending on the types and number of its arguments.
For example, consider a print function that takes a std::string argument. This function might perform very different tasks than a function that takes an argument of type double. Overloading keeps you from having to use names such as print_string or print_double. At compile time, the compiler chooses which overload to use based on the types and number of arguments passed in by the caller. If you call print(42.0), then the void print(double d) function is invoked. If you call print("hello world"), then the void print(std::string) overload is invoked.
You can overload both member functions and free functions. The following table shows which parts of a function declaration C++ uses to differentiate between groups of functions with the same name in the same scope.
Overloading Considerations
| Function declaration element | Used for overloading? |
|---|---|
| Function return type | No |
| Number of arguments | Yes |
| Type of arguments | Yes |
| Presence or absence of ellipsis | Yes |
Use of typedef names |
No |
| Unspecified array bounds | No |
const or volatile |
Yes, when applied to entire function |
Reference qualifiers (& and &&) |
Yes |
Example
The following example illustrates how you can use function overloads:
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
The preceding code shows overloads of the print function in file scope.
The default argument isn't considered part of the function type. Therefore, it's not used in selecting overloaded functions. Two functions that differ only in their default arguments are considered multiple definitions rather than overloaded functions.
Default arguments can't be supplied for overloaded operators.
Argument matching
The compiler selects which overloaded function to invoke based on the best match among the function declarations in the current scope to the arguments supplied in the function call. If a suitable function is found, that function is called. "Suitable" in this context means either:
An exact match was found.
A trivial conversion was performed.
An integral promotion was performed.
A standard conversion to the desired argument type exists.
A user-defined conversion (either a conversion operator or a constructor) to the desired argument type exists.
Arguments represented by an ellipsis were found.
The compiler creates a set of candidate functions for each argument. Candidate functions are functions in which the actual argument in that position can be converted to the type of the formal argument.
A set of "best matching functions" is built for each argument, and the selected function is the intersection of all the sets. If the intersection contains more than one function, the overloading is ambiguous and generates an error. The function that's eventually selected is always a better match than every other function in the group for at least one argument. If there's no clear winner, the function call generates a compiler error.
Consider the following declarations (the functions are marked Variant 1, Variant 2, and Variant 3, for identification in the following discussion):
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
Consider the following statement:
F1 = Add( F2, 23 );
The preceding statement builds two sets:
Set 1: Candidate functions that have first argument of type Fraction |
Set 2: Candidate functions whose second argument can be converted to type int |
|---|---|
| Variant 1 | Variant 1 (int can be converted to long using a standard conversion) |
| Variant 3 |
Functions in Set 2 are functions that have implicit conversions from the actual parameter type to the formal parameter type. One of those functions has the smallest "cost" to convert the actual parameter type to its corresponding formal parameter type.
The intersection of these two sets is Variant 1. An example of an ambiguous function call is:
F1 = Add( 3, 6 );
The preceding function call builds the following sets:
Set 1: Candidate Functions That Have First Argument of Type int |
Set 2: Candidate Functions That Have Second Argument of Type int |
|---|---|
Variant 2 (int can be converted to long using a standard conversion) |
Variant 1 (int can be converted to long using a standard conversion) |
Because the intersection of these two sets is empty, the compiler generates an error message.
For argument matching, a function with n default arguments is treated as n+1 separate functions, each with a different number of arguments.
The ellipsis (...) acts as a wildcard; it matches any actual argument. It can lead to many ambiguous sets, if you don't design your overloaded function sets with extreme care.
Note
Ambiguity of overloaded functions can't be determined until a function call is encountered. At that point, the sets are built for each argument in the function call, and you can determine whether an unambiguous overload exists. This means that ambiguities can remain in your code until they're evoked by a particular function call.
Argument Type Differences
Overloaded functions differentiate between argument types that take different initializers. Therefore, an argument of a given type and a reference to that type are considered the same for the purposes of overloading. They're considered the same because they take the same initializers. For example, max( double, double ) is considered the same as max( double &, double & ). Declaring two such functions causes an error.
For the same reason, function arguments of a type modified by const or volatile aren't treated differently than the base type for the purposes of overloading.
However, the function overloading mechanism can distinguish between references that are qualified by const and volatile and references to the base type. It makes code such as the following possible:
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
Output
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
Pointers to const and volatile objects are also considered different from pointers to the base type for the purposes of overloading.
Argument matching and conversions
When the compiler tries to match actual arguments against the arguments in function declarations, it can supply standard or user-defined conversions to obtain the correct type if no exact match can be found. The application of conversions is subject to these rules:
Sequences of conversions that contain more than one user-defined conversion aren't considered.
Sequences of conversions that can be shortened by removing intermediate conversions aren't considered.
The resultant sequence of conversions, if any, is called the best matching sequence. There are several ways to convert an object of type int to type unsigned long using standard conversions (described in Standard conversions):
Convert from
inttolongand then fromlongtounsigned long.Convert from
inttounsigned long.
Although the first sequence achieves the desired goal, it isn't the best matching sequence, because a shorter sequence exists.
The following table shows a group of conversions called trivial conversions. Trivial conversions have a limited effect on which sequence the compiler chooses as the best match. The effect of trivial conversions is described after the table.
Trivial conversions
| Argument type | Converted type |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
The sequence in which conversions are attempted is as follows:
Exact match. An exact match between the types with which the function is called and the types declared in the function prototype is always the best match. Sequences of trivial conversions are classified as exact matches. However, sequences that don't make any of these conversions are considered better than sequences that convert:
From pointer, to pointer to
const(type-name*toconst type-name*).From pointer, to pointer to
volatile(type-name*tovolatile type-name*).From reference, to reference to
const(type-name&toconst type-name&).From reference, to reference to
volatile(type-name&tovolatile type&).
Match using promotions. Any sequence not classified as an exact match that contains only integral promotions, conversions from
floattodouble, and trivial conversions is classified as a match using promotions. Although not as good a match as any exact match, a match using promotions is better than a match using standard conversions.Match using standard conversions. Any sequence not classified as an exact match or a match using promotions that contains only standard conversions and trivial conversions is classified as a match using standard conversions. Within this category, the following rules are applied:
Conversion from a pointer to a derived class, to a pointer to a direct or indirect base class is preferable to converting to
void *orconst void *.Conversion from a pointer to a derived class, to a pointer to a base class produces a better match the closer the base class is to a direct base class. Suppose the class hierarchy is as shown in the following figure:

Graph showing preferred conversions.
Conversion from type D* to type C* is preferable to conversion from type D* to type B*. Similarly, conversion from type D* to type B* is preferable to conversion from type D* to type A*.
This same rule applies to reference conversions. Conversion from type D& to type C& is preferable to conversion from type D& to type B&, and so on.
This same rule applies to pointer-to-member conversions. Conversion from type T D::* to type T C::* is preferable to conversion from type T D::* to type T B::*, and so on (where T is the type of the member).
The preceding rule applies only along a given path of derivation. Consider the graph shown in the following figure.
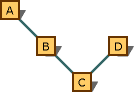
Multiple-inheritance graph that shows preferred conversions.
Conversion from type C* to type B* is preferable to conversion from type C* to type A*. The reason is that they are on the same path, and B* is closer. However, conversion from type C* to type D* isn't preferable to conversion to type A*; there's no preference because the conversions follow different paths.
Match with user-defined conversions. This sequence can't be classified as an exact match, a match using promotions, or a match using standard conversions. To be classified as a match with user-defined conversions, the sequence must only contain user-defined conversions, standard conversions, or trivial conversions. A match with user-defined conversions is considered a better match than a match with an ellipsis (
...) but not as good a match as a match with standard conversions.Match with an ellipsis. Any sequence that matches an ellipsis in the declaration is classified as a match with an ellipsis. It's considered the weakest match.
User-defined conversions are applied if no built-in promotion or conversion exists. These conversions are selected based on the type of the argument being matched. Consider the following code:
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
};
UDC udc;
int main()
{
Print( udc );
}
The available user-defined conversions for class UDC are from type int and type long. Therefore, the compiler considers conversions for the type of the object being matched: UDC. A conversion to int exists, and it's selected.
During the process of matching arguments, standard conversions can be applied to both the argument and the result of a user-defined conversion. Therefore, the following code works:
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
In this example, the compiler invokes a user-defined conversion, operator long, to convert udc to type long. If no user-defined conversion to type long was defined, the compiler would first convert type UDC to type int using the user-defined operator int conversion. Then it would apply the standard conversion from type int to type long to match the argument in the declaration.
If any user-defined conversions are required to match an argument, the standard conversions aren't used when evaluating the best match. Even if more than one candidate function requires a user-defined conversion, the functions are considered equal. For example:
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Both versions of Func require a user-defined conversion to convert type int to the class type argument. The possible conversions are:
Convert from type
intto typeUDC1(a user-defined conversion).Convert from type
intto typelong; then convert to typeUDC2(a two-step conversion).
Even though the second one requires both a standard conversion and the user-defined conversion, the two conversions are still considered equal.
Note
User-defined conversions are considered conversion by construction or conversion by initialization. The compiler considers both methods equal when it determines the best match.
Argument matching and the this pointer
Class member functions are treated differently, depending on whether they're declared as static. static functions don't have an implicit argument that supplies the this pointer, so they're considered to have one less argument than regular member functions. Otherwise, they're declared identically.
Member functions that aren't static require the implied this pointer to match the object type the function is being called through. Or, for overloaded operators, they require the first argument to match the object the operator is applied to. For more information about overloaded operators, see Overloaded operators.
Unlike other arguments in overloaded functions, the compiler introduces no temporary objects and attempts no conversions when trying to match the this pointer argument.
When the -> member-selection operator is used to access a member function of class class_name, the this pointer argument has a type of class_name * const. If the members are declared as const or volatile, the types are const class_name * const and volatile class_name * const, respectively.
The . member-selection operator works exactly the same way, except that an implicit & (address-of) operator is prefixed to the object name. The following example shows how this works:
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
The left operand of the ->* and .* (pointer to member) operators are treated the same way as the . and -> (member-selection) operators with respect to argument matching.
Reference-qualifiers on member functions
Reference qualifiers make it possible to overload a member function based on whether the object pointed to by this is an rvalue or an lvalue. Use this feature to avoid unnecessary copy operations in scenarios where you choose not to provide pointer access to the data. For example, assume class C initializes some data in its constructor, and returns a copy of that data in member function get_data(). If an object of type C is an rvalue that's about to be destroyed, then the compiler chooses the get_data() && overload, which moves instead of copies the data.
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
Restrictions on overloading
Several restrictions govern an acceptable set of overloaded functions:
Any two functions in a set of overloaded functions must have different argument lists.
Overloading functions that have argument lists of the same types, based on return type alone, is an error.
Microsoft Specific
You can overload
operator newbased on the return type, specifically, based on the memory-model modifier specified.END Microsoft Specific
Member functions can't be overloaded solely because one is
staticand the other isn'tstatic.typedefdeclarations don't define new types; they introduce synonyms for existing types. They don't affect the overloading mechanism. Consider the following code:typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );The preceding two functions have identical argument lists.
PSTRis a synonym for typechar *. In member scope, this code generates an error.Enumerated types are distinct types and can be used to distinguish between overloaded functions.
The types "array of" and "pointer to" are considered identical for the purposes of distinguishing between overloaded functions, but only for one-dimensional arrays. These overloaded functions conflict and generate an error message:
void Print( char *szToPrint ); void Print( char szToPrint[] );For higher dimension arrays, the second and later dimensions are considered part of the type. They're used in distinguishing between overloaded functions:
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
Overloading, overriding, and hiding
Any two function declarations of the same name in the same scope can refer to the same function, or to two discrete overloaded functions. If the argument lists of the declarations contain arguments of equivalent types (as described in the previous section), the function declarations refer to the same function. Otherwise, they refer to two different functions that are selected using overloading.
Class scope is strictly observed. A function declared in a base class isn't in the same scope as a function declared in a derived class. If a function in a derived class is declared with the same name as a virtual function in the base class, the derived-class function overrides the base-class function. For more information, see Virtual Functions.
If the base class function isn't declared as virtual, then the derived class function is said to hide it. Both overriding and hiding are distinct from overloading.
Block scope is strictly observed. A function declared in file scope isn't in the same scope as a function declared locally. If a locally declared function has the same name as a function declared in file scope, the locally declared function hides the file-scoped function instead of causing overloading. For example:
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
The preceding code shows two definitions from the function func. The definition that takes an argument of type char * is local to main because of the extern statement. Therefore, the definition that takes an argument of type int is hidden, and the first call to func is in error.
For overloaded member functions, different versions of the function can be given different access privileges. They're still considered to be in the scope of the enclosing class and thus are overloaded functions. Consider the following code, in which the member function Deposit is overloaded; one version is public, the other, private.
The intent of this sample is to provide an Account class in which a correct password is required to perform deposits. It's done by using overloading.
The call to Deposit in Account::Deposit calls the private member function. This call is correct because Account::Deposit is a member function, and has access to the private members of the class.
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}
See also
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for